Updated May 26, 2023
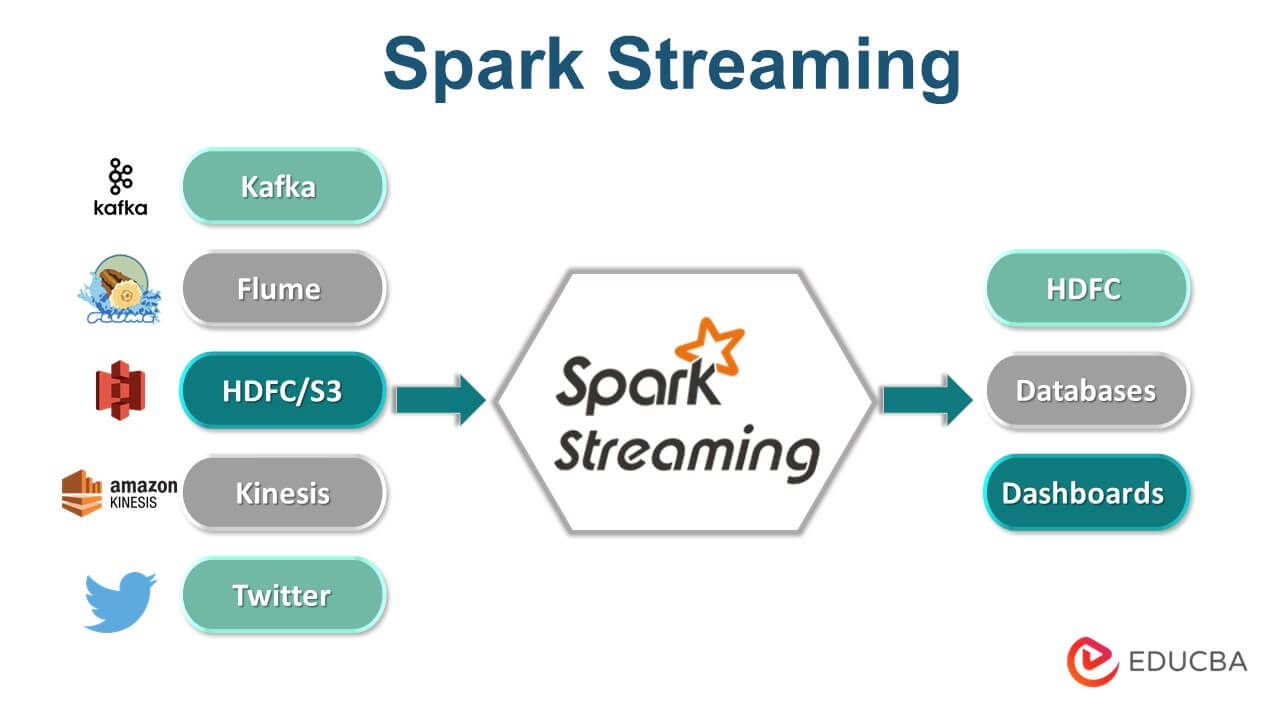
Introduction to Spark Streaming
Spark Streaming is defined as the extension of the Spark API, which is used to enable the fault-tolerant, high throughput, scalable stream processing; it provides a high-level abstraction called the discretized stream, a.k.a DStream, which includes operations such as Transformation on Spark Streaming( includes a map, flat map, filter, and union) and Update states of Key operation, as internally it works by receiving the live input data stream which is divided into batches, these batches are then used to get the final stream of the result by passing it in the Spark Engine.
How Spark Streaming Works?
- In Spark Streaming, the data streams are divided into fixed batches, also called DStreams, which is internally a fixed type sequence of the number of RDDs. Therefore, the RDDs are processed using by using Spark API, and the results returned, therefore, are in batches. The discretized stream operations, either stateful or stateless transformations, also consist of output operations, input DStream operations, and receivers. These Dstreams are the basic level of abstraction provided by Apache Spark streaming, a continuous stream of the Spark RDDs.
- It also provides the capabilities for fault tolerance to be used for Dstreams quite similar to RDDs so long as the copy of the data is available, and therefore any state can be recomputed or brought back to the original state by making use of Spark’s lineage graph over the set of RDDs. The point to be pondered here is that the Dstreams is used to translate the basic operations on their underlying set of RDDs. These RDD based transformations are done and computed by the Spark Engine. The Dstream operations are used to provide the basic level of details and give the developer a high level of API for development purposes.
Advantages of Spark Streaming
There are various reasons why the use of Spark streaming is an added advantage.
- Unification of stream, batch, and interactive workloads: The datasets can be easily integrated and used with any of the workloads, which were never easy to do in continuous systems. Therefore, this serves as a single-engine.
- Advanced level of analytics and machine learning and SQL queries: When working on complex workloads, it always requires the use of continuously learning and updated data models. The best part with this component of Spark is that it gets to easily integrates with the MLib or any other dedicated machine learning library.
- Fast failure and recovery for straggler: Failure recovery and fault tolerance is one of the basic prime features available in Spark streaming.
- Load balancing: The bottlenecks are often caused in between systems due to uneven loads and balances that are being done. Therefore, it becomes quite necessary to balance the load evenly, which is automatically handled by this component of Spark.
- Performance: Due to its in-memory computation technique, which makes use of the internal memory more than the external hard disk, the performance of Spark is very good and efficient when compared to other Hadoop systems.
Spark Streaming Operations
Below are the operations of Spark Streaming:

1. Transformation operations on spark streaming
The same way data is transformed from the set of RDDs here also the data is transformed from DStreams, and it offers many transformations that are available on the normal Spark RDDs. Some of them are:
- Map(): This is used to return a new form of Dstream when each element is passed through a function.
For Example, data.map(line => (line,line.count)) - flatMap(): This one is similar to the map, but each item is mapped to 0 or more mapped units.
For example, data.flatMap(lines => lines.split(” “)) - filter(): This one is used to return a new set of Dstream by returning the records which are filtered for our use.
Example, filter(value => value==”spark”) - Union(): It is used to return a new set of Dstream, which consists of the data combined from the input Dstreams and other Dstreams.
Example, Dstream1.union(Dstream2).union(Dstream3)
2. Update state by key operation
This allows you to maintain an arbitrary state even when it is continuously updating this with a new piece of information. You would be required to define the state, which can be of arbitrary type and define the state update function, which means specifying the state using the previous state and also making use of new values from an input stream. In every batch system, a spark will apply the same state update function for all the keys which are prevalent.
Example:
Code:
def update function (NV, RC):
if RC is None:
RC = 0
return sum(NV, RC) #Nv is new values and RC is running count
Conclusion
It is one of the most efficient systems to build the real streaming type pipeline and hence is used to overcome all the issues which are encountered by using traditional systems and methods. Therefore, all the developers who are learning to make their way into the spark streaming component have been stepping on the right single point of a framework that can meet all the developmental needs. Therefore, we can safely say that its use enhances productivity and performance in the projects and companies which are trying to or looking forward to making use of the big data ecosystem. I hope you liked our article. Stay tuned for more articles like these.
Recommended Articles
This is a guide to Spark Streaming. Here we discuss the introduction to spark streaming, how it works, along with advantages and operations. You can also go through our other related articles –
