Updated May 26, 2023
What is Hadoop Architecture
Hadoop architecture is a framework that Apache hosts on its open-source platform. This framework helps in processing and storing large clusters of data using a network of computers. Hadoop architecture is created on Java and can only be used for offline processing. Moreover, the architecture is designed to be highly scalable and fault-resistant. Many tech giants use the Hadoop architecture to gain insights from their data promptly and cost-effectively.
Evolution of Hadoop
Hadoop is a distributed computing platform initially created by Doug Cutting and Mike Cafarella in 2005. The platform was named after a toy elephant owned by Cutting’s son. Hadoop was designed to process and store large datasets across clusters of commodity hardware. Over the years, Hadoop has undergone significant changes and improvements. Here are some key milestones in the evolution of Hadoop:
- Hadoop 0.1 (2006): The first version of Hadoop was released in 2006. It included the Hadoop Distributed File System (HDFS) and MapReduce, which allowed developers to write programs to process data in parallel across many nodes.
- Hadoop 1.0 (2011): The first stable release of Hadoop was made available in 2011. It included improvements to HDFS, such as support for file appends and file permissions, and a new resource manager called YARN (Yet Another Resource Negotiator).
- Hadoop 2.0 (2013): This release introduced significant changes to the architecture of Hadoop. It separated the resource management and job scheduling functions from MapReduce, allowing other processing frameworks to run on top of Hadoop. It also introduced support for running Hadoop in a high-availability configuration.
- Hadoop 2.2 (2013): This release introduced support for erasure coding in HDFS, which improved data durability and reduced storage costs.
- Hadoop 3.0 (2017): This release included several significant changes, including support for containerization, which allowed Hadoop to run on platforms like Docker and Kubernetes. It also introduced improvements to HDFS, including support for a hierarchical namespace and a new erasure coding algorithm called Reed-Solomon.
- Hadoop 3.2 (2019): This release included several performance improvements, including support for faster erasure coding and a new garbage collection algorithm that reduced the memory overhead of Hadoop.
In addition to these major releases, Hadoop has also seen the development of several related projects, such as Apache Spark, Apache Hive, and Apache Pig, which provide additional processing frameworks for Hadoop. Overall, Hadoop has evolved significantly and remains a popular platform for processing and storing large datasets.

Hadoop Architecture
- This architecture’s basic idea is that the entire storing and processing are done in two steps and two ways. The first step is processing, which reduces programming, and the second-way step is storing the data done on HDFS.
- It has a master-slave architecture for storage and data processing. The master node for data storage in Hadoop is the name node. There is also a master node that monitors and parallels data processing by using Hadoop Map Reduce.
- The slaves are other machines in the Hadoop cluster that help store data and perform complex computations. Each slave node has been assigned a task tracker, and a data node has a job tracker, which helps run the processes and synchronize them effectively. This type of system can be set up on the cloud or on-premise.
- The Name Node is a single point of failure when it is not running in high availability mode. The Hadoop architecture also has provisions for maintaining a stand-by Name node to safeguard the system from losses. Previously, secondary name nodes acted as a backup when the primary name node was down.
Components of Hadoop
- HDFS: An acronym for Hadoop Distributed File System, was developed after taking inspiration from Google’s File System. HDFS provides excellent fault resistance and scalability by breaking data into blocks and storing them across many nodes.
- Yarn: The full form of Yarn is Yet Another Resource Negotiator. This component of Hadoop manages the resources in the cluster and enables the scheduling of many applications by allocating resources to each application according to its needs.
- MapReduce: This component functions as a framework to allow Java programs to conduct simultaneous data processing. MapReduce breaks down large data sets into smaller chunks and distributes them across many nodes for easy processing.
- Hadoop common or common utilities: This component comes equipped with standard sets of tools and utilities that help developers create applications to run on Hadoop.
