Updated March 21, 2023
Introduction to MapReduce
MapReduce is a computational component of the Hadoop Framework for easily writing applications that process large amounts of data in-parallel and stored on large clusters of cheap commodity machines in a reliable and fault-tolerant manner. In this topic, we are going to learn about How MapReduce Works?
MapReduce can perform distributed and parallel computations using large datasets across a large number of nodes. A MapReduce job usually splits the input datasets and then process each of them independently by the Map tasks in a completely parallel manner. The output is then sorted and input to reduce tasks. Both job input and output are stored in file systems. Tasks are scheduled and monitored by the framework.
How Does MapReduce Work?
MapReduce architecture contains two core components as Daemon services responsible for running mapper and reducer tasks, monitoring, and re-executing the tasks on failure. In Hadoop 2 onwards Resource Manager and Node Manager are the daemon services. When the job client submits a MapReduce job, these daemons come into action. They are also responsible for parallel processing and fault-tolerance features of MapReduce jobs.
In Hadoop 2 onwards resource management and job scheduling or monitoring functionalities are segregated by YARN (Yet Another Resource Negotiator) as different daemons. Compared to Hadoop 1 with Job Tracker and Task Tracker, Hadoop 2 contains a global Resource Manager (RM) and Application Masters (AM) for each application.
- Job Client submits the job to the Resource Manager.
- YARN Resource Manager’s scheduler is responsible for the coordination of resource allocation of the cluster among the running applications.
- The YARN Node Manager runs on each node and does node-level resource management, coordinating with the Resource manager. It launches and monitors the compute containers on the machine on the cluster.
- Application Master helps the resources from Resource Manager and use Node Manager to run and coordinate MapReduce tasks.
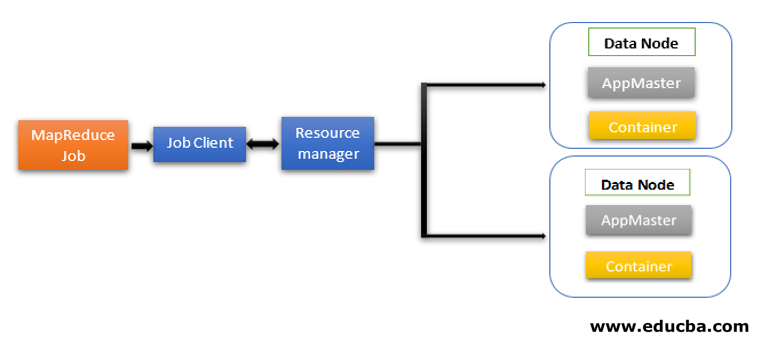
- HDFS is usually used to share the job files between other entities.
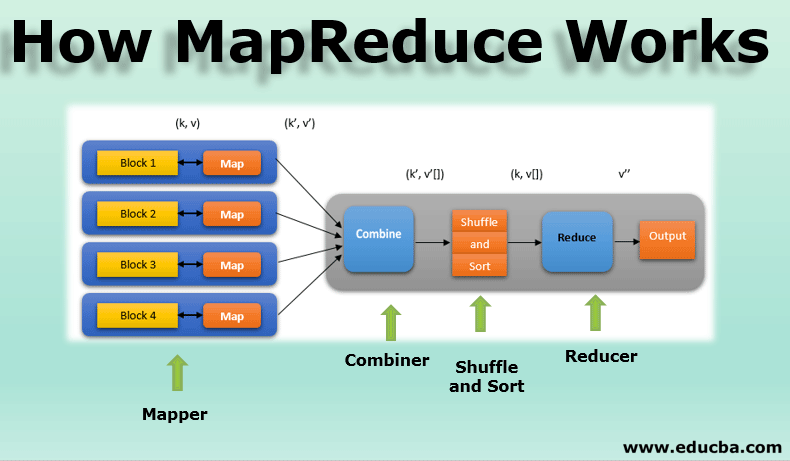
Phases of the MapReduce model
MapReduce model has three major and one optional phase:
1. Mapper
- It is the first phase of MapReduce programming and contains the coding logic of the mapper function.
- The conditional logic is applied to the ‘n’ number of data blocks spread across various data nodes.
- Mapper function accepts key-value pairs as input as (k, v), where the key represents the offset address of each record and the value represents the entire record content.
- The output of the Mapper phase will also be in the key-value format as (k’, v’).
2. Shuffle and Sort
- The output of various mappers (k’, v’), then goes into Shuffle and Sort phase.
- All the duplicate values are removed, and different values are grouped together based on similar keys.
