What is Knowledge Discovery and Data Mining?
Discovery and Data Mining, often referred to as KDD (Knowledge Discovery in Databases), is a fascinating interdisciplinary field that involves extracting useful and previously unknown knowledge from large datasets. Discovery involves uncovering hidden patterns, relationships, and insights within a dataset. It is exploratory and often used for hypothesis generation and pattern recognition. On the other hand, data mining is a systematic approach that employs various algorithms to extract valuable knowledge, such as associations, classifications, and clustering, from large datasets. Both approaches play crucial roles in deriving meaningful information from data, making informed decisions, and gaining a competitive edge in today’s data-driven world. This article provides the core concepts and techniques in Discovery and Data Mining.
Table of Contents
What is Discovery?
KDD (Knowledge Discovery in Databases), in the context of data analysis, is a systematic and exploratory process to reveal hidden patterns, insights, and relationships within a dataset. It involves the comprehensive examination of data without predefined expectations, focusing on uncovering valuable information that might take time to be apparent. Techniques in discovery often include data visualization, exploratory data analysis, and identifying trends and anomalies. Discovery is particularly useful for hypothesis generation, making data-driven decisions, and gaining a deeper understanding of complex data, contributing to better-informed actions and strategies.
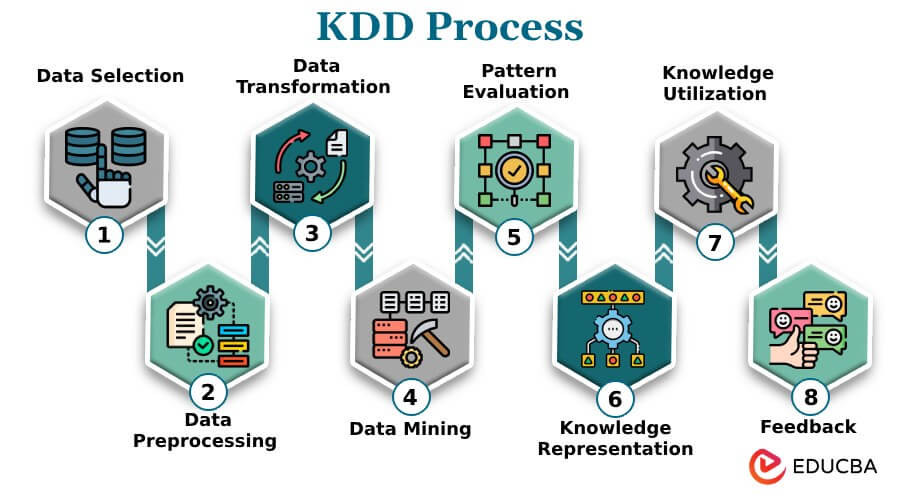
Here’s an overview of the typical KDD process:
- Data Selection: The process begins with selecting and retrieving the relevant data from various sources. This step involves choosing the dataset that contains the information you want to analyze and extract knowledge from.
- Data Preprocessing: Data preprocessing is a critical step that includes data cleaning, integration, transformation, and reduction. It aims to ensure that the data is high quality and suitable for analysis. This may involve handling missing values, removing duplicates, and converting data into a standard format.
- Data Transformation: In this step, data is transformed into a more suitable format for the analysis. This can include normalization (scaling data to a standard range), encoding categorical variables, and reducing dimensionality.
- Data Mining: This is the core of the KDD process, where various data mining techniques are applied to discover patterns, associations, correlations, and other valuable insights from the preprocessed data. Standard data mining techniques include clustering, classification, regression, and association rule mining.
- Pattern Evaluation: Once patterns are discovered through data mining, they must be evaluated for their significance and relevance. This involves assessing the quality and reliability of the patterns to determine if they are useful for decision-making.
- Knowledge Representation: Extracted patterns and insights are then represented in a form that can be easily understood and interpreted. This might include visualization, graphs, or other visual aids to convey the information to stakeholders.
