Updated February 28, 2023

Introduction to MapReduce Word Count
Hadoop can be developed in programming languages like Python and C++. MapReduce Hadoop is a software framework for ease in writing applications of software processing huge amounts of data. MapReduce Word Count is a framework which splits the chunk of data, sorts the map outputs and input to reduce tasks. A File-system stores the output and input of jobs. Re-execution of failed tasks, scheduling them and monitoring them is the task of the framework. We will learn how to write a code in Hadoop in MapReduce and not involve python to translate code into Java.
Installing of Python BeautifulSoup
Installing with explanation:
Explanation: Taking in STDIN and STDOUT ( standard input and standard output ) helps passing data between the Reduce and Map code. sys.stdout to print the output and sys stdin to read the input is used in Python.
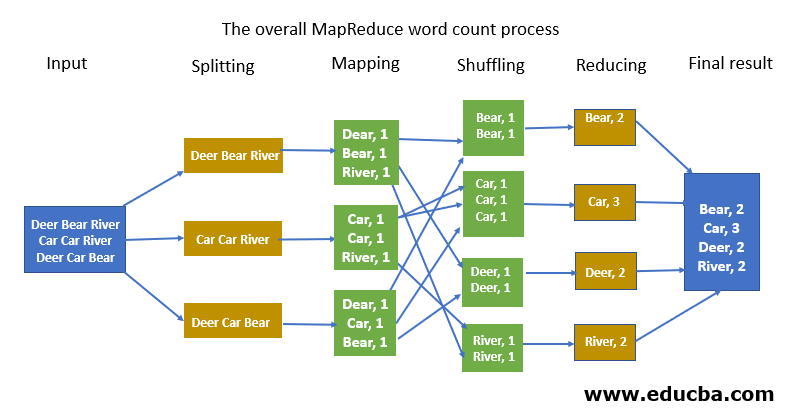
Splitting: The parameter of splitter can be anything. By comma, space, by a new line or a semicolon.
Mapping: This is done as explained below.
Shuffle / Intermediate splitting: The process is usually parallel on cluster keys. The output of the map gets into the Reducer phase and all the similar keys of data are aligned in a cluster.
Reduce: This is done as explained below. Final result – All the data is clustered or combined to show the together form of a result.
The input given is converted into the string. Then it toknises them into words as if it need to break them. The mapper will append a single number or digit to each word and mapper outputs are shown above. Once we get the outputs as key-value pairs, once we pass the offset address as input to the mapper, the output of the value would be key-value pairs.
The output is getting into the sorting and shuffling phase. When we sort based on keys, all the keys will come to once a particular place. Sorting on the keys and shuffling the keys is done. A single word will go to a single reducer. Input to the reducer is key-value pairs. Once we pass outputs to reducer as input, the reducer will sum up all the values to keys.
That is, it groups up all the similar keys and output would be the concatenated key-value pair. The reducer will pick the result from the temp path and it will arrive at the final result. When we execute map-reduce, the input and output should be created in HDFS. Which is why import a lot of files that will help do the word count. We use something called a job client to do configuration. Extends configure and implements the tools.
Examples to Implement MapReduce Word Count
Here is the example mentioned:
1. Map() Function
Create and process the import data. Takes in data, converts it into a set of other data where the breakdown of individual elements into tuples is done. No API contract requiring a certain number of outputs.
2. Reduce() Function
Mappers’ output is passed into the reduction. Processes the data into something usable. Every single mapper is passed into the reduced function. The new output values are saved into HDFS. A concept called streaming is used in writing a code for word count in Python using MapReduce. Let’s look at the mapper Python code and a Reducer Python code and how to execute that using a streaming jar file. The API has a technical name for this task which is shuffle and sort phase.
MapReduce has everything as a Key-Value pair, that is, the value of mapper input, output and value of reducer input, the output is in key values.
Input:
I am the best there is at what I do but what I do isn’t very nice.
considering this as the input, this is how input is taken using a map and reduce it.
Output:
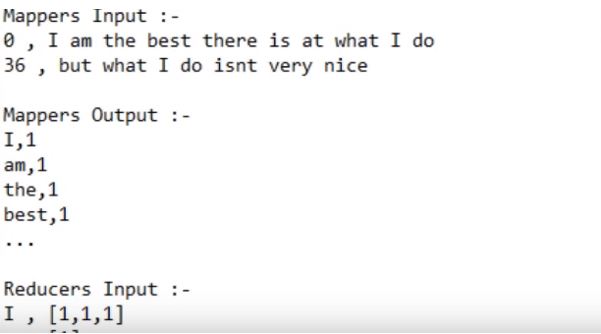
We need to know the datatypes of mapper and reducer inputs and outputs.
Lately, all the input is taken and is read one by one by the mapper and then passed the output to the reducer. In this case, first comes I and then am and so on. Importing a few files and other libraries for running the program will help you get done with the word count.

Conclusion
Imagine you have lots of documents, which is huge data. And you need to count the number of occurrences of each word throughout the documents. I might seem like an arbitrary task but the basic idea is that let’s say you have a lot of web pages and you want to make them available for search queries. Aggregation of data is done by the reducer and it consists of all the keys and combines them all for similar key-value pairs which are the Hadoop shuffling process.
Recommended Articles
This is a guide to MapReduce Word Count. Here we discuss an introduction to MapReduce Word Count with installing and examples with an explanation. You can also go through our other related articles to learn more –

