
What is Hadoop?
Hadoop is defined as a software utility that uses a network of many computers to solve problems involving a huge amount of computation and data, these data can be structured or unstructured, and hence it provides more flexibility for collecting, processing, analyzing, and managing data. It has an open-source distributed framework for storing, managing, and processing big data applications in scalable clusters of computer servers.
Applications of Hadoop
The Applications of Hadoop are given below:
1. Website Tracking
Suppose you have created a website and want to know about visitors’ details. Hadoop will capture a massive amount of data about this. It will give information about the visitor’s location, which page visitors visited first and most, how much time spent on the website and on which page, how many times a visitor has visited the page, and what visitors like most. This will provide a predictive analysis of visitors’ interests. Website performance will predict what would be users’ interests. Hadoop accepts data in multiple formats from multiple sources. Apache HIVE will be used to process millions of data.
2. Geographical Data
When we buy products from an e-commerce website, the website will track the user’s location and predict customer purchases using smartphones and tablets. The Hadoop cluster will help to figure out business in geo-location. This will help the industries to show the business graph in each area (positive or negative).
3. Retail Industry
Retailers will use the data of customers, which is present in the structured and unstructured format, to understand and analyze the data. This will help users understand customer requirements and provide better benefits and improved services.
4. Financial Industry
Financial Industry and Financial companies will assess the financial risk and market value and build the model which will give customers and the industry better results in terms of investment like the stock market, FD, etc. Understand the trading algorithm. Hadoop will run the build model.
5. Healthcare Industry
Hadoop can store large amounts of data. Medical data is present in an unstructured format. This will help the doctor for a better diagnosis. Hadoop will store a patient’s medical history for over a year and analyze disease symptoms.
6. Digital Marketing
We are in the era of the 20s, and everyone is connected digitally. Information is reached to the user over mobile phones or laptops, and people know every detail about news, products, etc. Hadoop will store massively online generated data, store, analyze and provide the result to digital marketing companies.
Features of Hadoop
Given below are the features of Hadoop:
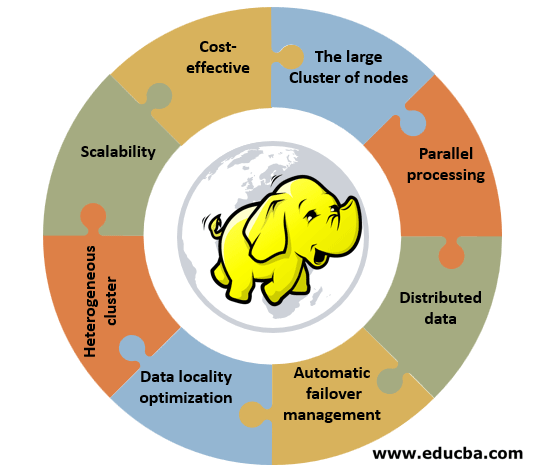
1. Cost-effective: Hadoop does not require specialized or effective hardware to implement it. It can be implemented on simple hardware, which is community hardware.
2. Large cluster of nodes: A cluster can consist of hundreds or thousands of nodes. The benefit of having a large cluster is that it offers clients more computing power and a huge storage system.
3. Parallel processing: Data can be processed simultaneously across all the clusters, saving time. The traditional system was not able to do this task.
4. Distributed data: Hadoop framework takes care of splitting and distributing the data across all the nodes within a cluster. It replicates data over all the clusters. The replication factor is 3.
5. Automatic failover management: If any cluster node fails, the Hadoop framework will replace the failure machine with a new one. The new machine automatically shifts the replication settings from the old machine. Admin does not need to worry about it.
6. Data locality optimization: Suppose the programmer needs node data from a database located at a different location. The programmer will send a byte of code to the database. It will save bandwidth and time.
7. Heterogeneous cluster: It has a different node supporting different machines with different versions. For example, an IBM machine supports Red Hat Linux.
8. Scalability: Adding or removing nodes and adding or removing hardware components to or from the cluster. We can perform this task without disturbing cluster operations. For example, RAM or Hard drives can be added or removed from the cluster.
Advantages of Hadoop
Given below are the advantages mentioned:
- Hadoop can handle large data volumes and scale the data based on requirements. Now a day’s, data is present in 1 to 100 tera-bytes.
- It will scale a huge volume of data without having many challenges. Let’s take the example of Facebook – millions connect, share thoughts, comments, etc. Moreover, it can handle software and hardware failure smoothly.
- If one system fails, data will not be lost, or no loss of information because the replication factor is 3. Data is copied three times, and Hadoop will move data from one system to another. It can handle various data types like structured, unstructured, or semi-structured.
- Structure data like a table (we can retrieve rows or columns value easily), unstructured data like videos and photos, and semi-structured data like a combination of structured and semi-structured.
- The cost of implementing Hadoop with the big data project is low because companies purchase storage and processing services from cloud service providers. After all, the cost of per-byte storage is low.
- As big data continues to grow, professionals with skills in distributed computing and Hadoop find themselves in high demand. These technologies are now used in many sectors, and those looking for hadoop jobs may find a wide range of opportunities available in industries ranging from healthcare to finance, where efficient data processing is critical.
- It provides flexibility while generating value from the data, structured and unstructured. For example, we can derive valuable data from data sources like social media, entertainment channels, and shopping websites.
- Hadoop can process data with CSV files, XML files, etc. Data is processed parallelly in the distribution environment. Therefore, we can map the data when it is located on the cluster. The server and data are located simultaneously, so data processing is faster.
- We can proceed with terabytes of data within a minute if we have a huge unstructured data set. Developers can code for Hadoop using different programming languages like Python, C, and C++. It is an open-source technology. The source code is readily available online. If data increases daily, we can add nodes to the cluster. We don’t need to add more clusters. Every node performs its job by using its resources.
Conclusion
Hadoop can perform large data calculations. To process this, Google has developed a Map-Reduce algorithm, and Hadoop will run the algorithm. This will play a major role in statistical analysis, business intelligence, and ETL processing. Easy to use and less costly available. It can handle tera-byte data, analyze it and provide value from data without any difficulties with no loss of information.
Recommended Articles
This is a guide to What is Hadoop? Here we discuss Hadoop’s introduction, applications, features, and advantages. You can also go through our other suggested articles to learn more–