1) HDFS
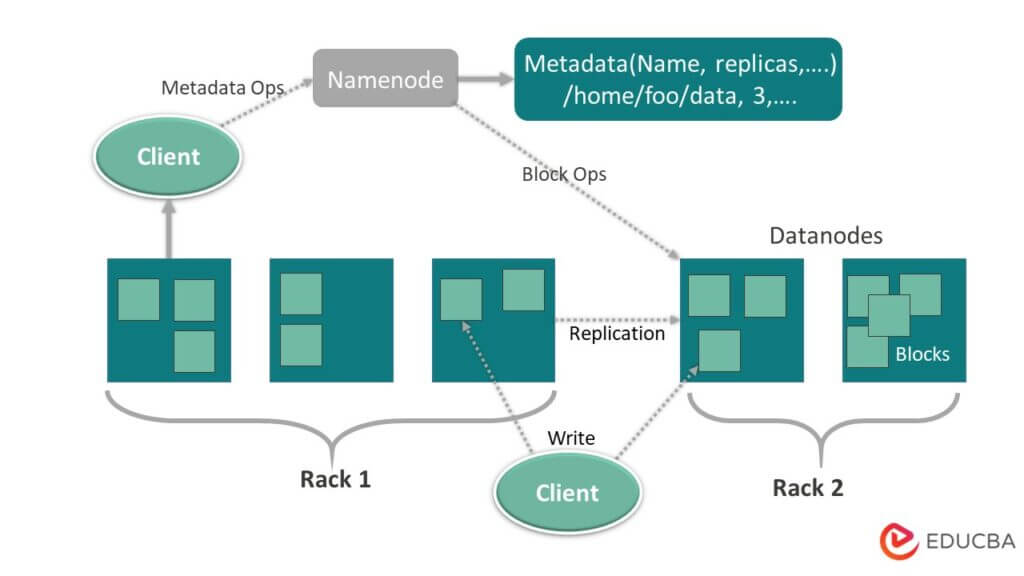
Hadoop Distributed File System or HDFS is a component of the Hadoop framework used for storing and managing large datasets across several connected computers. HDFS is designed to provide greater scalability and fault resistance to the Hadoop framework. It stores data in large chunks across many nodes. The primary function of HDFS is to act as a storage backend for other distributed applications, including MapReduce and HBase. Overall, HDFS is a key component of the Hadoop ecosystem that enables the storage and management of large data in a scalable and fault-tolerant manner.
HDFS consists of two main Data storage nodes – the NameNode and the DataNodes. The figure given below will explain the HDFS architecture in more detail.
- NameNode: The NameNode functions as the Master in a cluster and controls the DataNodes. It can command the DataNodes to accomplish such functions as delete, replicate, and create. NameNodes store the metadata about the file system, including the location of the data blocks, the name and data size, and the fault-tolerance factor for each block. The users use these meta-data to log their work on the framework.
- DataNodes: The DataNodes store the actual data blocks. They are Slaves and are under the command of the NameNode. DataNodes are responsible for maintaining the consistency and availability of the data. The storage capacity of a Hadoop cluster is directly related to the number of DataNodes it has. In any Hadoop cluster, there could be anywhere between 0-500 DataNodes present, but those that require more storage capacity can have even more DataNodes.
- File Block in HDFS: Whenever users upload data to HDFS, the system divides it into smaller pieces called blocks. Each block is typically 128 MB, although this can be configured manually. To reduce the chance of data loss, HDFS distributes these blocks across several nodes.
- Replication management in HDFS: In the Hadoop Distributed File System, the user is not at risk of losing his data. This component of HDFS enables the retrieval of data even if a node storing a data block becomes corrupted or fails. In HDFS, the default practice is replicating each data block three times. However, it is possible to increase the number of replicas to a higher value manually. In HDFS, the Replication management function ensures the dispersion of these replicas across many nodes. They also take responsibility for creating or deleting replicas according to user needs.
2) Yarn
Yarn stands for “Yet Another Resource Negotiator.” It is a resource management component of the Hadoop ecosystem. Yarn is responsible for two main functions. The first is managing and monitoring the resources in a cluster. The second is arbitrating these resources among all scheduled to-run applications. Yarn manages such resources as memory, network, disk, and CPU.
Overall, Yarn allows the Hadoop cluster to tackle more workloads. Thus it improves the scalability of applications. As a key component of the Hadoop ecosystem, people widely use it for data processing and management.
Features of Yarn
Following are the salient features of Yarn-
Scalability: Yarn’s Resource Manager can process petabytes of data by storing them in blocks across many nodes. Thus, many applications can run side-by-side with each other because of the arbitration of resources. Thus Yarn provides scope for scalability.
Flexibility: Yarn separates the function of resource management from the function of job scheduling, which helps to improve flexibility in the Hadoop cluster.
Compatibility: Yarn has the necessary support to run many of the processes of the Hadoop cluster, including MapReduce.
Multi-tenancy: Yarn allows multiple users to work on the same data cluster. The system also maintains the division of allocated resources while allowing concurrent applications to run in a cluster.
Steps to Running an Application in YARN
There are 5 steps involved when running an application in Yarn. They are:
- The user uploads an application to Yarn’s ResourceManager.
- Yarn allocates resources based on the requirements.
- Yarn’s Application Master establishes a link with the related NodeManager, allowing it to utilize the container.
- NodeManager runs the container.
- Yarn releases the resources once it successfully executes the container and the application finishes running.
