Updated June 15, 2023

Introduction to Spark Interview Questions and Answers
The following article provides an outline for Spark Interview Questions. Apache Spark is an open-source framework. Spark, as it is an open-source platform, we can use multiple programming languages such as Java, Python, Scala, R. As compared to Map-Reduce process performance, spark helps improve execution performance. It also provides 100 times faster in-memory execution than MapReduce. Because of the Processing power of sparks nowadays, industries are preferring sparks.
So you have finally found your dream job in Spark but are wondering how to crack the Spark Interview and what could be the probable Spark Interview Questions for 2023. Every interview is different, and the job scope is different too. Keeping this in mind, we have designed the most common Spark Interview Questions and Answers for 2023 to help you get success in your interview.
Part 1 – Spark Interview Questions (Basic)
This first part covers basic Spark interview questions and answers:
Q1. What is Spark?
Answer:
Apache Spark is an open-source framework. It improves execution performance than the Map-Reduce process. It’s an open platform where we can use multiple programming languages like Java, Python, Scala, and R . Spark provides in-memory execution, which is 100 times faster than Map-Reduce.
It uses the concept of RDD. RDD is a resilient distributed dataset that allows it to transparently store data on memory and persist it to disc only if it’s needed. This is where it will reduce the time to access the data from memory instead of Disk. Today’s Industry prefers Spark because of its processing power.
Q2. What is the difference Between Hadoop and Spark?
Answer:
| Feature Criteria | Apache Spark | Hadoop |
| Speed | 10 to 100 times faster than Hadoop. | Normal speed. |
| Processing | Real-time & Batch processing, In-memory, Caching. | Batch processing only, Disk Dependent. |
| Difficulty | Easy because of the high-level modules. | Difficult to learn. |
| Recovery | Allows recovery of partitions using RDD. | Fault-tolerant. |
| Interactivity | Has interactive modes. | No interactive mode except Pig & Hive, No iterative mode. |
Normal Hadoop architecture follows basic Map-Reduce; for the same process, spark provides in-memory execution. Instead of read-write from the hard drive for Map-Reduce, spark provides read-write from virtual memory.
Q3. What are the Features of Spark?
Answer:
- Provide integration facility with Hadoop and Files on HDFS. Spark can run on top of Hadoop using YARN resource clustering. Spark can replace Hadoop’s Map-Reduce engine.
- Polyglot: Spark Provides high-level API for Java, Python, Scala, and R. Spark Code can be written in any of these four languages. It provides an independent shell for scale (the language in which Spark is written) and a Python interpreter. Which will help to interact with the spark engine? Scala shell can be accessed through ./bin/spark-shell and Python shell through ./bin/pyspark from the installed directory.
- Speed: Spark engine is 100 times faster than Hadoop Map-Reduce for large-scale data processing. Speed will be achieved through partitioning for parallelizing distributed data processing with minimal network traffic. Spark provides RDDs (Resilient Distributed Datasets), which can be cached across computing nodes in a cluster.
- Multiple Formats: Spark has a data source API. It will provide a mechanism to access structured data through spark SQL. Data Sources can be anything, Spark will just create a mechanism to convert the data and pull it to the spark. Spark supports multiple data sources like Hive, HBase, Cassandra, JSON, Parquet, and ORC.
- Spark provides some inbuilt libraries to perform multiple tasks from the same core, like batch processing, Steaming, Machine learning, and Interactive SQL queries. However, Hadoop only supports batch processing. Spark Provides MLIb (Machine learning libraries ), which will be helpful for Big-Data Developers to process the data. This helps to remove dependencies on multiple tools for different purposes. Spark provides a powerful common platform to data engineers and data scientists with both fast performance and ease to use.
- Apache Spark delays the process execution until the action is necessary. This is one of the key features of Spark. Spark will add each transformation to DAG (Direct Acyclic Graph) for execution, and when the action wants to execute, it will trigger the DAG to process.
- Real-Time Streaming: Apache Spark Provides real-time computations and low latency, Because of in-memory execution. Spark is designed for large scalabilities like a thousand nodes of the cluster and several models for computations.
Q4. What is YARN?
Answer:
These is the basic Spark Interview Questions asked in an interview. YARN (Yet Another Resource Negotiator) is the Resource manager. Spark is a platform that provides fast execution. Spark will use YARN for the execution of the job to the cluster rather than its own built-in manager. There are some configurations to run Yarn. They include master, deploy-mode, driver-memory, executor-memory, executor-cores, and queue. There are common Spark Interview Questions that are asked in an interview; below are the advantages of Spark:
Advantages of Spark over Map-Reduce:
Spark has advantages over Map-Reduce as follows:
- Because of the ability of the In-memory process, Spark can execute 10 to 100 times faster than Map-Reduce.
- Apache Spark provides a high level of inbuilt libraries to process multiple tasks at the same time as batch processing, Real-time streaming, Spark-SQL, Structured Streaming, MLib, etc. Same time Hadoop provides only batch processing.
- The Hadoop Map-Reduce process will be disk-dependent, where Spark provides Caching and In-Memory.
- Spark has both iterative, which performs computation multiple on the same dataset, and interactive, which performs computation between different datasets, whereas Hadoop doesn’t support iterative computation.
Q5. Which is the language supported by Spark?
Answer:
Spark supports Scala, Python, R, and Java. In the market, big data developer mostly prefers Scala and python. For a scale to compile the code, we need to Set the Path of the scale/bin directory or make a jar file.
Q6. What is RDD?
Answer:
RDD is an abstraction of a Resilient Distributed Dataset, which provides a collection of elements partitioned across all nodes of the cluster which will help to execute multiple processes in parallel. Using RDD developer can store the data In-Memory or caching to be reused efficiently for parallel execution of operations. RDD can be recovered easily from node failure.
Part 2 – Spark Interview Questions (Advanced)
Let us now have a look at the advanced Spark Interview Questions:
Q7. What are the factors responsible for the execution of Spark?
Answer:
- Spark provides in-memory execution instead of disk-dependent like Hadoop Map-Reduce.
- RDD Resilient Distributed Dataset, which is a responsible parallel execution of multiple operations on all nodes of a cluster.
- Spark provides a shared variable feature for parallel execution. These variables help to reduce data transfer between nodes and share a copy of all nodes. There are two variables.
- Broadcast Variable: This variable can be used to cache a value in memory on all nodes.
- Accumulators Variable: This variable is only “added” to, such as counters and sums.
Q8. What is Executor Memory?
Answer:
Each Spark application has one executor for each worker node. This property refers to how much memory of the worker nodes will be allocated for an application.
Q9. How do you use Spark Stream? Explain One use case?
Answer:
Spark Stream is one of the features that are useful for a real-time use case. We can use Flume, and Kafka with a spark for this purpose. Flume will trigger the data from a source. Kafka will persist the data into Topic. From Kafka, Spark will pull the data using the stream, and it will D-stream the data and perform the transformation.
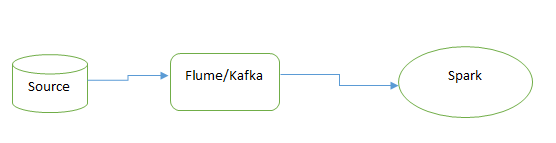
We can use this process for real-time suspicious transactions, real-time offers, etc.
Q10. Can we use Spark for the ETL process?
Answer:
Yes, We can use a spark platform for the ETL process.
Q11. What is Spark SQL?
Answer:
It is one special component of the spark that will support SQL queries.
Q12. What Lazy Evaluation?
Answer:
When we are working with a spark, Transformations are not evaluated until you perform an action. This helps optimize the overall data processing workflow. When defining transformation, it will add to the DAG (Direct Acyclic Graph). And at auction time, it will start to execute stepwise transformations.
Recommended Articles
We hope that this EDUCBA information on “Spark Interview Questions” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
