Updated September 16, 2023
Overview of Bias and Variance Machine Learning
As we dredge into the fascinating world of machine learning, we come across two fundamental concepts that refer to the different sources of errors in model predictions: Bias and Variance.
Bias is the difference between the expected or average predictions of a model and the actual value. Conversely, variance refers to how much the model’s prediction varies for different training sets. Bias and variance hold immense significance in determining the accuracy and performance of a machine-learning model. In this article, we will study what Variance and Bias mean in the context of machine learning, how they affect the model’s performance, and why it is essential to understand their trade-offs.
Table of Content
What is Bias in Machine Learning
In machine learning, bias refers to the tendency of a machine learning algorithm to consistently make predictions that are either higher or lower than the actual value. In other words, bias occurs when a model cannot capture the complexity of the underlying data and instead relies on preconceived notions or limited information.
For example, suppose we have a regression problem where we are trying to predict the price of a house based on its features, such as the number of bedrooms, bathrooms, and square footage. Suppose we use a linear regression model that is too simple and only considers the number of bedrooms as a feature. In that case, the model may consistently underestimate or overestimate the actual price, leading to a high bias.
It’s important to note that some bias is inevitable in machine learning models. However, minimizing bias as much as possible can lead to more accurate and fair predictions. Techniques such as regularization can also be used to reduce bias and improve the model’s generalization performance.
There are two types of bias as follows.
- Low Bias: It makes a few assumptions about the specified targeted function.
- High Bias: It is used to make more assumptions compared to low bias but is incapable of handling new data.
What is Variance in Machine Learning
In machine learning, variance measures the sensitivity of the model’s performance to the specific data set used for training. A model with high variance is said to be overfitting the data, meaning it is too complex and has learned to memorize the training data instead of generalizing to new data. This can happen when the model is too flexible or has too many parameters relative to the amount of training data.
On the other hand, a low variance model is too simple and has not learned enough from the training data. This means it may underfit the data and not capture all essential patterns.
For example, suppose we have a regression problem where we are trying to predict the price of a house based on its features, such as the number of bedrooms, bathrooms, and square footage. If we use a polynomial regression model with a very high degree, the model may fit the training data very closely. Still, it may not generalize to new data, leading to high variance.
Reducing variance can improve generalization but may lead to increased bias. Thus, understanding and managing bias-variance trade-offs is essential for building robust machine-learning models that generalize well to new data.
Impact on Model Performance
Here’s how they impact model performance:
- Trade-off: There is typically a trade-off between bias and variance. As you increase the complexity of a model (e.g., adding more features or increasing the depth of a neural network), you can reduce bias but often increase variance.
- Bias-Variance Trade-off: The goal in machine learning is to find the right balance between bias and variance to achieve the best overall model performance. This is often referred to as the bias-variance trade-off.
- Cross-Validation: Techniques like cross-validation can help in assessing and mitigating the impact of bias and variance. Cross-validation involves splitting the data into multiple subsets for training and testing, helping you evaluate how well your model generalizes to new data.
- Regularization: Techniques like L1 and L2 regularization can help reduce variance by adding a penalty term to the model’s parameters, discouraging them from fitting the training data too closely.
- Feature Selection: Proper feature selection can help reduce variance by eliminating irrelevant or noisy features that contribute to overfitting.
- Ensemble Methods: Ensemble methods like Random Forests and Gradient Boosting are effective in reducing variance by combining multiple models to make predictions, there by improving generalization.
Comparison Table Between Bias and Variance Machine Learning
Following is the comparison table Bias and Variance
| Section | Bias | Variance |
| Definition | The difference between the expected value of an estimator and the true value of the parameter being estimated. | The amount of variation in the estimates obtained from different training sets. |
| Impact on model performance | High bias leads to underfitting, where the model does not capture the underlying relationships in the data. | High variance leads to overfitting, where the model is too closely fit to the training data and does not generalize well to new data. |
| Reduce | Reduce the complexity of the model or increase the amount of data. | Increase the amount of data or regularize the model. |
| Leads | Leads to underfitting. | Leads to overfitting. |
| Using | using a more complex model | using a more regularized model. |
What effect does it have on the machine learning model?