- Knowledge Utilization: The knowledge obtained from the data is put into practice. This step involves using the discovered patterns and insights to make informed decisions, solve problems, or support various applications. It can have a direct impact on business processes, scientific research, and other domains.
- Feedback: The KDD process is often iterative, and feedback is essential. It’s important to assess the results and gather feedback from users and stakeholders. This feedback can lead to refining the process and revisiting the data selection, preprocessing, and mining stages to improve the overall knowledge discovery process.
Use Cases and Applications of Discovery
Discovery is frequently utilized in many industries to identify insights and patterns in data. Some major use cases and applications of discovery include:
- Healthcare: Identifying trends in patient data to improve treatment protocols and predict disease outbreaks.
- Marketing: Analyzing customer behavior to optimize marketing strategies and personalize recommendations.
- Finance: Detecting fraudulent transactions and predicting market trends for investment decisions.
- Environmental Science: Studying climate data to understand climate change and extreme weather patterns.
- Manufacturing: Quality control and process optimization by uncovering defects and inefficiencies.
- Social Sciences: Analyzing survey data to reveal societal trends and preferences.
- Astrophysics: Identifying celestial phenomena and patterns in astronomical data.
- Retail: Inventory management and demand forecasting to optimize supply chain operations.
- Education: Analyzing student performance data to enhance teaching methods and interventions.
- Security: Recognizing anomalies in network traffic for cybersecurity and threat detection.
What is Data Mining?
Data mining is discovering hidden patterns, relationships, and valuable insights within large datasets. Various algorithms, statistical techniques, and machine learning methods extract valuable insights from data. Data mining aims to uncover trends, associations, and patterns that may not be apparent through traditional data analysis methods. This extracted knowledge can be used for making informed decisions, predicting future trends, and solving complex problems in diverse fields such as business, healthcare, finance, and more. Data mining plays a crucial role in harnessing the power of big data and transforming raw information into actionable intelligence.
Key Characteristics of Data Mining
Data mining has the following key characteristics:
- Data Exploration: Data mining involves exploring and analyzing large datasets to extract hidden patterns and insights.
- Predictive Analysis: It aims to make predictions or identify trends based on historical data, allowing for informed decision-making.
- Automated Process: Data mining often employs automated algorithms to analyze and uncover patterns, reducing the need for manual data examination.
- Broad Applicability: Data mining applies to various domains, including finance, marketing, healthcare, and more, making it versatile.
- Pattern Recognition: It focuses on identifying patterns, associations, correlations, and anomalies within data.
- Machine Learning: Data mining frequently involves using machine learning algorithms to make predictions and classifications.
- Large Datasets: Data mining is well-suited for handling and analyzing extensive datasets, including big data.
- Business Intelligence: It is critical in extracting valuable business insights and improving decision support systems.
- Decision Support: Data mining aids in decision-making by providing actionable information for businesses and organizations.
- Continuous Learning: It can adapt to changing data patterns and trends, allowing for ongoing analysis and decision support.
Data Mining Techniques and Algorithms
Data mining techniques and algorithms are tools for extracting insights and information from massive databases. Among the most important approaches and algorithms are:
- Association Rule Mining: Identifying relationships between variables, often used for market basket analysis.
- Classification: Categorizing data into predefined classes or groups, such as spam detection and disease diagnosis.
- Clustering: Grouping similar data points based on features is helpful for customer segmentation and anomaly detection.
- Regression Analysis: Predicting numerical values based on relationships within the data for sales forecasting and trend analysis.
- Decision Trees: Hierarchical structures that help make decisions and classifications, like in product recommendation systems.
- Neural Networks: Modeling complex relationships by simulating the human brain’s learning process, applicable in image and speech recognition.
- Support Vector Machines: Identifying decision boundaries for classification tasks, used in text classification and image recognition.
- Principal Component Analysis (PCA): Reducing dimensionality while preserving data variation essential for feature selection and visualization.
- Time Series Analysis: Analyzing data points collected over time to identify trends, patterns, and seasonal effects, often used in financial forecasting.
- Natural Language Processing (NLP): Techniques for processing and analyzing textual data used in sentiment analysis and chatbots.
