Updated June 8, 2023
MapReduce in Hadoop
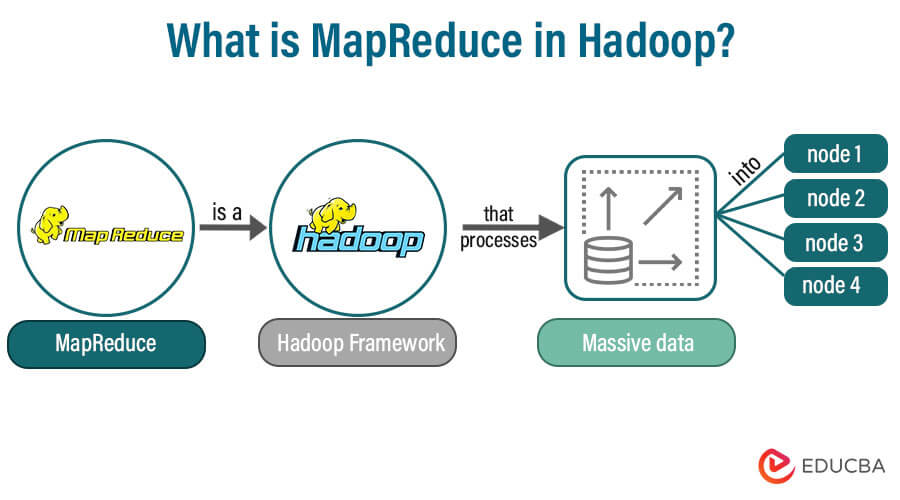
MapReduce is the Hadoop framework that processes a massive amount of data in numerous nodes. This data processes parallelly on large clusters of hardware in a reliable manner. It allows the application to store the data in a distributed form. It processes large datasets across groups of computers using simple programming models. Hence, MapReduce is a programming model for processing vast amounts of data spread over several clusters.
The Apache Hadoop project contains several sub-projects:
- Hadoop Common or core: The Hadoop Common has utilities supporting other Hadoop subprojects.
- HDFS: Hadoop Distributed File System helps to access the distributed file to application data.
- Hadoop MapReduce: It is a software framework for processing large distributed data sets on compute clusters.
- Hadoop YARN: Hadoop YARN is a framework for resource management and scheduling job.
How does MapReduce in Hadoop make working so easy?
The MapReduce makes it easy to scale up data processing over hundreds or thousands of cluster machines. The MapReduce model works in two steps called map and reduce, and the processing called mapper and reducer, respectively. Once we write MapReduce for an application, scaling up to run over multiple clusters is merely a configuration change. This feature of the MapReduce model attracted many programmers to use it.
How MapReduce in Hadoop works?
#1 Input Splits
This step is the combination of the input splits step and the Map step. In the Map step, the source file passes line by line. Before input pass to the Map function job, it divides into small fixed-size called Input splits. The Input split is a chunk of the information which a single map could consume.
#2 Map Step
In the Map step, each split data passes to the mapper function, then the mapper function processes the data and then outputs values. Generally, the map or mapper’s job input data is in the form of a file or directory stored in the Hadoop file system (HDFS).
#3 Shuffling
The output phase of mapping that consolidates the output data is shuffling. It merges all the key-value pairs that have the same keys. Later these merged data to act as input for sorting, and the sorting step happens.
#4 Reduce step
This step is the combination of the Shuffle step and the Reduce. The reduce function or reducer’s job takes the data resulting from the map function. After processing, the new set of effects produces by reducing the role, which again stores back into the HDFS.
A Hadoop framework is not sure that each cluster performs which job, either Map or Reduce or both Map and Reduce. So, the Map and Reduce tasks’ request should be sent to the appropriate servers in the cluster. The Hadoop framework manages all the tasks of issuing, verifying completion of work, fetching data from HDFS, copying data to the nodes’ group, and so on. In Hadoop, mostly computing occurs on nodes and data in nodes, reducing the network traffic.
So the MapReduce framework is conducive to the Hadoop framework.
Advantages of MapReduce
The Advantages areas listed below.
- The MapReduce makes Hadoop highly Scalable because it allows storing large data sets in distributed form across multiple servers. As it is spread across various, so can operate in parallel.
- MapReduce provides a cost-effective solution for businesses that need to store growing data and process the data very cost-effectively, which is today’s business need.
- MapReduce makes Hadoop very flexible for different data sources and data types, such as structured or unstructured data. So it makes it very flexible to access structured or unstructured data and process them.
- Hadoop stores data in the distributed file system, which keeps the data on the local disk of a cluster. The MapReduce programs are also generally located on the same servers, allowing faster data processing without needing access from other servers.
- As Hadoop stores data in the distributed file system, and the MapReduce program works, it divides tasks task map and reduces, which could execute in parallel. And again, because of the parallel execution, it reduces the entire run time.
Skills
Required skills for MapReduce in Hadoop are having good programming knowledge of Java (mandatory), Operating System Linux, and knowledge of SQL Queries.
Scope
It is a fast-growing field as the big data field is growing. Hence, the scope of MapReduce in Hadoop is very promising in the future as the amount of structured and unstructured data is increasing exponentially daily. Social media platforms generate much-unstructured data that can be mined to get real insights into different domains.
Final Thoughts
The reduce function or reducer’s job takes the data resulting from the map function. The MapReduce advantages are Scalability, Cost-effective solution, Flexibility, and Parallel processing.
Frequently Asked Questions(FAQs)
Q1 How many mappers are present in MapReduce?
Answer: Mappers are the functions that help to process the input data. In MapReduce, the input data is the input splits. Hence the number of mappers in a MapReduce is driven by the number of input splits.
Q2 What are the benefits of MapReduce?
Answer: MapReduce helps users to scale the data processing in multiple nodes quickly. It reduces the time to transport data to the general location of the servers. It can process each data record as fast as the data get off the disk.
Q3 What are the limitations of MapReduce?
Answer: MapReduce fails to support the integration of the processing data. The customer requirements emerge with the support to real-time for the data stored in distributed file systems.
Recommended Articles
We hope that this EDUCBA information on “What is MapReduce in Hadoop” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
