Updated April 4, 2023

How to Install Spark: Introduction
The following article describes in detail how to install Spark on the system.
Spark is an open-source framework for running analytics applications. It is a data processing engine hosted by the vendor-independent Apache Software Foundation and is designed to work with large data sets or big data. Spark is a general-purpose cluster computing system that provides high-level APIs in Scala, Python, Java, and R. It was developed to overcome the limitations of the MapReduce paradigm in Hadoop. Data scientists believe that Spark executes 100 times faster than MapReduce because it can cache data in memory, whereas MapReduce works primarily by reading and writing to disks. It performs in-memory processing, making it more powerful and fast.
Spark does not have its own file system. Instead, it processes data from diverse data sources, such as Hadoop Distributed File System (HDFS), Amazon’s S3 system, Apache Cassandra, MongoDB, Alluxio, and Apache Hive. It can run on Hadoop YARN (Yet Another Resource Negotiator), on Mesos, on EC2, on Kubernetes, or using standalone cluster mode. It uses RDDs (Resilient Distributed Dataset) to delegate workloads to individual nodes that support iterative applications. Due to RDD, programming is easier in comparison to Hadoop.
Spark Ecosystem Components
- Spark Core: It is the foundation of a Spark application on which other components directly depend. It provides a platform for a wide variety of applications such as scheduling, distributed task dispatching, in-memory processing, and data referencing.
- Spark Streaming: It is the component that works on live streaming data to provide real-time analytics. The live data is ingested into discrete units called batches, which are executed on the Spark Core.
- Spark SQL: It is the component that works on top of the Spark Core to run SQL queries on structured or semi-structured data. Data Frames are the way to interact with Spark SQL.
- GraphX: It is the graph computation engine or framework that allows processing graph data. It provides various graph algorithms to run on Spark.
- MLlib: It contains machine learning algorithms that provide a machine learning framework in a memory-based distributed environment. It performs iterative algorithms efficiently due to the in-memory data processing capability.
- SparkR: Spark provides an R package to run or analyze datasets using the R shell.
Three ways to deploy/install Spark
- Standalone Mode in Apache Spark
- Hadoop YARN/Mesos
- SIMR(Spark in MapReduce)
Let’s see the deployment in Standalone mode.
1. Spark Standalone Mode of Deployment
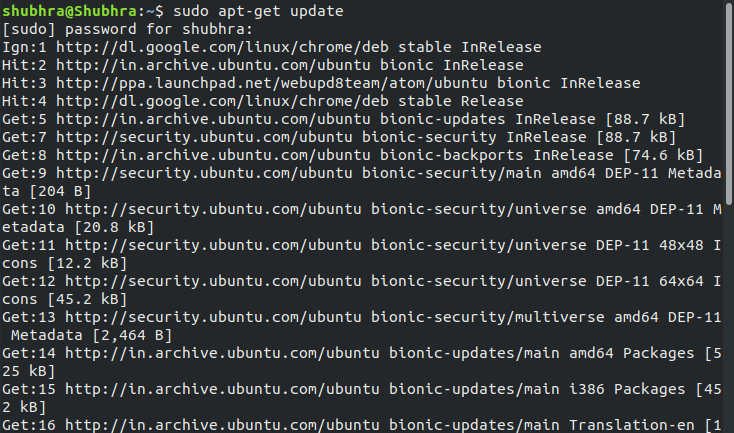
Step #1: Update the package index
This is necessary to update all the present packages in the machine.
Use command:
$ sudo apt-get update
Step #2: Install Java Development Kit (JDK)
It will install JDK in the machine and would help run Java applications.

Step #3: Check if Java is installed properly
Java is a prerequisite for using Apache Spark Applications.
Use command:
$ java –version
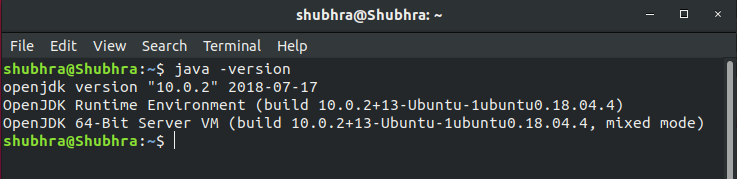
The above image shows the Java version and assures the presence of Java on the machine.