Use Cases and Applications of Data Mining
Data mining is a process with a variety of applications in different industries. Some key use cases include:
- Business: Enhancing customer segmentation, sales forecasting, and market basket analysis for improved marketing and decision-making.
- Healthcare: Predicting disease outbreaks, diagnosing medical conditions, and optimizing patient care.
- Finance: Detecting fraud, credit risk assessment, and stock market trend prediction.
- Retail: Recommender systems for product recommendations and inventory management.
- Manufacturing: Predictive maintenance, process optimization, and quality control.
- Telecommunications: Churn prediction and network optimization.
- Social Media: Analyzing user behavior for content recommendations and sentiment analysis.
- Agriculture: Crop yield prediction and pest management.
- Security: Identifying anomalies in network traffic for cybersecurity and threat detection.
- Education: Identifying student performance trends and improving educational outcomes.
Key Differences Between Discovery and Data Mining
The comparison table below highlights the key differences between Discovery and Data mining:
| Basis of Comparison | Discovery | Data Mining |
| Primary Objective | Exploration and pattern identification | Knowledge extraction and prediction |
| Predefined Hypotheses | Not typically reliant on predefined hypotheses | Often based on predefined hypotheses |
| Data Examination | Broad exploration of data without preconceptions | Focused on specific questions and patterns |
| Process Focus | Emphasizes the process of uncovering insights | Focuses on extracting knowledge |
| Techniques | EDA, pattern recognition, hypothesis generation | Association rule mining, classification, clustering |
| Data Types | Varied data types, including unstructured data | Structured data, often from databases |
| Data Volume | May work with smaller or larger datasets | Well-suited for large datasets and big data |
| Subjectivity | Interpretation and context-dependent insights | More objective with predefined goals |
| Skill Sets | Data analysts, domain experts | Data scientists, machine learning experts |
| Real-time Analysis | Suitable for real-time analysis and decision-making | Typically requires batch processing |
| Use Cases | Hypothesis generation, open-ended exploration | Predictive analytics, classification, recommendation |
Choosing the Right Approach between Discovery and Data Mining
When choosing between discovery and data mining, it’s crucial to consider your unique objectives and data characteristics:
Choose Discovery when:
- You want to explore data without predefined hypotheses.
- Your goal is to uncover hidden patterns and generate hypotheses.
- Data is diverse, unstructured, or doesn’t fit predefined models.
- You seek a broad understanding of the dataset.
Choose Data Mining when:
- You have specific questions or predefined objectives.
- The focus is on prediction, classification, or knowledge extraction.
- Data is well-structured, and you need to apply algorithms.
- You require actionable, objective results for decision-making.
In many cases, combining discovery and data mining techniques offers comprehensive insights.
Future Trends and Developments
Future trends and developments in the field of data analysis and data mining include:
- Explainable AI: Emphasis on transparent and interpretable AI models for improved decision support and regulatory compliance.
- Automated Machine Learning (AutoML): Streamlining the model-building process to make data mining more accessible to non-experts.
- Big Data Integration: Enhanced tools and techniques to manage and analyze ever-increasing volumes of data.
- Privacy-Preserving Data Mining: Methods to protect individuals’ data privacy while extracting valuable insights.
- Edge Computing: Real-time data analysis at the edge, reducing latency and enabling faster decision-making.
- Industry-Specific Applications: Tailored data mining solutions for sectors like healthcare, finance, and cybersecurity.
- Ethical AI and Fairness: Growing focus on responsible AI practices and mitigating bias in data mining.
Conclusion
Encompassing both discovery and data mining, it plays a pivotal role in our data-driven world. Discovery allows for open-ended exploration, pattern recognition, and hypothesis generation, fostering creativity in problem-solving. On the other hand, data mining provides structured, objective insights, making it invaluable for predictive analytics and decision-making. As technology advances, combining data analysis approaches with ethical considerations will shape the future of informed decision-making across diverse domains.
Recommended Articles
We hope that this EDUCBA information on “Knowledge Discovery and Data Mining” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
