Updated August 31, 2023
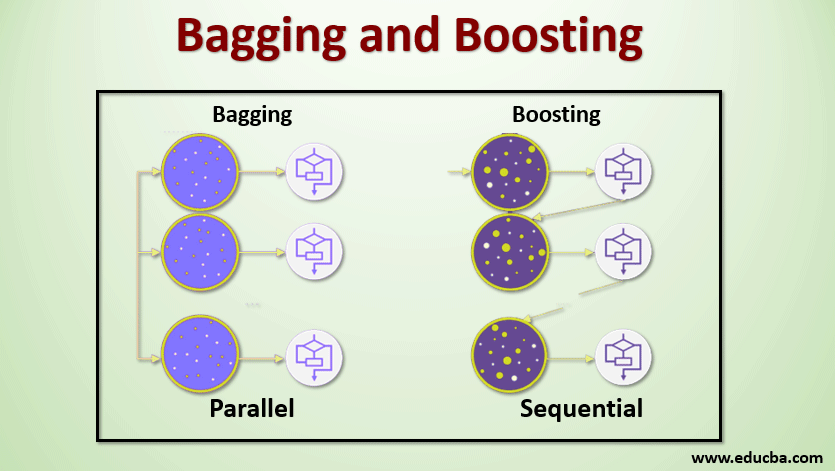
Table of Contents
- Introduction to Bagging and Boosting
- Working on Bagging and Boosting
- Advantages and Disadvantages of Bagging
- Advantages and Disadvantages of Boosting
- Bagging and Boosting: Similarities
- Bagging and Boosting: Differences
- Conclusion
- FAQs
Introduction to Bagging and Boosting
Bagging and Boosting are the two popular Ensemble Methods. So before understanding Bagging and Boosting, let’s have an idea of what is ensemble Learning. It is the technique of using multiple learning algorithms to train models with the same dataset to obtain a prediction in machine learning. After getting the prediction from each model, we will use model averaging techniques like weighted average, variance, or max voting to get the final prediction. This method aims to obtain better predictions than the individual model. This results in better accuracy avoiding overfitting, and reduces bias and co-variance. Two popular ensemble methods are:
- Bagging (Bootstrap Aggregating)
- Boosting
Bagging
Bagging, also known as Bootstrap Aggregating, is used to improve accuracy and make the model more generalized by reducing the variance, i.e., avoiding overfitting. In this, we take multiple subsets of the training dataset. For each subset, we take a model with the same learning algorithms like Decision tree, Logistic regression, etc., to predict the output for the same test data set. Once we predict each model, we use a model averaging technique to get the final prediction output. One of the famous techniques used in Bagging is Random Forest. In the Random forest, we use multiple decision trees.
Boosting
Boosting is primarily used to reduce the bias and variance in a supervised learning technique. It refers to the family of an algorithm that converts weak learners (base learners) to strong learners. The weak learner is the classifiers that are correct only up to a small extent with the actual classification. In contrast, the strong learners are the classifiers that are well correlated with the actual classification. A few famous techniques of Boosting are AdaBoost, GRADIENT BOOSTING, and XgBOOST (Extreme Gradient Boosting). So now we know what bagging and boosting are and their roles in Machine Learning.
Working on Bagging and Boosting
Now let’s understand how bagging and boosting works:
Bagging
To understand the working of Bagging, assume we have an N number of models and a Dataset D. Where m is the number of data and n is the number of features in each data. And we are supposed to do binary classification. First, we will split the dataset. We will split this dataset into training and test set only for now. Let’s call the training dataset, where is the total number of training examples.
Take a sample of records from the training set and use it to train the first model, say m1. For the next model, m2 resamples the training set and takes another sample from the training set. We will do this same thing for the N number of models. Since we are resampling the training dataset and taking the samples from it without removing anything from the dataset, it might be possible that we have two or more training data records common in multiple samples. This technique of resampling the training dataset and providing the sample to the model is termed Row Sampling with Replacement. Suppose we have trained each model and want to see the prediction on test data. Since we are working on binary classification, the output can be 0 or 1. The test dataset is passed to each model, and we get a prediction from each model. Let’s say out of N models, more than N/2 models predicted it to be 1; hence, using the model averaging technique like maximum vote, we can say that the predicted output for the test data is 1.
Implementation Steps of Bagging
Bagging (Bootstrap Aggregating) is an ensemble learning technique that enhances model performance by averaging or voting the predictions of multiple base models trained on different subsets of the training data. Here are the implementation steps in brief:
- Data Preparation: Prepare your dataset with features and labels.
- Data Sampling: Randomly select subsets of the training data with replacement. Each subset should be of the same size as the original dataset.
- Base Model Training: Train the same base model (e.g., decision tree) on each subset created in step 2.
- Predictions: Use the trained base models to predict validation/test set outcomes.
- Aggregation: Aggregate the predictions of all base models. For regression tasks, take the average of the predictions. For classification tasks, use majority voting to determine the final prediction.
- Evaluation: Evaluate the performance of the bagged model using appropriate metrics on the validation/test set.
- Repeat: Steps 2 to 6 can be repeated with a new set of random subsets to create multiple bagged models.
- Final Prediction: If multiple bagged models were created, you can either average or vote their predictions for the final ensemble prediction.
Bagging reduces overfitting and variance by combining diverse models. It’s commonly used with algorithms like Random Forest, which automatically incorporates bagging principles.
Boosting
In boosting, we take records from the dataset and pass them to base learners sequentially; here, base learners can be any model. Suppose we have m number of records in the dataset. Then, we pass a few records to base learner BL1 and train it. Once the BL1 gets trained, then we pass all the records from the dataset and see how the Base learner works. For all the records classified incorrectly by the base learner, we only take them and pass them to other base learners, say BL2, and simultaneously pass the incorrect records classified by BL2 to train BL3. This will go on unless and until we specify some specific number of base learner models we need. Finally, we combine the output from these base learners and create a strong learner; thus, the model’s prediction power improves. Ok. So now we know how the Bagging and Boosting work.