3) MapReduce
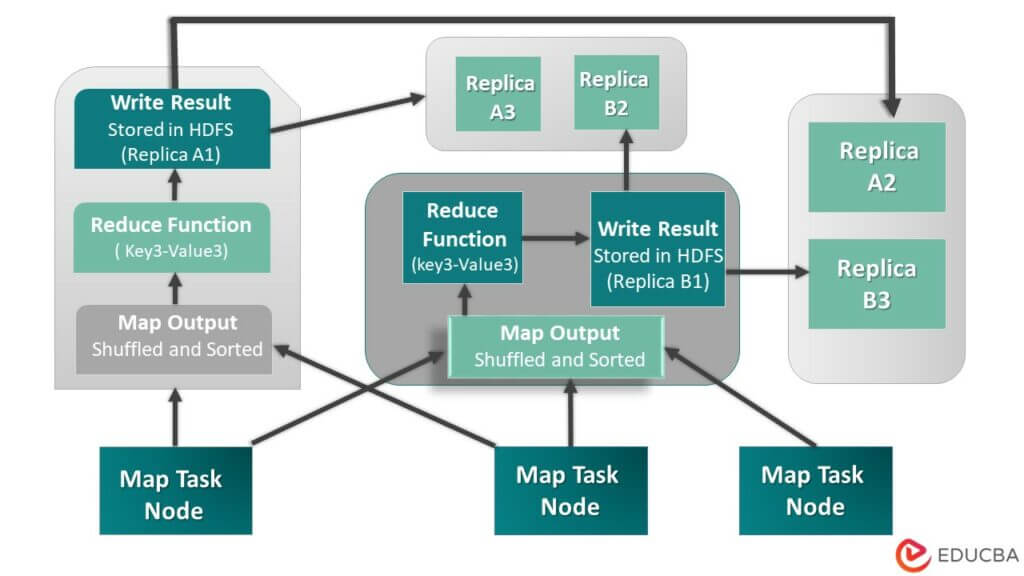
MapReduce is a data structure and programming model inspired by the Yarn framework. Hadoop clusters use it to execute large datasets concurrently. This makes the Hadoop architecture run smoothly and swiftly. MapReduce deals with large data sets by processing them in two phases. The process includes two phases: firstly, the Map phase, followed by the Reduce phase. The image given below illustrates MapReduce in detail –
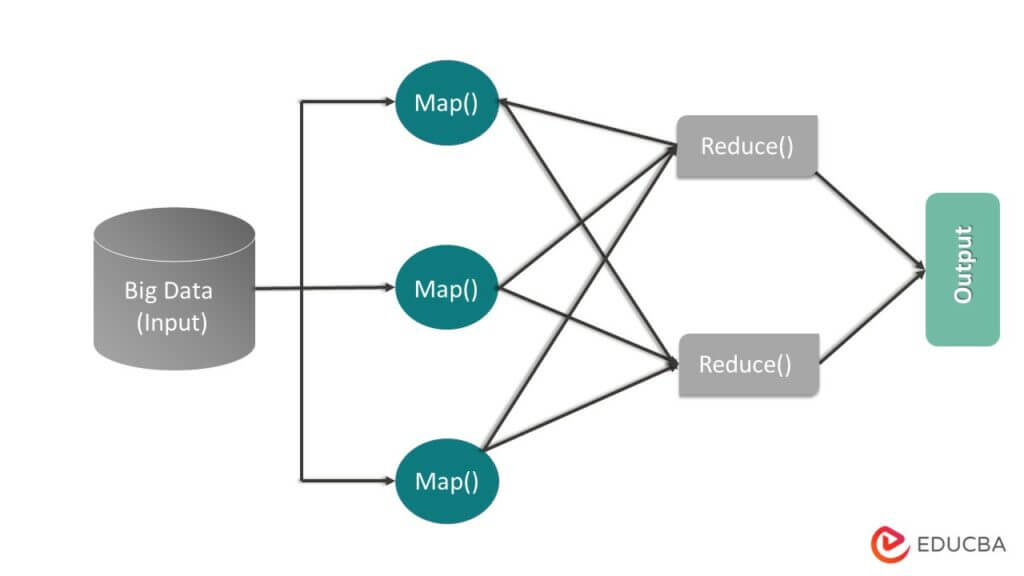
- The Map phase
During the Map phase, the system divides the input data, previously ingested and stored in the HDFS clusters, into smaller chunks. These are then processed parallelly in many nodes. The system then combines and sorts the results of these individual processings into key-value pairs, as indicated in the image by Key2-Value2. During the Reduce phase, the system further processes the sorted output from the Map phase to produce a final output result. Refer to the image below for a better understanding of the Map phase.