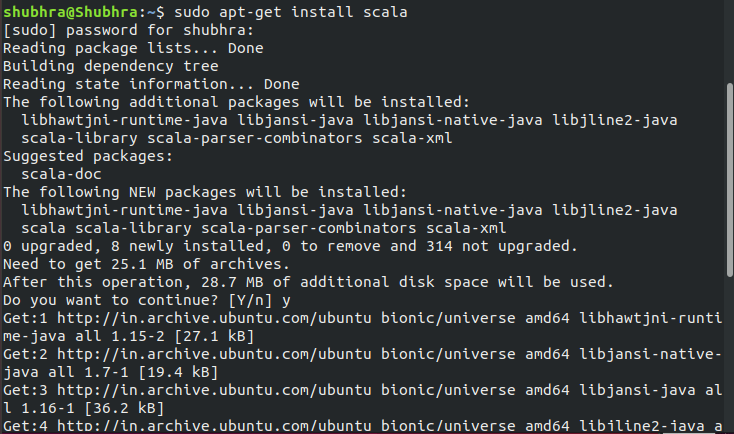
Step #4: Install Scala on your machine
As Spark is written in Scala, the latter must be installed to run Spark on the machine.
Use Command:
$ sudo apt-get install scala
Step #5: Verify if Scala is properly installed
This ensures the successful installation of Scala on the system.
Use Command:
$ scala –version</code
![]()
Step #6: Download Apache Spark
Download Apache Spark as per the Hadoop version from https://spark.apache.org/downloads.html
Upon opening the above link, a window will appear:
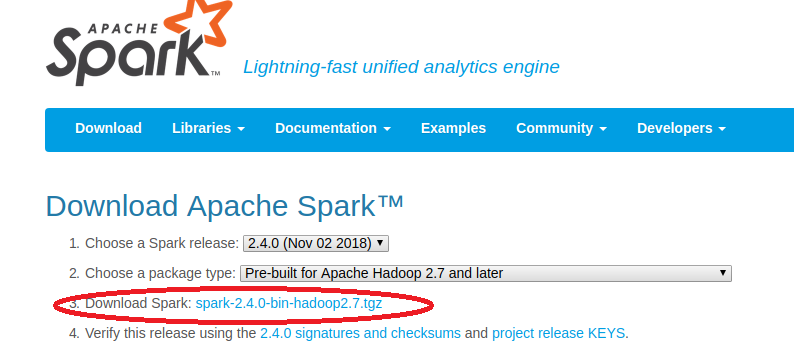
Step #7: Select the relevant version as per the Hadoop version and click on the link marked.
Now, another window would appear:
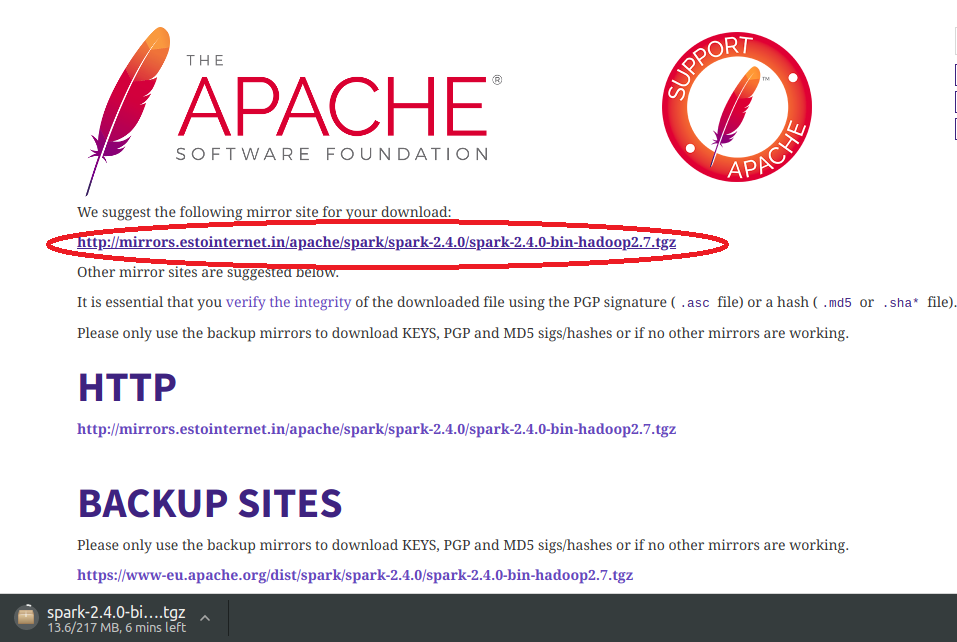
Step #8: Click on the marked link and Apache Spark would download in your system.
Verify if the .tar.gz file is available in the ‘Downloads’ folder.