Implementation Steps of Boosting
Boosting is an ensemble learning technique that enhances the predictive performance of models by sequentially training multiple weak learners. Here are the implementation steps in brief:
- Initialize Weights: Assign equal weights to all training data points.
- Train Weak Learner: Train a weak learner (e.g., decision tree) on the training data, giving higher weight to misclassified points.
- Calculate Error: Calculate the weighted error of the weak learner’s predictions.
- Compute Model Weight: Calculate the weak learner’s prediction weight in the final ensemble based on its error rate.
- Update Weights: Adjust the weights of the training samples. Increase weights for misclassified points.
- Repeat: Repeat steps 2-5 for a predefined number of iterations (or until a certain accuracy is achieved).
- Aggregate Predictions: Combine the predictions of all weak learners, weighted by their respective model weights.
- Final Prediction: Generate the final prediction by summing or voting the predictions from step 7.
Popular boosting algorithms include AdaBoost, Gradient Boosting, XGBoost, LightGBM, and CatBoost. Each boosting iteration focuses on correcting previous iterations’ errors, gradually improving the model’s performance. However, monitoring for overfitting is crucial, and choosing appropriate hyperparameters to achieve optimal results.
Advantages and Disadvantages of Bagging
Below given are the advantages and disadvantages as follows.
Advantages of Bagging
- The biggest advantage of bagging is that multiple weak learners can work better than a single strong learner.
- It provides stability and increases the machine learning algorithm’s accuracy, which is used in statistical classification and regression.
- It helps in reducing variance, i.e., it avoids overfitting.
Disadvantages of Bagging
- It may result in high bias if it is not modeled properly and thus may result in underfitting.
- Since we must use multiple models, it becomes computationally expensive and may not be suitable in various use cases.
Advantages and Disadvantages of Boosting
Below given are the advantages and disadvantages as follows.
Advantages of Boosting
- It is one of the most successful techniques in solving the two-class classification problems.
- It is good at handling the missing data.
Disadvantages of Boosting
- Boosting is hard to implement in real time due to the increased complexity of the algorithm.
- The high flexibility of these techniques results in multiple numbers of parameters that directly affect the behavior of the model.
Bagging and Boosting: Similarities
Here’s an outline of the similarities between Bagging and Boosting:
| Aspect | Bagging | Boosting |
| Ensemble Technique | Yes | Yes |
| Base Learner | Weak learners (typically same model) | Weak learners (can be diverse models) |
| Data Sampling | Random sampling with replacement | Weighted sampling with emphasis on errors |
| Parallel Training | Yes (models can be trained in parallel) | No (sequential training of models) |
| Bias-Variance Trade-off | Reduces Variance | Focuses on Reducing Bias |
| Overfitting | Less prone due to averaging | This can lead to overfitting if not controlled |
| Final Prediction | Averaging or Voting of predictions | Weighted combination of predictions |
| Error Correction | No emphasis on correcting errors | Emphasis on correcting errors sequentially |
| Iterations | Independent, no iterative adjustments | Iteratively corrects errors and updates |
Bagging and Boosting: Differences
Here’s an outline of the differences between Bagging and Boosting:
| Aspect | Bagging | Boosting |
| Objective | Reduce variance and increase stability. | Reduce bias and improve accuracy. |
| Base Models | Independent models trained in parallel. | Sequential models correct errors. |
| Data Sampling | Random subsets (with replacement). | Weighted data, focus on misclassified. |
| Model Weights | Uniform weight for each base model. | Adjusted weights based on performance. |
| Iteration Process | No dependence between iterations. | Iterative, each model builds on others. |
| Overfitting Risk | Generally lower due to averaging. | Higher risk due to adaptive learning. |
| Parallel Training | Highly parallelizable. | It may have less parallelization potential. |
| Example Algorithms | Random Forest. | AdaBoost, Gradient Boosting, XGBoost. |
Conclusion
The main takeaway is that Bagging and Boosting are a machine learning paradigm in which we use multiple models to solve the same problem and get a better performance. If we combine weak learners properly, then we can obtain a stable, accurate, and robust model. In this article, I have given a basic overview of Bagging and Boosting. In the upcoming articles, you will get to know the different techniques used in both. Finally, I will conclude by reminding you that Bagging and Boosting are among the most used techniques of ensemble learning. The real art of improving the performance lies in your understanding of when to use which model and how to tune the hyperparameters.
FAQs
Q1. What is better, bagging or boosting?
Answer: Whether Bagging or Boosting is better depends on the specific problem, dataset, and trade-offs you prioritize. Bagging reduces variance and is more stable, making it suitable when overfitting is a concern. Boosting focuses on accuracy but can lead to overfitting due to iterative learning. Choose Bagging for stability and reduced variance and Boosting for potentially higher accuracy, though careful parameter tuning is necessary to avoid overfitting.
Q2. When to use Bagging techniques over Boosting techniques?
Answer: Use Bagging techniques, like Random Forest, to reduce overfitting, improve stability, and build parallelizable models. Bagging is suitable for complex models prone to variance. It creates diverse models by training them independently and averaging predictions. In contrast, Boosting methods, such as AdaBoost or Gradient Boosting, are preferable for improving accuracy by focusing on hard-to-classify instances. Choose Bagging when you want to harness the power of ensemble learning while prioritizing variance reduction.
Recommended Articles
We hope that this EDUCBA information on “Bagging and Boosting” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
