Updated May 29, 2023

What is Pig?
Pig is an open-source technology part of the Hadoop ecosystem for processing highly unstructured data. The Apache software foundation manages this. A high-level scripting language called Pig Latin scripts exists within it, which assists programmers in focusing on data-level operations. The technology implicitly includes the map-reduce processes for data computing. It efficiently interacts with the Hadoop distributed file system(HDFS). It is implemented as an Extraction Transformation and Load (ETL) component in the Big Data pipeline. For complex data processing scenarios in Big Data implementations, it offers various operators and User-Defined Functions (UDFs).
Understanding Pig
By utilizing this technology, you can work with data that has an illegible or inconsistent schema and create high-level yet highly detailed scripts. It is an open-source technology that runs on top of Hadoop and is part of the highly vibrant and popular Hadoop ecosystem.
It works well with unstructured and incomplete data, so you don’t have to have the traditional layout of rules and columns for everything. It’s well-defined and can directly work on files in HDFS (Hadoop Distributed File System).
It will be your technology of choice to get data from the source into a data warehouse.
For example, a visual pipeline of how data typically flows before you can use it to generate the excellent charts you use to make business decisions.
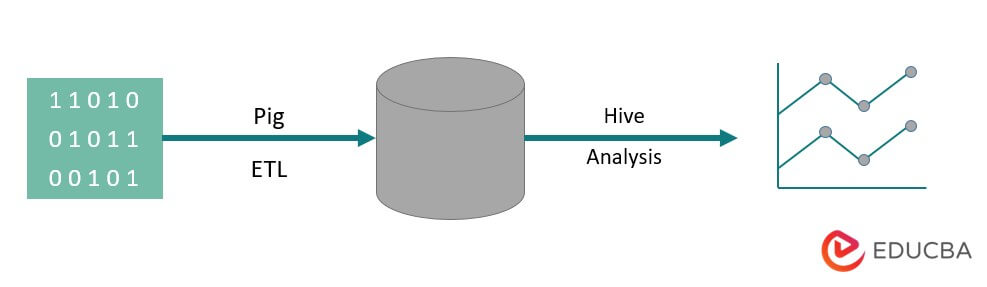
The raw data comes from various sources, such as sensors, mobile phones, etc. You will then use it to perform an ETL operation. ETL stands for extract, transform, and load; once these operations are performed, the cleaned-up data is stored in another database. An example of such a database would be HDFS, a part of Hadoop. Hive is a data warehouse that will run on top of a file system like this. Hive is what you would use for analysis, generating reports, and extracting insights.
ETL is a crucial step in data processing to get the raw data cleaned up and in the right form to be stored in a database. Extract refers to the operation of pulling unstructured, inconsistent data with missing fields and values from the original source. Transform represents the series of operations you would apply to the data to clean it up or get it.
Pre-computation of useful aggregate information, and processing of fields to match a specific format, all this is a part of data cleanup of the transform fields.
Finally, it performs the load operation where this clean data is stored in a database for further analysis. An example of a standard operation that Pig performs is to clean up log files.
Explain Pig Architecture
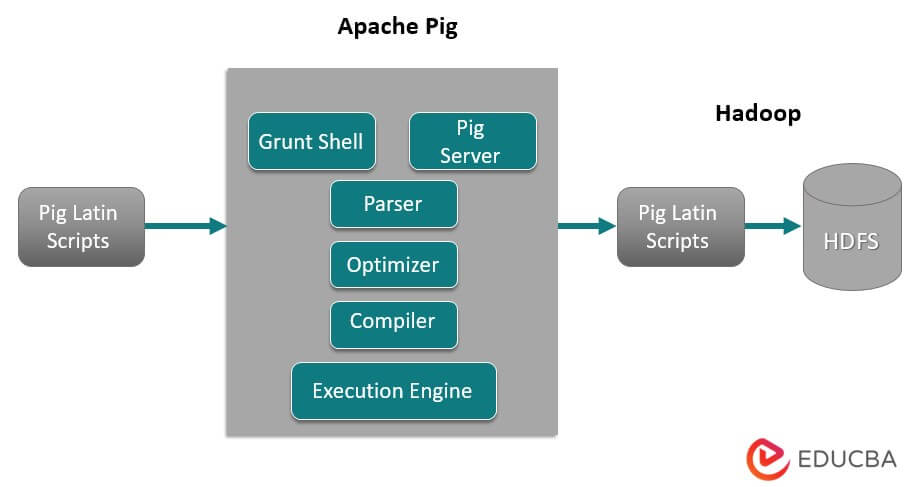
There are numerous parts of Architecture preferred:
- Parser: Parser deals with Pig Scripts and checks the syntax of the script, will type checking, and various assorted checks. Additionally, a DAG (Directed Acyclic Graph) might represent their result, which typically signifies the Pig Latin statements and logical operators.
