Updated March 21, 2023
Introduction to Ensemble Techniques
Ensemble learning is a technique in machine learning which takes the help of several base models and combines their output to produce an optimized model. This type of machine learning algorithm helps in improving the overall performance of the model. Here the base model which is most commonly used is the Decision tree classifier. A decision tree basically works on several rules and provides a predictive output, where the rules are the nodes and their decisions will be their children and the leaf nodes will constitute the ultimate decision. As shown in the example of a decision tree.
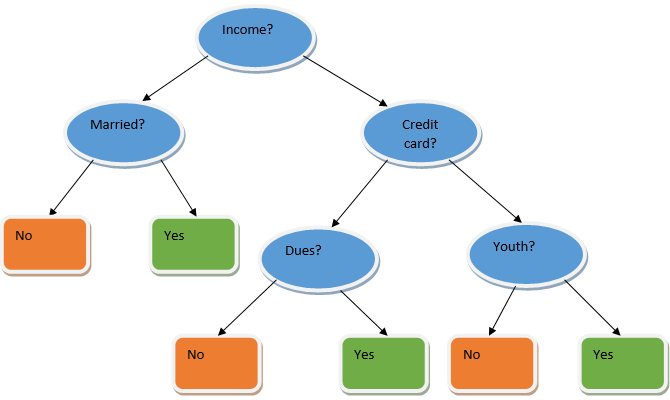
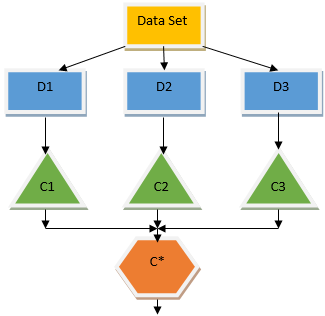
The above decision tree basically talks about whether a person/customer can be given a loan or not. One of the rules for loan eligibility yes is that if (income = Yes && Married = No) Then Loan = Yes so this is how a decision tree classifier works. We will be incorporating these classifiers as a multiple base model and combine their output to build one optimum predictive model. Figure 1.b shows the overall picture of an ensemble learning algorithm.
Types of Ensembles Techniques
Different types of ensembles, but our major focus will be on the below two types:
- Bagging
- Boosting
These methods help in reducing the variance and bias in a machine learning model. Now let us try to understand what is bias and variance. Bias is an error that occurs due to incorrect assumptions in our algorithm; a high bias indicates our model is too simple/underfit. Variance is the error that is caused due to sensitivity of the model to very small fluctuations in the data set; a high variance indicates our model is highly complex/overfit. An ideal ML model should have a proper balance between bias and variance.
Bootstrap Aggregating/Bagging
Bagging is an ensemble technique that helps in reducing variance in our model and hence avoids overfitting. Bagging is an example of the parallel learning algorithm. Bagging works based on two principles.
- Bootstrapping: From the original data set, different sample populations are considered with replacement.
- Aggregating: Averaging out the results of all the classifiers and providing single output, for this, it uses majority voting in the case of classification and averaging in the case of the regression problem. One of the famous machine learning algorithms which use the concept of bagging is a random forest.
Random Forest
In random forest from the random sample withdrawn from the population with replacement and a subset of features is selected from the set of all the features a decision tree is built. From these subsets of features whichever feature gives the best split is selected as the root for the decision tree. The features subset must be chosen randomly at any cost otherwise we will end up producing only correlated tress and the variance of the model will not be improved.
Now we have built our model with the samples taken from the population, the question is how do we validate the model? Since we are considering the samples with replacement hence all the samples will not be considered and some of it will not be included in any bag these are called out of bag samples. We can validate our model with this OOB (out of bag) samples. The important parameters to be considered in a random forest is the number of samples and the number of trees. Let us consider ‘m’ as the subset of features and ‘p’ is the full set of features, now as a thumb rule, it’s always ideal to choose
- m as√and a minimum node size as 1 for a classification problem.
- m as P/3 and minimum node size to be 5 for a regression problem.
The m and p should be treated as tuning parameters when we deal with a practical problem. The training can be terminated once the OOB error stabilizes. One drawback of the random forest is that when we have 100 features in our data set and only a couple of features are important then this algorithm will perform poorly.
Boosting
Boosting is a sequential learning algorithm that helps in reducing bias in our model and variance in some cases of supervised learning. It also helps in converting weak learners into strong learners. Boosting works on the principle of placing the weak learners sequentially and it assigns a weight to each data point after every round; more weight is assigned to the misclassified data point in the previous round. This sequential weighted method of training our data set is the key difference to that of bagging.
Fig3.a shows the general approach in boosting
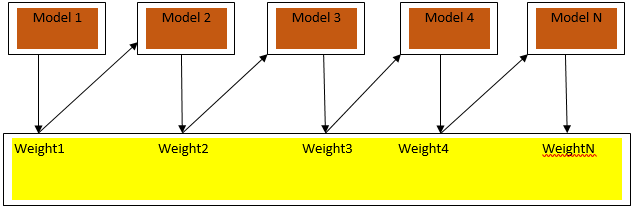
The final predictions are combined based on weighted majority voting in the case of classification and weighted sum in the case of regression. The most widely used boosting algorithm is adaptive boosting (Adaboost).
Adaptive Boosting
The steps involved in the Adaboost algorithm is as follows:
- For the given n data points we define the target classy and initialize all the weights to 1/n.
- We fit the classifiers to the data set and we choose the classification with the least weighted classification error
- We assign weights for the classifier by a thumb rule based on accuracy, if the accuracy is more than 50% then the weight is positive and vice versa.
- We update the weights of the classifiers at the end of iteration; we update more weight for the misclassified point so that in the next iteration we classify it correctly.
- After all the iteration we get the final prediction result based on the majority voting/weighted average.
Adaboosting works efficiently with weak (less complex) learners and with high bias classifiers. The major advantages of Adaboosting are that it is fast, there are no tuning parameters similar to the case of bagging and we don’t do any assumptions on weak learners. This technique fails to provide an accurate result when
- There are more outliers in our data.
- The data set is insufficient.
- The weak learners are highly complex.
They are susceptible to noise as well. The decision trees that are produced as a result of boosting will have limited depth and high accuracy.
Conclusion
Ensemble learning techniques are widely used in improving the model accuracy; we have to decide on which technique to use based on our data set. But these techniques are not preferred in some cases where interpretability is of importance, as we lose interpretability at the cost of performance improvement. These have tremendous significance in the health care industry where a small improvement in performance is very valuable.
Recommended Articles
This is a guide to Ensemble Techniques. Here we discuss the basic concept and two major types of Ensemble Techniques with detail explanation. You can also go through our other related articles to learn more –
