Updated March 2, 2023

Introduction to Hadoop Ecosystem
The following article provides an outline for Hadoop Ecosystem. Apache Hadoop is an open-source system to store and process much information across many commodity computers reliably. Hadoop has been first written in a paper and published in October 2013 as ‘Google File System.’ Doug Cutting, who was working in Yahoo at that time, introduced Hadoop Ecosystem’s name based on his son’s toy elephant name. If we consider the main core of Apache Hadoop, then firstly it can consider the storage part, which is known as Hadoop Distributed File System (HDFS), and secondly processing part, which is known as the Map-Reduce Programming module. This is because Hadoop actually splits one huge file and store them in multiple nodes across the cluster.
Concept of Hadoop Ecosystem
Apache Hadoop framework is mainly holding below modules:
- Hadoop Common: Contains all the libraries and utilities needed for using the Hadoop module.
- Hadoop Distributed File System (HDFS): It is a distributed file system that helps store huge data in multiple or commodity machines. Also, provide a big utility in the case of bandwidth; it normally provides very high bandwidth as a type of aggregate on a cluster.
- Hadoop Yarn: It was introduced in 2012. It is mainly introduced to managing resources on all the systems in commodity, even in a cluster. Based on resource capability, it distributed or scheduling the user’s application as per requirement.
- Hadoop MapReduce: It mainly helps to process large-scale data through map-reduce programming methodology.
Apache Hadoop always helps with IT cost reduction in terms of processing and storing huge data smartly. Moreover, as Apache Hadoop is open-source and hardware is very commonly available, it always helps us handle a proper reduction in IT cost.
Open Source Software + Commodity Hardware = IT Costs Reduction
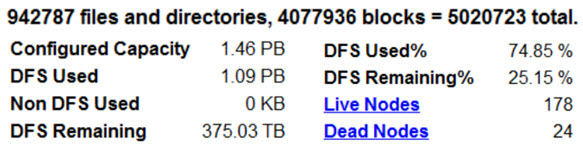
For example, if we consider daily receiving 942787 files and directories, which require 4077936 blocks, a total of 5020723 blocks. So if we configured at least 1.46 PB capacity, then for handling the above load, the distributed file system will use 1.09 PB, that’s mean almost 74.85% of total configured capacity, whereas we are considering 178 live nodes and 24 dead nodes.
Hadoop ecosystem mainly designed for storing and processing big data, which normally have some key characters like below:
- Volume: The volume stands for the size of Data that actually stored and generated. Depends on the size of the data, it has been determined the data set is big data or not.
- Variety: Variety stands for nature, structure, and type of data which is being used.
- Velocity: Velocity stands for the speed of data that has been stored and generated in a particular development process flow.
- Veracity: Veracity signifies the quality of data that has been captured and also helps data analysis to reach the intended target.
HDFS is mainly designed to store a huge amount of information (terabytes or petabytes) across a large number of machines in a cluster. It always maintaining some common characteristics, like data reliability, runs on commodity hardware, using blocks to store a file or part of that file, utilize the ‘write once read many’ model.
HDFS below architecture with the concept of Name Node and Data Node.
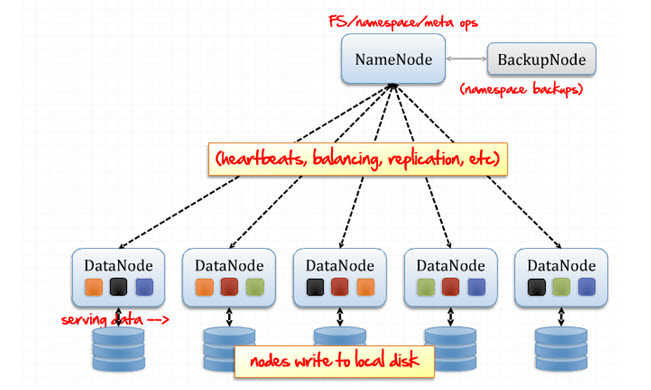
1. The responsibility of the Name Node (Master)
- Manages the file system namespace.
- Maintains cluster configuration.
- Responsible for replication management.
2. The responsibility of Data Node (Slaves)
- Store data in the local file system.
- Periodically report back to the name node using heartbeat.
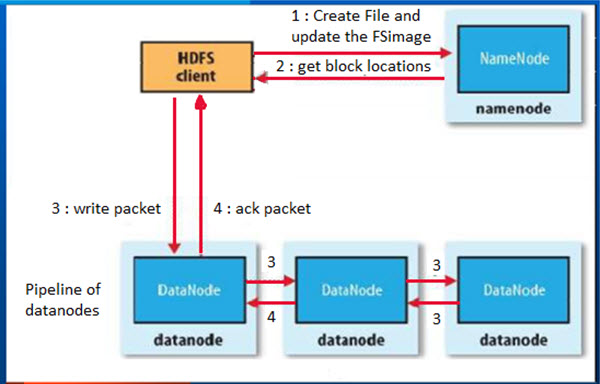
HDFS Write Operation
Hadoop follows the below steps for write any big file:
- First, create File and update the FS image after getting one file write request from any HDFS client.
