Updated March 8, 2023
Difference between Gradient boosting vs AdaBoost
Adaboost and gradient boosting are types of ensemble techniques applied in machine learning to enhance the efficacy of week learners. The concept of boosting algorithm is to crack predictors successively, where every subsequent model tries to fix the flaws of its predecessor. Boosting combines many simple models into a single composite one. By attempting many simple techniques, the entire model becomes a strong one, and the combined simple models are called week learners. So the adaptive boosting and gradient boosting increases the efficacies of these simple model to bring out a massive performance in the machine learning algorithm.
Head to Head Comparison Between Gradient boosting vs AdaBoost (Infographics)
Below are the top differences between Gradient boosting vs AdaBoost:
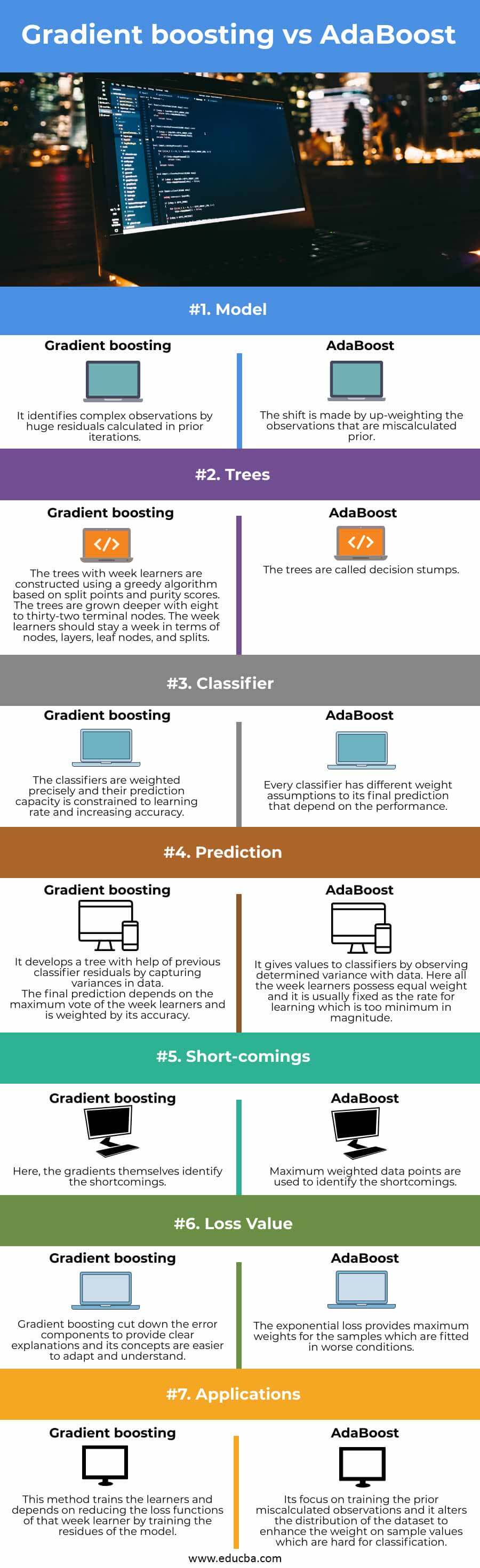
Key differences of Gradient boosting and AdaBoost
The important differences between gradient boosting are discussed in the below section.
Definition:
Adaboost increases the performance of all the available machine learning algorithms and it is used to deal with weak learners. It gains accuracy just above the arbitrary chances of classifying the problem. The adaptable and most used algorithm in AdaBoost is decision trees with a single level. The gradient boosting depends on the intuition which is the next suitable possible model, when get combined with prior models that minimize the cumulative predicted errors. The crucial idea of gradient boosting is to fix the targeted outcomes for the next model to reduce the error.