Furthermore, the script will present the logical operators, including the nodes and data flows, as the edges represent them in the DAG.
- Optimizer: Later, the logical plan (DAG) typically exceeds the logical optimizer. It performs the logical optimizations additional, including projection, and promotes low.
- Compiler: The compiler also compiles that enhanced logical plan in a group of MapReduce works.
- Execution Engine: All MapReduce works post to Hadoop within a sorted sequence. Eventually, this generates the required outcomes, although these MapReduce works will be carried out with Hadoop.
- MapReduce: Google initially designed MapReduce to process web pages and power Google searches. MapReduce distributes computing across multiple machines in the cluster. It utilizes the inherent parallelism in the data processing. Modern systems, such as sensors or Facebook status updates, generate millions of raw data records.
An activity with this level can be prepared in two phases:
- Map
- Reduce
You decide what logic to implement within these phases to process your data.
- HDFS (Hadoop Distributed File System): Hadoop allows for an explosion of data storage and analysis at a scale in an unlimited capacity. Developers are using an application like Pig, Hive, HBase, and Spark to retrieve data from HDFS.
Features
It comes with different features:
- The Simplicity of Programming: Pig Latin is comparable to SQL, so it is quite simple for developers to create a Pig script. If you understand SQL language, it is incredibly simple to learn Pig Latin since it is just like SQL language.
- Rich Set of Operators: It includes various sets of operators to execute procedures just as join, filter, sort, and much more.
- Optimization Possibilities: The task itself can instantly enhance the performance of the task; therefore, the developers have to concentrate on the semantics of this language.
- Extensibility: Utilizing accessible operators, users can develop their functions to read, process, and write data.
- User Define Functions (UDFs): By using the service given by Pig for making UDFs, we could produce User-Defined Functions on several development languages, including Java, and invoke or embed all of them in Pig Scripts.
What is Pig Useful For?
Users utilize it to examine and execute responsibilities, including ad-hoc handling. It can be used intended for:
Analysis with huge raw data collections prefers data processing to get search websites. Such as Yahoo and Google benefit from evaluating data collected via Google and Yahoo search engines and handling extensive data collections like web records, streaming online info, etc. Even Facebook’s status updates generate millions of records of raw data.
How does this technology help you grow in your career?
Many organizations are implementing Apache Pig incredibly quickly.
This means Professions in Pig & Careers are rising daily. There has been huge progress in the development of Apache Hadoop within the last couple of years. Hadoop elements are like Hive, HDFS, HBase, MapReduce, etc.
Although Hadoop offers came into their second decade at this time yet, they have exploded in recognition through the previous Three to Four years.
A large number of software companies are applying Hadoop clusters incredibly commonly. This can be the best part of big data. The aiming experts could turn into experienced in this excellent technology.
Conclusion
Apache Pig Expertise is an essential requirement in the market and can continue to be extended. By simply understanding the concepts as well as getting experience with the best Apache Pig in Hadoop skills, the experts may engage in their Apache Pig profession perfectly.
Recommended Articles
This has been a guide to What is Pig? Here we discussed the basic concepts, architecture, Pig features, and career growth. You can also go through our other suggested articles to learn more –