- Get block location or data node details information from the name node.
- Write the packet in an individual data node parallel way.
- Acknowledge completion or accepting packet writing and send back information to Hadoop client.
HDFS Block Replication Pipeline
- The client retrieves a list of Datanodes from the Namenode that will host a replica of that block.
- The client then flushes the data block to the first Datanode.
- The first Datanode receives a block, writes it, and transfers it to the next data node in the pipeline.
- When all replicas are written, the Client moves on to the next block in the file.
HDFS Fault Tolerance
One data node has been down suddenly; in that case, HDFS can automatically manage that scenario. First, all name node is always received one heartbeat from every data node. If somehow it lost one heartbeat from one data node, considering the same data node as down, immediately auto replicate all the blocks on the remaining nodes to satisfy the replication factor.
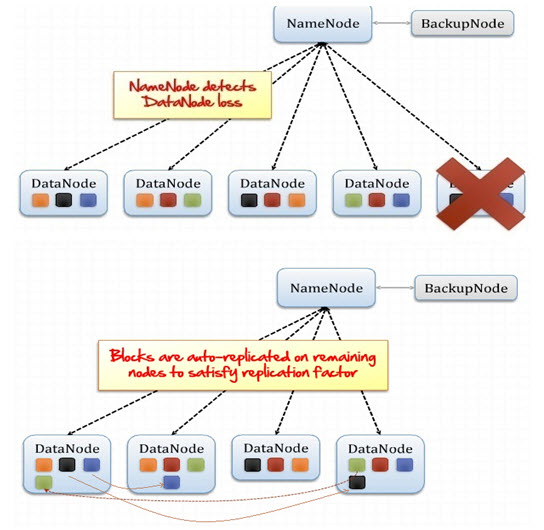
If the name node detects one new data node available in the cluster, it immediately rebalancing all the blocks, including the added data node.
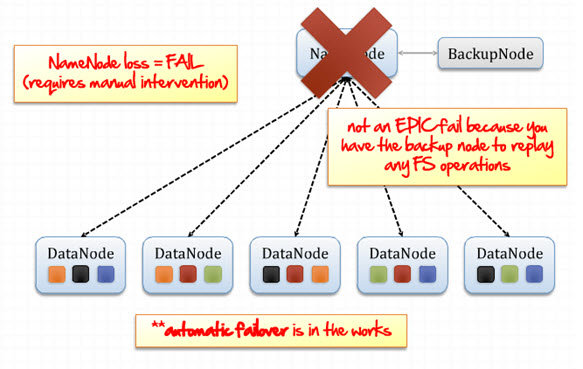
Now somehow Name node is lost or failed; in that case, a backup node holding one FS image of the name node replay all the FS operations immediately and up the name node as per requirement. But in that case, manual intervention is required, and the entire Hadoop ecosystem framework will be down for a couple of times to set up a new name node again. So, in this case, the name node can be a single point failure, to avoid this scenario, HDFS Federation is introducing multiple clusters set up of name node, and ZooKeeper can manage immediate up one alternative name node as per requirement.
Examples of Hadoop Ecosystem
Full Hadoop ecosystem example can be properly given in the below figure:
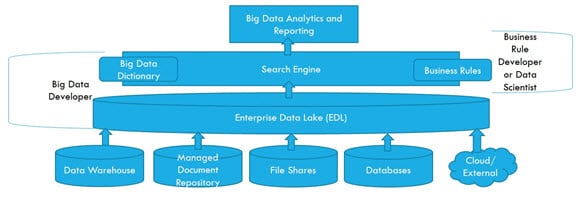
Data can come from any source like Data Warehouse, Managed Document Repository, File Shares, Normal RDMS databased, or cloud or external sources. All those data came to HDFS in a structure or non-structured or semi-structured way. HDFS store all those data as a distributed way, means storing in distributed commodity system very smartly.
Conclusion
Hadoop ecosystem is mainly designed to store and process huge data that should have presented any of the two factors between volume, velocity, and variety. It is storing data in a distributed processing system that runs on commodity hardware. Considering the full Hadoop ecosystem process, HDFS distributes the data blocks, and Map Reduce provides the programming framework to read data from a file stored in HDFS.
Recommended Articles
This has been a guide to Hadoop Ecosystem. Here we have discussed the basic concept of the hadoop ecosystem, its architecture, HDFS operations, examples, HDFS fault tolerance etc. You may also look at the following articles to learn more –