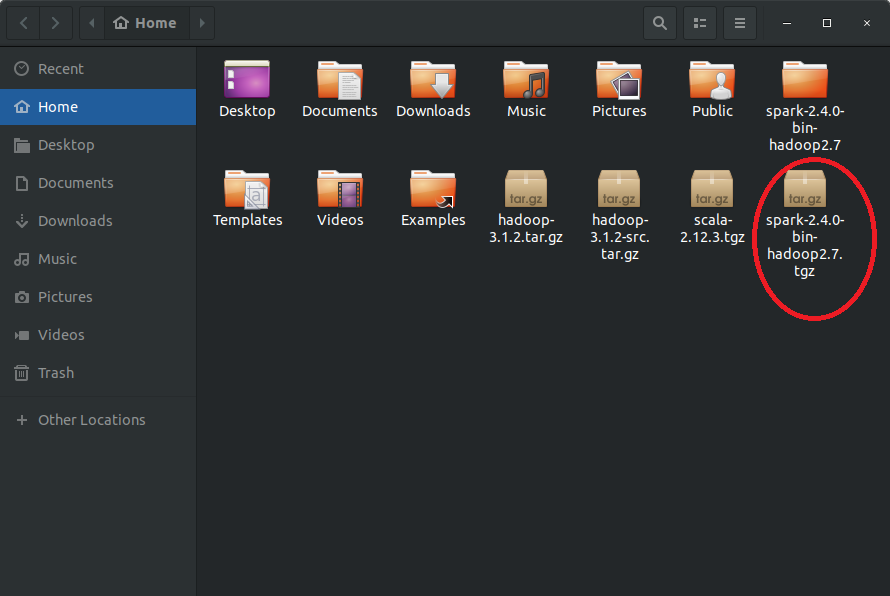
Step #9: Install Apache Spark
Extract the tar file in order to install Spark.
Use Command:
$ tar xvf spark- 2.4.0-bin-hadoop2.7.tgz

Change the version mentioned in the command according to the downloaded version. Here, the downloaded version is spark-2.4.0-bin-hadoop2.7.
Step #10: Setup environment variable for Apache Spark
Use Command:
$ source ~/.bashrc
Add line: export PATH=$PATH:/usr/local/spark/bin
![]()
Step #11: Verify the installation of Apache Spark
Use Command:
$spark-shell
If the installation is successful, then the following output will be produced.
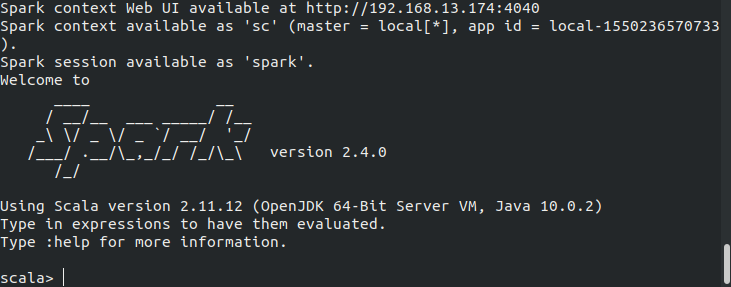
This indicates the successful installation of Apache Spark on the machine. Now, Apache Spark will start in Scala.
2. Deployment of Spark on Hadoop YARN
There are two modes to deploy Apache Spark on Hadoop YARN:
- Cluster mode: In this mode, YARN on the cluster manages the Spark driver that runs inside an application master process. Once the application is initiated, the client can leave.
- Client mode: In this mode, the application master requests resources from YARN, and the Spark driver runs in the client process.
To deploy a Spark application in cluster mode, use the following command:
$spark-submit –master yarn –deploy –mode cluster mySparkApp.jar
This command will start a YARN client program, which will initiate the default Application Master.
To deploy a Spark application in client mode, use the following command:
$ spark-submit –master yarn –deploy –mode client mySparkApp.jar
One can run spark-shell in client mode using the following command:
$ spark-shell –master yarn –deploy-mode client
Tips and Tricks
- Before installing Spark, ensure that Java is installed on your machine.
- If you plan to use the Scala language with Apache Spark, ensure that Scala is also installed on your machine.
- Python can also be used for programming with Spark, but it must also be pre-installed like Scala.
- While Apache Spark can run on Windows, it is of high recommendation to create a virtual machine and install Ubuntu using Oracle Virtual Box or VMWare Player.
- Spark can run in standalone mode without Hadoop, but if a multi-node setup is required, resource managers like YARN or Mesos are needed.
- When using YARN, it is not necessary to install Spark on all three nodes. One only needs to install Apache Spark on one node.
- When using YARN, one can use client mode if one is on the same local network with the cluster, and cluster mode if one is far away.
Recommended Articles
Here are some further related articles for expanding understanding:
