Introduction to Career in Hadoop
Hadoop is not a mere framework in the Big Data world. It has a wide ecosystem with an umbrella of related technologies. For the same reason, a career in Hadoop is promising. If you have a good understanding of Hadoop fundamentals, it will be a foundation for a great career in Hadoop.
Education Required for Career in Hadoop
Like many emerging data technologies, Hadoop doesn’t demand any specific educational background as such. Around half of Hadoop developers are from non-computer science backgrounds like Statistics or Physics. So it is clear that the background is not a hindrance to entering the world of Hadoop, provided you are ready to learn fundamentals. There are good online courses cover Hadoop – the one from eduCBA is the best example – master-Apache-Hadoop
Further, if you want to move deeper into a specific area of Hadoop cluster management or data modeling in Hive materials on each specific topic available as online courses and textbooks, most of the time, Hadoop clusters will be set up in a cloud vendor like AWS or Azure. So getting familiar with any cloud vendor you choose will help a lot. The Hadoop service from AWS is called EMR.
The popular specialization includes :
- Spark – Scalable in-memory data processing engine
- HBase – No SQL Database on top of HDFS
- Beam – Streaming first approach data processing
- Pig – Data transformation(ETL) scripting
- Hive – Data warehousing
- Mahout, Spark MLlib – Scalable Machine Learning on Hadoop
- Apache Drill – SQL engine on Hadoop
- Flume, Sqoop – Data Ingesting Services
- Solr & Lucene – Searching & Indexing
Career Path in Hadoop
As per Stack Overflow Survey 2017 results, Hadoop is leading in the most popular and most loved framework in the Big Data space (Survey Link). This is possible only because people from different IT perspectives found Hadoop a potential career path and want to switch.
Whatever your current role is in IT, there will be an easily adaptable switch to a career in the Hadoop world. Some popular examples –
- Software Developer(Programmer): Hadoop Data Developer who deals with different Hadoop abstraction SDKs and derives value from data.
- Data Analyst: So you are proficient in SQL.Huge opportunity in Hadoop to work on SQL engines like Hive or Impala
- Business Analyst: Organisations are trying to become more profitable using massively collected data and a business analyst role is crucial in this.
- ETL Developer: If you are working as a traditional ETL developer, you can easily shift to Hadoop ETL using Spark tools.
- Testers: There is a huge demand for testers in the Hadoop world. By understanding the fundamentals of Hadoop and data profiling, any testers can switch to this role.
- BI/DW professions: Can easily switch from Hadoop Data architecting to Data modeling.
- Senior IT professionals: With a deep understanding of the domain and existing challenges in the data world, senior professionals can become consultants by learning how Hadoop is trying to solve these challenges.
- There are generic roles like Data Engineers or Big Data Engineering, which is responsible for implementing solutions mostly on top of Cloud vendors. Gaining knowledge of the data components the cloud provides will be a promising role.
Job Positions
The Hadoop ecosystem offers a variety of career paths.
- MapReduce Developer: This basically a Java developer role who also understands how Hadoop systems work internally. There is an abstraction like Hive or Pig available. Still, MapReduce jobs are necessary for high-performing systems. MapReduce developers are the one who understands a system in and out and pays really high.
- Hadoop Administrators: These are people responsible for keeping the Hadoop cluster healthy and performing. This may include typical Hadoop administrator tasks like regular system health checks, but most tasks are needed to understand Hadoop system architecture.
- Devops: Deploy new system components and other development-related changes in the Hadoop cluster. The responsibility of this role varies a lot and depends on the culture of an organization.
- Data Developer: Data processing on top of Hadoop. This is one of the most popular roles in the Hadoop ecosystem. People from SQL or analytics backgrounds are best fit for these roles. Mostly work on a high-level abstraction of Hadoop like Hive or Pig.
- Data security admin: Data is the most valuable asset, and securing it is most important. Security admins ensure industry-standard policies and best practices to protect data, understanding a system’s limitations.
- Data Visualizer: Handle next-generation visualization tools which allow dynamic data slicing and aggregation with in-memory data caching
- ETL Developer: Transform data for data quality improvement or as per business logic using Hadoop ecosystem tools. ETL process might be streaming or batch.
- System Architect: Design high-performing systems cost-effectively, considering data availability and durability. Depends heavily on the Hardware provider.
- Data Architect: Apart from the traditional Logical/Physical design of data, many things like column encoding, denormalization, partitioning design, etc. will be the responsibility of the data architect.
Salary
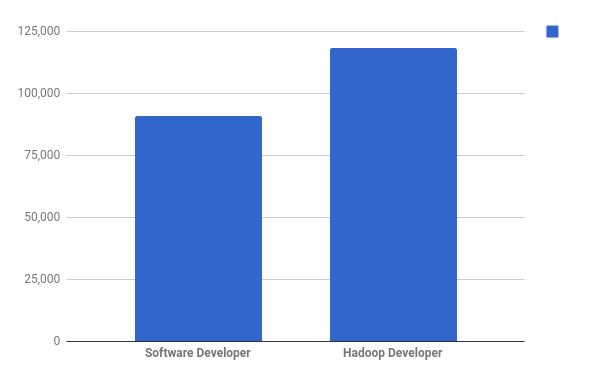
An average salary of a Software developer in the US is $98,618 per year, while the average salary of a Hadoop developer is way higher – $118,234 per year ( As per Indeed.com 2023 – indeed.com )
Salaries of Hadoop developers in top companies in the US 2023 (Ref: indeed.com)
| eBay | $146 per hour |
| Stefanini IT Solution | $127 per hour |
| Barclays | $114 per hour |
| X by 2 | $109 per hour |
| Informatica | $106per hour |
| Prutech Solutions | $104 per hour |
| Emonics | $103 per hour |
| HCSC | $81.93 per hour |
| APLOMB Technologies | $63.81 per hour |
| Silverlink Technologies Pvt Ltd | $52.08 per hour |
Career Outlook
Hadoop ecosystem is getting diverged a lot to meet a change in business needs. As data generated is increasing exponentially and more and more organizations become data-driven, the Hadoop system’s relevance will only increase.
Some of the notable trends :
- Shift from batch processing to stream first data processing approach using Spark and Beam
- More real-time Machine Learning models applied to real-time data using Spark ML.
- Decoupled SQL engines from data storage like Presto on top of S3 for ad-hoc analysis on top of the data lake.
- Columnar MPP databases like AWS Redshift for quick data access
As a fundamental aspect of Big Data processing lies on fault-tolerant distributed and horizontally scalable systems, which Hadoop well implements, Hadoop will continue as a leading ecosystem for data processing.
Recommended Articles
This has been a guide to Career in Hadoop. Here we have discussed the introduction, education, and skills required along with job position, salary, and career outlook in Hadoop. You may also look at the following article to learn more –
