Updated May 23, 2023
Introduction to HADOOP Framework
Hadoop Framework is the popular open-source big data framework used to process many unstructured, semi-structured, and structured data for analytics purposes. This is licensed with Apache software. The Hadoop framework mainly involves storing and data processing or computation tasks. It includes a Hadoop distributed File system known as HDFS, Map-reduce for data computing, YARN for resource management, job scheduling, and other standard utilities for advanced functionalities to manage the Hadoop clusters and distributed data system. The Java libraries implement Hadoop for the framework and components functionalities. Hadoop supports batch processing of data and can be implemented through commodity hardware.
HADOOP
- Solution for BIG DATA: It deals with the complexities of high volume, velocity, and variety of data.
- Set up the open-source project.
- Stores a huge volume of data reliably and allows massively distributed computations.
- Hadoop’s key attributes are redundancy and reliability (no data loss).
- Primarily focuses on batch processing.
- Runs on commodity hardware – you don’t need to buy any special expensive hardware.
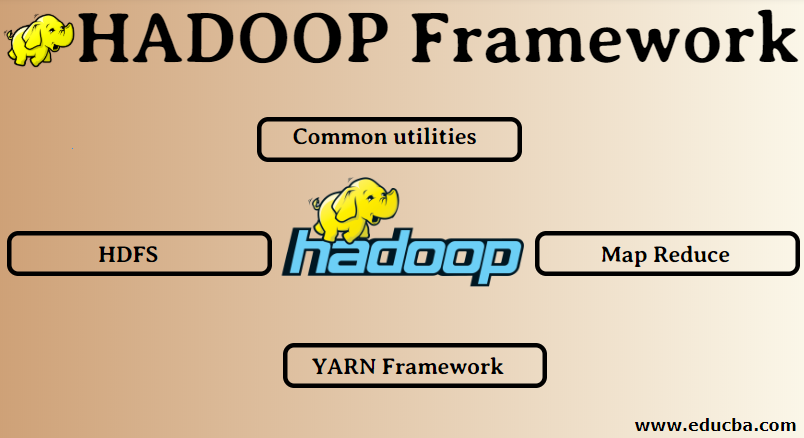
HADOOP Framework
- Common Utilities
- HDFS
- Map Reduce
- YARN Framework
1. Common Utilities
Also called the Hadoop common. These are the JAVA libraries, files, scripts, and utilities required by the other Hadoop components to perform.
2. HDFS: Hadoop Distributed File System
Why has Hadoop chosen to incorporate a Distributed file system?
Let’s understand this with an example: We need to read 1TB of data, and we have one machine with 4 I/O channels, each channel having 100MB/s; it took 45 minutes to read the entire data. 10 engines read the exact amount of data, each with 4 I/O channels and 100MB/s. Guess the amount of time it took to read the data. 4.3 minutes. HDFS solves the problem of storing big data. The two main components of HDFS are NAME NODE and DATA NODE. The name node is the master; we may have a secondary name node; if the primary name node stops working, the secondary name node will be a backup. The name node maintains and manages the data nodes by storing metadata. The data node is the slave, which is the low-cost commodity hardware. We can have multiple data nodes. The data node stores the actual data. This data node supports the replication factor; suppose if one data node goes down, the data can be accessed by the other replicated data node. Therefore, the accessibility of data is improved, and the loss of information is prevented.
3. Map Reduce
It solves the problem of processing big data. Let’s understand the concept of map reduction by solving this real-world problem. ABC company wants to calculate its total sales, city-wise. The hash table concept won’t work because the data is in terabytes to use the Map-Reduce idea.
There are two phases:
- Map: First, we will split the data into smaller chunks called mappers based on the key/value pair. So here, the key will be the city name, and the value will be total sales. Each mapper will get each month’s data which gives a city name and corresponding sales.
- Reduce: It will get these piles of data, and each reducer will be responsible for North/West/East/South cities. The reducer will collect these small chunks and convert them into larger amounts (by adding them) for a particular city.
4. YARN Framework: Yet Another Resource Negotiator
The initial version of Hadoop had just two components: Map Reduce and HDFS. Later it was realized that Map Reduce couldn’t solve many big data problems. The idea was to take the resource management and job scheduling responsibilities away from the old map-reduce engine and give it to a new component. So this is how YARN came into the picture. It is the middle layer between HDFS and Map Reduce, responsible for managing cluster resources.
It has two key roles to perform: a. Job Scheduling b. Resource management
- Job Scheduling: When a large amount of data is given for processing, it must be distributed and broken down into different tasks/jobs. Now the JS decides which position needs to be prioritized, the time interval between two positions, dependency among the jobs, and checks that there is no overlapping between the jobs running.
- Resource Management: We need resources for processing and storing the data. So the resource manager provides, manages, and maintains the resources to store and process the data.
So now we are clear about the concept of Hadoop and how it solves the challenges created by BIG DATA !!!
Recommended Articles
This has been a guide to HADOOP Framework. Here we have discussed the basic concept and the top 4 Hadoop frameworks in detail. You can also go through our other suggested articles to learn more –
