Updated March 23, 2023

Introduction to Data Preprocessing in Machine Learning
The following article provides an outline for Data Preprocessing in Machine Learning. Data pre-processing also knows as data wrangling is the technique of transforming the raw data i.e. an incomplete, inconsistent, data with lots of error, and data that lack certain behavior, into understandable format carefully using the different steps (i.e. from importing libraries, data to checking of missing values, categorical followed by validation and feature scaling ) so that proper interpretations can be made from it and negative results can be avoided, as the quality of the model in machine learning highly depends upon the quality of data we train it on.
Data collected for training the model is from various sources. These collected data are generally in their raw format i.e. they can have noises like missing values, and relevant information, numbers in the string format, etc. or they can be unstructured. Data pre-processing increases the efficiency and accuracy of the machine learning models. As it helps in removing these noises from and dataset and giving meaning to the dataset
Six Different Steps Involved in Machine Learning
Following are six different steps involved in machine learning to perform data pre-processing:
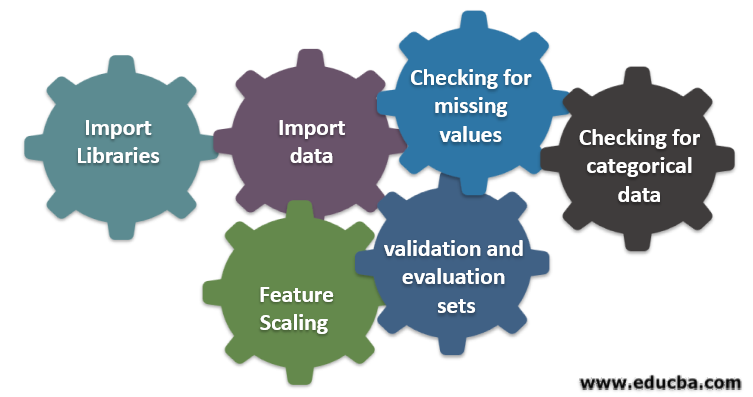
Step 1: Import libraries
Step 2: Import data
Step 3: Checking for missing values
Step 4: Checking for categorical data
Step 5: Feature scaling
Step 6: Splitting data into training, validation and evaluation sets
1. Import Libraries
The very first step is to import a few of the important libraries required in data pre-processing. A library is a collection of modules that can be called and used. In python, we have a lot of libraries that are helpful in data pre-processing.
A few of the following important libraries in python are:
- Numpy: Mostly used the library for implementing or using complicated mathematical computation of machine learning. It is useful in performing an operation on multidimensional arrays.
- Pandas: It is an open-source library that provides high performance, and easy-to-use data structure and data analysis tools in python. It is designed in a way to make working with relation and labeled data easy and intuitive.
- Matplotlib: It’s a visualization library provided by python for 2D plots o array. It is built on a numpy array and designed to work with a broader Scipy stack. Visualization of datasets is helpful in the scenario where large data is available. Plots available in matplot lib are line, bar, scatter, histogram, etc.
- Seaborn: It is also a visualization library given by python. It provides a high-level interface for drawing attractive and informative statistical graphs.
2. Import Dataset
Once the libraries are imported, our next step is to load the collected data. Pandas library is used to import these datasets. Mostly the datasets are available in CSV formats as they are low in size which makes it fast for processing. So, to load a csv file using the read_csv function of the panda’s library. Various other formats of the dataset that can be seen are
Once the dataset is loaded, we have to inspect it and look for any noise. To do so we have to create a feature matrix X and an observation vector Y with respect to X.
3. Checking for Missing Values
Once you create the feature matrix you might find there are some missing values. If we won’t handle it then it may cause a problem at the time of training.
There are two methods of handling the missing values:
- Removing the entire row that contains the missing value, but there can be a possibility that you may end up losing some vital information. This can be a good approach if the size of the dataset is large.
- If a numerical column has a missing value then you can estimate the value by taking the mean, median, mode, etc.
4. Checking for Categorical Data
Data in the dataset has to be in a numerical form so as to perform computation on it. Since Machine learning models contain complex mathematical computation, we can’t feed them a non-numerical value. So, it is important to convert all the text values into numerical values. LabelEncoder() class of learned is used to covert these categorical values into numerical values.
5. Feature Scaling
The values of the raw data vary extremely and it may result in biased training of the model or may end up increasing the computational cost. So it is important to normalize them. Feature scaling is a technique that is used to bring the data value in a shorter range.
Methods used for feature scaling are:
- Rescaling (min-max normalization)
- Mean normalization
- Standardization (Z-score Normalization)
- Scaling to unit length
6. Splitting Data into Training, Validation and Evaluation Sets
Finally, we need to split our data into three different sets, training set to train the model, validation set to validate the accuracy of our model and finally test set to test the performance of our model on generic data. Before splitting the Dataset, it is important to shuffle the Dataset to avoid any biases. An ideal proportion to divide the Dataset is 60:20:20 i.e. 60% as the training set, 20% as test and validation set. To split the Dataset use train_test_split of sklearn.model_selection twice. Once to split the dataset into train and validation set and then to split the remaining train dataset into train and test set.
Conclusion – Data Preprocessing in Machine Learning
Data Preprocessing is something that requires practice. It is not like a simple data structure in which you learn and apply directly to solve a problem. To get good knowledge on how to clean a Dataset or how to visualize your dataset, you need to work with different datasets. The more you will use these techniques the better understanding you will get about it. This was a general idea of how data processing plays an important role in machine learning. Along with that, we have also seen the steps needed for data pre-processing. So next time before going to train the model using the collected data be sure to apply data pre-processing.
Recommended Articles
This is a guide to Data Preprocessing in Machine Learning. Here we discuss the introduction and six different steps involved in machine learning. You can also go through our other suggested articles to learn more –