Principle:
The first boosting ensemble model is adaptive boosting which modifies its parameters to the values of the data that depend on the original performance of the current iteration. Both weights for re-computing the value of data and its weights for the final combination are re-manipulated iteratively again. Here it is employed in simple classification trees as base learned which provides increased performance when compared to classification single base-learner or one tree algorithm. Gradient boosting combines boosting and gradient descent ideas to form a strong machine learning algorithm. The term, “gradient” denotes to have double or multiple derivatives of a similar function. The weak learner, loss function, and additive model are three components of gradient boosting. It provides direct analysis of boosting techniques from the view of numerical optimization in a function that generalizes them enabling the optimization of the random loss function.
Loss function
A loss function is measured to compute the performance of the predicted model to its expected value or outcomes. The user changes the learning problem to an optimization function that describes the loss function and again tunes the algorithm to reduce the loss function to get more accuracy. The adaptive boosting method minimizes the exponential loss function which changes the algorithm more profound to its outliers. In gradient boosting, the differentiable loss function makes more sensitive to outliers when compared to AdaBoost.
Tractability:
Adaboost is computed with a specific loss function and becomes more rigid when comes to few iterations. But in gradient boosting, it assists in finding the proper solution to additional iteration modeling problem as it is built with some generic features. From this, it is noted that gradient boosting is more flexible when compared to AdaBoost because of its fixed loss function values.
Advantages:
Adaboost is effective when it’s implied in week learners and when it is related to few classification errors it reduces the loss function. It was developed for problems that require binary classification and can be used to improve the efficiency of decision trees. In gradient boosting, it is used to crack the problems with differential loss functions. It can be implied in both regression problems and classification issues. Though there are a few differences in these two boosting techniques, both follow a similar path and have the same historic roots. Both boost the performance of a single learner by persistently shifting the attention towards problematic remarks which are challenging to compute and predict.
Disadvantages:
The existing week learners can be found in gradient boosting and in Adaboost it can find the maximum weightage data points.
Comparison Table of Adaboost and Gradient Boosting
| Features | Gradient boosting | Adaboost |
| Model | It identifies complex observations by huge residuals calculated in prior iterations | The shift is made by up-weighting the observations that are miscalculated prior |
| Trees | The trees with week learners are constructed using a greedy algorithm based on split points and purity scores. The trees are grown deeper with eight to thirty-two terminal nodes. The week learners should stay a week in terms of nodes, layers, leaf nodes, and splits | The trees are called decision stumps. |
| Classifier | The classifiers are weighted precisely and their prediction capacity is constrained to learning rate and increasing accuracy | Every classifier has different weight assumptions to its final prediction that depend on the performance. |
| Prediction | It develops a tree with help of previous classifier residuals by capturing variances in data.
The final prediction depends on the maximum vote of the week learners and is weighted by its accuracy.
|
It gives values to classifiers by observing determined variance with data. Here all the week learners possess equal weight and it is usually fixed as the rate for learning which is too minimum in magnitude. |
| Short-comings | Here, the gradients themselves identify the shortcomings. | Maximum weighted data points are used to identify the shortcomings. |
| Loss value |
Gradient boosting cut down the error components to provide clear explanations and its concepts are easier to adapt and understand
|
The exponential loss provides maximum weights for the samples which are fitted in worse conditions.
|
| Applications | This method trains the learners and depends on reducing the loss functions of that week learner by training the residues of the model | Its focus on training the prior miscalculated observations and it alters the distribution of the dataset to enhance the weight on sample values which are hard for classification |
Conclusion
So, when it comes to Adaptive boosting the approach is done by up-lifting the weighted observation which is misclassified prior and used to train the model to give more efficacy. In gradient boosting, the complex observations are computed by large residues left on the previous iteration to increase the performance of the existing model.
Recommended Articles
This is a guide to Gradient boosting vs AdaBoost. Here we discuss the Gradient boosting vs AdaBoost key differences with infographics and a comparison table. You may also have a look at the following articles to learn more –