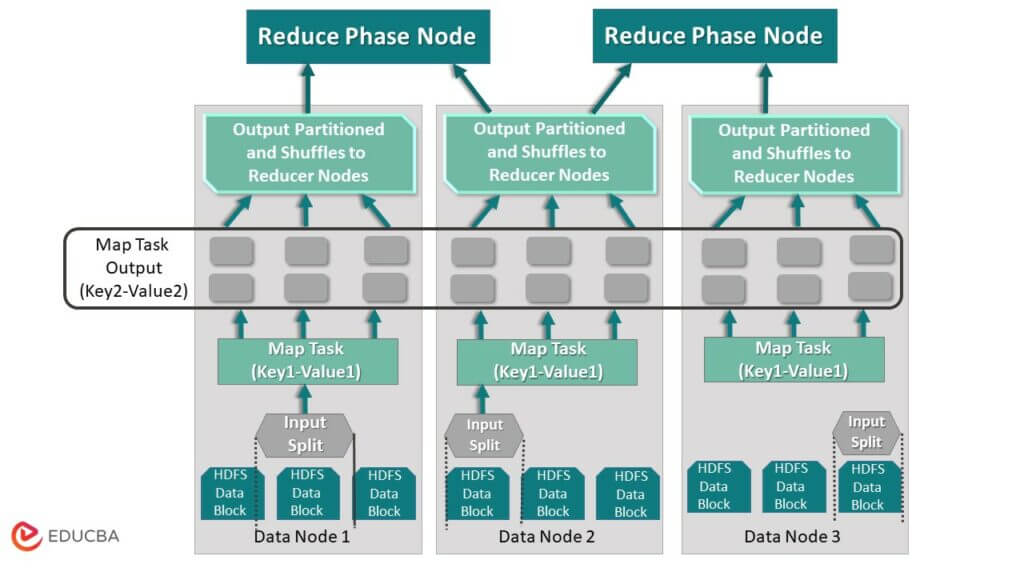
- The Reduce Phase
This is the second and last phase of the MapReduce processing framework. Reduce phase takes the outputs from the Map phase and conducts other functions like aggregation and summarization of the data. By default, the system stores the result of the Reduce phase in the HDFS clusters. This task, however, depends on the user’s choice and can be omitted altogether. Examine the image below that shows the processing of the map phase’s output by the reduce function, which could involve aggregation or summarization. The system stores the resulting data as replicas in the HDFS.
4) Common Utilities or Hadoop common
This is Hadoop’s fourth and last component, including Java files or libraries. It provides Hadoop with common tools that serve the functions of logging, security, networking, etc. All the other components of the Hadoop ecosystem use these utilities for running and maintaining the Hadoop clusters.
Data Replication
- The design of HDFS aims to process data quickly and reliably. It stores data across machines and in large clusters. The system stores all files in a series of blocks. The system replicates these blocks for fault tolerance. Users can decide the block size and replication factor, configuring them according to their requirements. By default, the replication factor is 3. You can specify the replication factor when creating the file and change it later.
- The name node makes all decisions regarding these replicas. The name node keeps sending heartbeats and block reports at regular intervals for all data nodes in the cluster. The receipt of the heartbeat implies that the data node is working properly. Block report specifies the list of all blocks present on the data node.

Placement of Replicas
- Replacing replicas is a critical task in Hadoop for reliability and performance. The system places all the different data blocks on other racks. Consider implementing replica placement based on reliability, availability, and network bandwidth utilization. You can spread the cluster of computers across different frames. You cannot place more than two nodes on the same rack. To ensure data reliability, you should place the third replica on a separate shelf.
- The two nodes on the rack communicate through different switches. The name node has the rack id for each data node. But placing all nodes on other shelves prevents data loss and allows bandwidth usage from multiple frames. It also cuts the inter-rack traffic and improves performance. Also, the risk of rack failure is significantly less than that of node failure. Reading data from two unique racks instead of three reduces the aggregate network bandwidth.
Advantages and Disadvantages of Hadoop Architecture
| Advantages of Hadoop | Disadvantages of Hadoop |
| A large amount of data can be stored and processed by breaking it into smaller chunks. | The Hadoop interface may be too difficult for novice developers to learn. |
| It is highly scalable since concurrent applications can run within the clusters, allowing multiple users to work simultaneously. | It may require additional hardware and infrastructure to implement. Making real-time data processing scalable may require investing in additional infrastructure. |
| It prevents data loss by replicating a data set three times. | Real-time data processing has a very limited scope. |
| Very cost-effective as compared to traditional data processing tools. | There are serious security concerns due to its open-source platform. |
| It is hosted on an open-source server and is constantly being updated by users and contributors. | Users need to have the expertise to utilize this properly. |
Conclusion
Thus, the Hadoop ecosystem’s vastness will continue to grow as subsequent version updates introduce new features. The reliability and the scope for scalable development of applications have drawn the developer and the tech communities towards Hadoop Architecture. It has long been the choice of computing platform for the companies such as Facebook, Google, Yahoo, LinkedIn, and many more.
Recommended Articles
This has been a guide to Hadoop Architecture. Here we have discussed the architecture, map-reduce, placement of replicas, and data replication. You can also go through our other suggested articles to learn more –