Let’s consider the relationship between bias-variance for better understanding.
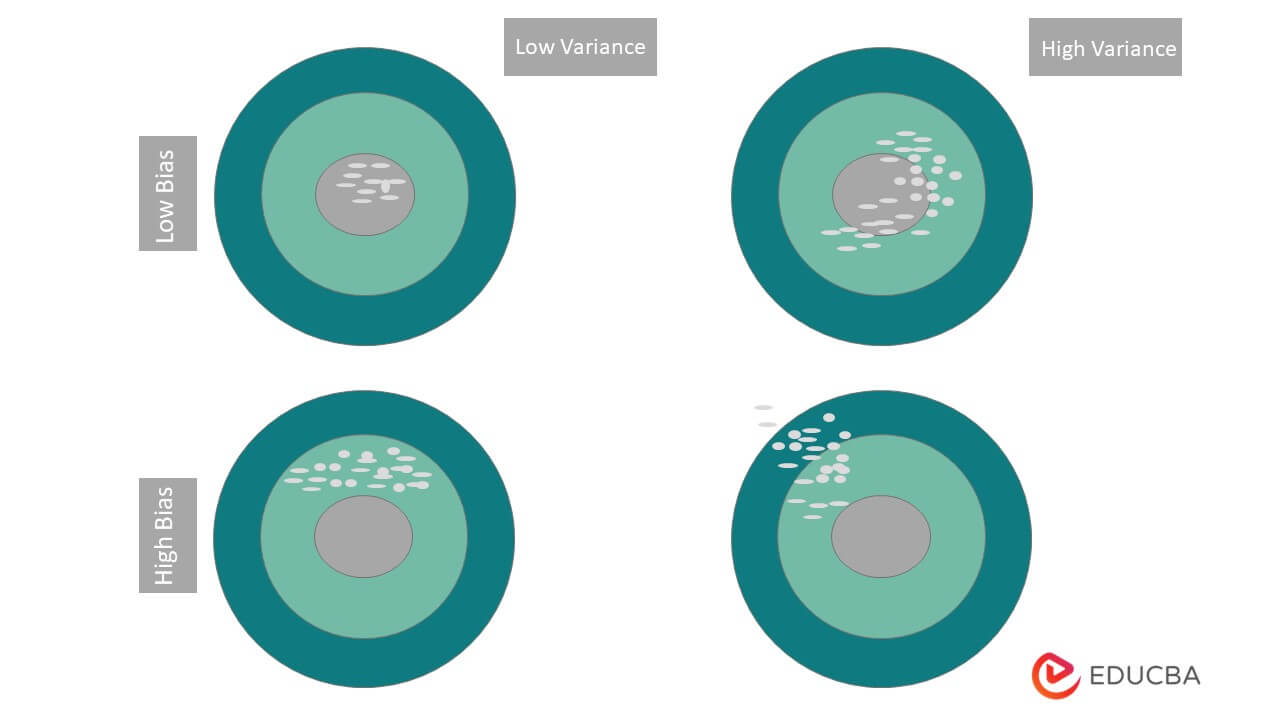
- High Bias and High Variance: It gives the inconsistent result as well as it is not providing accurate results
- High Bias and Low Variance: It provides a consistent result, but on average, it is low.
- Low Bias and High Variance: This model provides an accurate result compared to the above two, but the average of this model is inconsistent.
- Low Bias and Low Variance: This is the most consistent case because it provides a consistent result, and the average is too good.
Below the diagram, we can see a graphical view of the above four relationships.
Even though distinguishing predisposition and change in a model is very obvious, a model with a high difference will have a common preparation blunder and high approval mistake. Also, because of high predisposition, the model will have big preparation mistakes, and an approval blunder is equivalent to a preparing blunder. Based on the overview, it helps to reduce the real-time task if we have the following things as follows.
- We need to add more input features while working.
- We need to reduce the complexity when implementing the polynomial features.
- It reduces the regularization of terms
- It provides more training data.
Understanding Bias and Variance Trade-off
Finding the proper harmony between the inclination and fluctuation of the model is known as the Predisposition Difference compromise. Regardless, it is essentially a method for ensuring the model is neither overfitted nor under fitted.
