Updated March 20, 2023
Overview of AWS RedShift
Amazon Redshift is a service by AWS that provides a fully managed and scaled for petabyte warehousing with an enterprise-class relational database management system that supports client connections with many types of applications, including reporting, analytical tools, and enhanced business intelligence (BI) application where you can query large amounts of data in multiple-stage operations to produce final result and all these at very efficient storage and optimum query performance through a massively parallel processing and query execution.
It provides many functionalities that make thing easier for us; in this topic, we are going to learn about What is AWS Redshift and some of the technologies of AWS Redshift, which are given below:-
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
One of the major services provided by AWS and we are going to deal with is Amazon RedShift. So, what is this RedShift, what is it used for, these are the basic questions that come over our mind whenever we read this. so let us check in detail what redshift is and what is it used for. RedShift is an enterprise-level, petabyte-scale and fully managed data warehousing service.
So, what is a Data Warehouse? The answer for resides in its own if we know what a warehouse is general terms; generally a warehouse is a place where raw materials or manufactured goods may be stored prior to their distribution for sale, the same holds for Data also data warehouse is a place for collecting, storing, and managing data from various sources and provide the relevant and meaningful business insights. So Amazon provides an enterprise-level warehousing tool where we can process and manage data with REDSHIFT. The Range for these datasets varies from 100s of gigabytes to a petabyte.
Reasons for Using AWS RedShift
So We often encounter a general question that before this AWS Tool, where was this warehouse, where did we do all these data processing, storing, and manufacturing. So earlier, when data load was quite normal, we use to have physical servers, databases that were used to keep track of data and their processing, but as there was an exponential increase in the size of data, querying and handling of data became a tough task as the queries started taking a long time as expected.
So here we came across the need for amazon redshift that was much faster with very high performance and scalability for storing and manufacturing Data. It came with massive storage capacity and transparent pricing and was secured from various data breaches. Supporting SQL interfaces and various driver ODBC/JDBC, it is quite easy to use and well merged with other Amazon services.
Working
Now let’s see the architecture diagram of Redshift and will try to understand how RedShift actually Works –
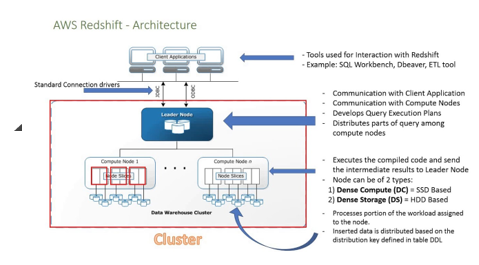
- The following diagram depicts the working of Amazon RedShift. Let’s check that over detail: –
- For connection with the client application, we have several drivers that connect with Redshift.
- Within Redshift, we can create more than one cluster, and each cluster can host multiple databases.
- The nodes are divided into Slices, each slice having data.
- From the nodes available, if we have more than one node is selected as Leader, that will be the major source for the client to communicate for. The Client application will talk only with the leader node; the leader node is responsible for receiving queries and commands from the client program.
- Once the leader node starts getting the queries performed by the client, it starts parsing the query and building a plan to make it run on other compute nodes. Once the process is distributed to the concerning nodes, it waits for the final result from the nodes before returning it to the Client.
- We can add the number of nodes and also can increase the memory as a load of data increases.
- The compute nodes have a separate network that the client doesn’t have access making it secure too.
- There are Two Types of Nodes: Dense storage nodes and Dense Compute Nodes; the storage capacity can range from 160GB to 16TB
So here we saw the basic architecture of how REDSHIFT works. Now let us move to how to Use for Aws Redshift.
Using AWS RedShift
For working with AWS Redshift, we need to perform some basic steps mentioned below: –
1) Sign in to AWS and make an account over there. (If not)
2) Go to the Amazon Redshift console from the following link:-
https://console.aws.amazon.com/redshift/
3) Now, we need to create an I AM Role; we need to navigate to the below link:-
https://console.aws.amazon.com/iam/
- Go to Roles
- Choose to create Roles.
- Choose Redshift in the AWS Service
- Choose Redshift – Customizable then Next: Permissions under select your use case.
- Set permission boundary
- Type a name for your Role
- Review and create Role.
4) Now, we need to create a cluster by selecting a region menu there in the console.
- Select the region where the cluster is created.
- Click on Launch.
- We need to fill in several details like the Database Name, Password and check the continue button.
- Once the cluster is visible, check that in the list and review the status information.
- Once we have the cluster with us, the next thing we need to do is to set the security group, here we need to set the inbounds rules type protocol source and range.
- Check the required configuration and connect to Redshift Cluster.
5) Once we are done with all the cluster-related configurations, we need to connect now to our Redshift now. We can connect to this Redshift directly or via SSL. To connect it directly, we need to have JDBC /ODBC Drivers, which we have to set over the configuration page of the cluster.
Once these several configurations are done nicely, we are ready to use Redshift.
Advantages
So why will someone use AWS Redshift there must have to be some advantage over other services that makes this special. So let us now check some of the advantages of using Redshift.
- High Speed:- The Processing time for the query is comparatively faster than the other data processing tools, and data visualization has a much clear picture.
- Bulk Data Processing:- Be larger; the data size redshift can process huge amounts of data in ample time.
- Minimal Data Loss:- Since data are distributed over the cluster and processed parallelly over the network, there is a minimum chance for data loss, and well the accuracy rate for the processed data is better.
- Cost-Effective:- Being cost-effective, it is cheaper than any other alternatives available that make it strong over the industry usage. Since the pricing is less, we can accommodate large amounts of data and can process them within budget.
- SQL Interface: The Query engine based for Redshift is the same as for Postgres SQL, making it easier for SQL developers to play with it.
- Security:- The data inside Redshift is Encrypted that is available at multiple places in RedShift. Also, we can define the inbound and outbound rule that makes the data much secure.
There are a lot more advantages to having redshift as a better choice for the data warehouse.
AWS RedShift Pricing
RedShift comes with an amazing price listing that attracts developers or the market towards it. Since it comes with an on-demand pricing feature, we can use it just over an hourly basis and the number of nodes in our cluster. Spectrum Pricing helps us to run SQL Queries directly against all our data.
We can create large data warehouses using HDD for a very low price. For more details over the exact pricing details, you can refer to the doc below by Amazon:-
https://aws.amazon.com/redshift/pricing/
The Document above has all the details about the various pricing for AWS REDSHIFT.
Conclusion
From the above article we saw for Redshift, we must now have a fair idea about what actually redshift is and its usage. RedShift is so very scalable and easy to use, is most widely adopted by the industry over the support of various other Amazon technologies that make it more powerful. So in a world full of data, Redshift comes with a very good data warehouse and processing package.
Recommended Articles
This is a guide to What is AWS RedShift. Here we discuss a brief overview, working, steps, and advantages of AWS RedShift, respectively. You may also look at the following article to learn more –