- The output of the Shuffle and Sort phase will be key-value pairs again as key and array of values (k, v[]).
3. Reducer
- The output of the Shuffle and Sort phase (k, v[]) will be the input of the Reducer phase.
- In this phase reducer function’s logic is executed and all the values are aggregated against their corresponding keys.
- Reducer consolidates outputs of various mappers and computes the final job output.
- The final output is then written into a single file in an output directory of HDFS.
4. Combiner
- It is an optional phase in the MapReduce model.
- The combiner phase is used to optimize the performance of MapReduce jobs.
- In this phase, various outputs of the mappers are locally reduced at the node level.
- For example, if different mapper outputs (k, v) coming from a single node contains duplicates, then they get combined i.e. locally reduced as a single (k, v[]) output.
- This phase makes the Shuffle and Sort phase work even quicker thereby enabling additional performance in MapReduce jobs.
All these phases in a MapReduce job can be depicted as below:
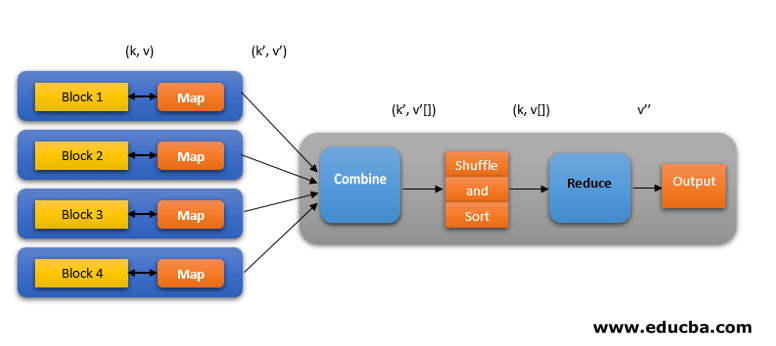
For example, MapReduce logic to find the word count on an array of words can be shown as below:
fruits_array = [apple, orange, apple, guava, grapes, orange, apple]
- The mapper phase tokenizes the input array of words into the ‘n’ number of words to give the output as (k, v). For example, consider ‘apple’. Mapper output will be (apple, 1), (apple, 1), (apple, 1).
- Shuffle and Sort accept the mapper (k, v) output and group all values according to their keys as (k, v[]). i.e. (apple, [1, 1, 1]).
- The Reducer phase accepts Shuffle and sort output and gives the aggregate of the values (apple, [1+1+1]), corresponding to their keys. i.e. (apple, 3).
Speculative Execution of MapReduce Work
The speed of MapReduce is dominated by the slowest task. So, to up the speed, a new mapper will work on the same dataset at the same time. Whichever completes the task first is considered as the final output and the other one is killed. It is an optimization technique.
Benefits of MapReduce
Here are the benefits of MapReduce mentioned below.
1. Fault-tolerance
- During the middle of a map-reduce job, if a machine carrying a few data blocks fails architecture handles the failure.
- It considers replicated copies of the blocks in alternate machines for further processing.
2. Resilience
- Each node periodically updates its status to the master node.
- If a slave node doesn’t send its notification, the master node reassigns the currently running task of that slave node to other available nodes in the cluster.
3. Quick
- Data processing is quick as MapReduce uses HDFS as the storage system.
- MapReduce takes minutes to process terabytes of unstructured large volumes of data.
4. Parallel Processing
- MapReduce tasks process multiple chunks of the same datasets in-parallel by dividing the tasks.
- This gives the advantage of task completion in less time.
5. Availability
- Multiple replicas of the same data are sent to numerous nodes in the network.
- Thus, in case of any failure, other copies are readily available for processing without any loss.
6. Scalability
- Hadoop is a highly scalable platform.
- Traditional RDBMS systems are not scalable according to the increase in data volume.
- MapReduce lets you run applications from a huge number of nodes, using terabytes and petabytes of data.
7. Cost-effective
- Hadoop’s scale-out feature along with MapReduce programming lets you store and process data in a very effective and affordable manner.
- Cost savings can be massive as figures of hundreds for terabytes of data.
Conclusion – How MapReduce Work
Modern data is moving more towards the unstructured type and huge, conventional data processing option like RDBMS is even more difficult, time-consuming and costly. But Hadoop’s MapReduce Programming is much effective, safer, and quicker in processing large datasets of even terabytes or petabytes.
Recommended Articles
This is a guide to How MapReduce Works. Here we discuss the basic concept, working, phases of the MapReduce model with benefits respectively. You may also have a look at the following articles to learn more –