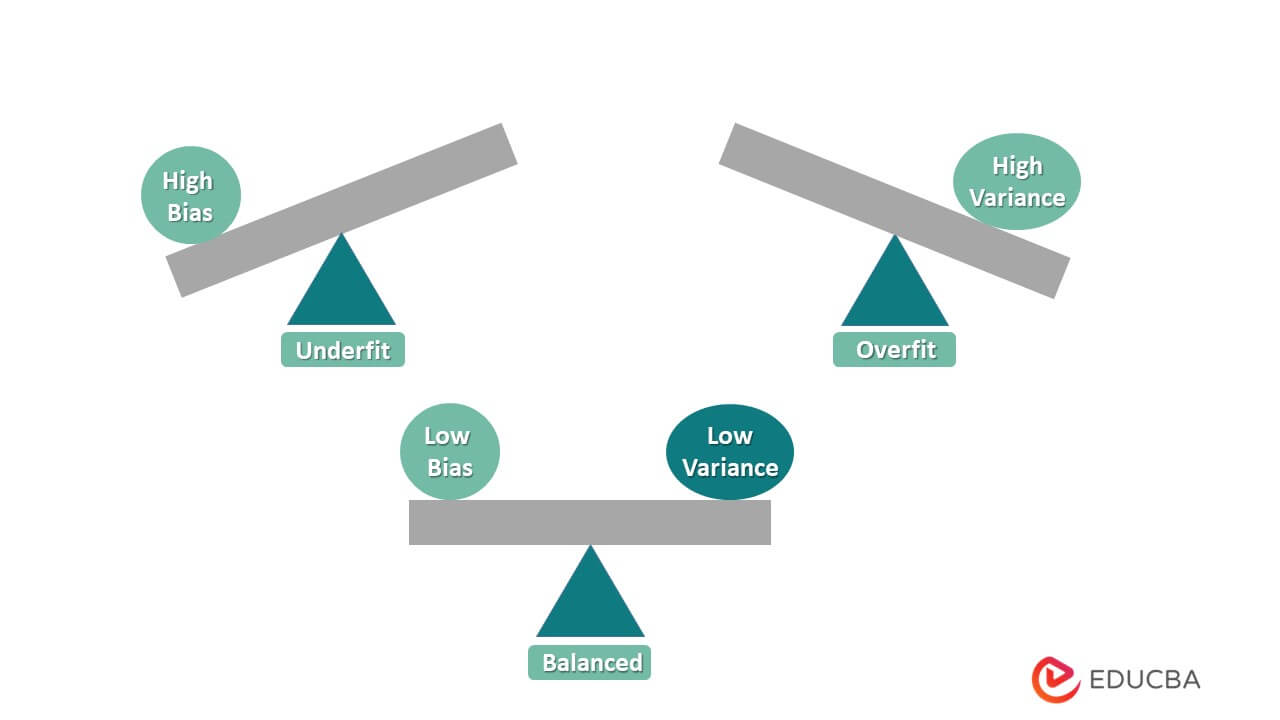
A simple model with few boundaries may suffer from high bias and low variance. Then again, if the model has countless boundaries, it will have high differences and low predispositions. This compromise ought to bring about an impeccably adjusted connection between the two. In a perfect world, low predisposition and low change is the objective of any AI model. As shown in the diagram below.
What is the importance of Bias and Variance?
We know that machine learning algorithms use mathematical and statistical models with two types of error: reducible and irreducible. Unchangeable or irreducible error is because of normal changeability inside a framework.
The importance of bias and variance lies in finding a balance between them. A good machine learning model should have low bias and low variance, which means it accurately captures relevant patterns in the data without overfitting or underfitting. Achieving this balance requires careful tuning of hyperparameters, selecting appropriate features, and choosing a suitable algorithm.
Conclusion
Finally, by controlling Bias and Variance, we can improve the interpretability of a machine learning model, meaning we can gain insights into the underlying patterns in the data and how they relate to the output variable. The ability to interpret and explain a model’s predictions or decisions can be crucial in various real-world applications.
Recommended Articles
We hope that this EDUCBA information on “Bias and Variance” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
