Updated March 8, 2023

Difference Between Random Forest vs Decision Tree
The following article provides an outline for Random Forest vs Decision Tree. Random forest is a kind of ensemble classifier which is using a decision tree algorithm in a randomized fashion and in a randomized way, which means it is consisting of different decision trees of different sizes and shapes, it is a machine learning technique that solves the regression and classification problems, whereas, the decision tree is a supervised machine learning algorithm which is used to solve regression and classification problems, it is like a tree-structure with decision nodes, which consisting two or more branches and leaf nodes, which represents a decision, and the top node is the root node.
Head to Head Comparison Between Random Forest vs Decision Tree (Infographics)
Below are the top 10 differences between Random Forest vs Decision Tree:
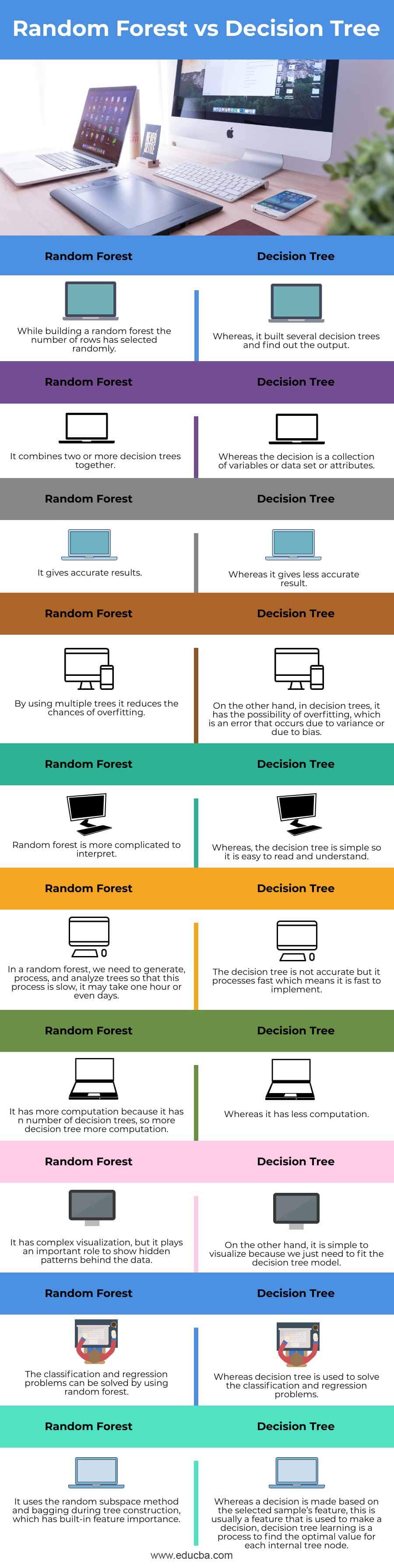
Key Difference between Random Forest vs Decision Tree
Let us discuss some of the major key differences between Random Forest vs Decision Tree:
- Data Processing: The random forest is the combination of multiple decision trees which is the class of dataset, some decision trees out of it may give the correct output and others may not give it correctly, but all trees together predict a correct output, whereas the decision trees use an algorithm to decide node and sub-nodes, a node can be split into two or more sub-nodes, by creating sub-nodes it gives another homogeneous sub-nodes, we can say that the nodes have been increases with respect to the target value. The split is done with the highest information that will be taken in the first place, also the process has been continued until all the children nodes have consistent data.
- Complexity: The decision tree is a simple series of decisions made to get the specific results, it is used for both classification and regression. The advantage of the simple decision tree is that this model is easy to interpret and while building decision trees we aware of which variable and what is the value of the variable is using to split the data, and due to that the output will be predicted fast, on the other hand, the random forest is more complex as there is a combination of decision trees while building a random forest we have to define the number of trees we want to build and how many variables we need at each node.
- Accuracy: Random forest predicts more accurate results than the decision trees. It is the supervised learning algorithm in machine learning that it uses the bagging method so that there is a combination of learning models which increases the accuracy of results, we can also say that random forests build up many decision trees and that combines together which gives a stable and accurate result, when we are using an algorithm to solve the regression problem in a random forest there is a formula to get an accurate result for each node, whereas the accuracy in the decision tree depends on the number of the correct prediction made divided by total numbers of predictions, as it uses large value attribute at each node, it gives less accurate results decision tree is greedy and it may be deterministic, so if we add one more row or if we take out any row then they give different results.
- Overfitting: Overfitting is the critical issue in machine learning, when we use algorithms then there is a risk of overfitting which can be considered as a general bottleneck in machine learning. Overfitting happens when the models learn fluctuation data in the training data which impacted a negative performance on the new data model, when machine learning model cannot fill well on unseen dataset then that is a sign of overfitting if this error is found on the testing or validation dataset is much for the error on the training dataset.
The decision tree has more possibility of overfitting whereas random forest reduces the risk of it because it uses multiple decision trees.
When we using a decision tree model on a given dataset the accuracy going improving because it has more splits so that we can easily overfit the data and validates it.
Random Forest vs Decision Tree Comparison Table
Let’s discuss the top comparison between Random Forest vs Decision Tree:
| Sr. No | Random Forest | Decision Tree |
| 1. | While building a random forest the number of rows are selected randomly. | Whereas, it built several decision trees and find out the output. |
| 2. | It combines two or more decision trees together. | Whereas the decision is a collection of variables or data set or attributes. |
| 3. | It gives accurate results. | Whereas it gives less accurate results. |
| 4. | By using multiple trees it reduces the chances of overfitting. | On the other hand, decision trees, it has the possibility of overfitting, which is an error that occurs due to variance or due to bias. |
| 5. | Random forest is more complicated to interpret. | Whereas, the decision tree is simple so it is easy to read and understand. |
| 6. | In a random forest, we need to generate, process, and analyze trees so that this process is slow, it may take one hour or even days. | The decision tree is not accurate but it processes fast which means it is fast to implement. |
| 7. | It has more computation because it has n number of decision trees, so more decision trees more computation. | Whereas it has less computation. |
| 8. | It has complex visualization, but it plays an important role to show hidden patterns behind the data. | On the other hand, it is simple to visualize because we just need to fit the decision tree model. |
| 9. | The classification and regression problems can be solved by using random forest. | Whereas a decision tree is used to solve the classification and regression problems. |
| 10. | It uses the random subspace method and bagging during tree construction, which has built-in feature importance. | Whereas a decision is made based on the selected sample’s feature, this is usually a feature that is used to make a decision, decision tree learning is a process to find the optimal value for each internal tree node. |
Conclusion
In this article, we have seen the difference between the random forest and the decision trees, in which decision tree is a graph structure which uses branching method and it provides result in every possible way whereas, random forest combines a decision trees its result depends on all its decision trees.
Recommended Articles
This is a guide to Random Forest vs Decision Tree. Here we discuss key differences with infographics and comparison table respectively. You may also have a look at the following articles to learn more –
