Updated December 8, 2023
Definition of NLTK
NLTK is a popular Python framework for dealing with data of human language. It includes a set of text-processing libraries for classification and semantic reasoning, as well as wrappers for industrial-strength NLP libraries and an active discussion forum. NLTK is ideal for linguists, engineers, students, and industry users. NLTK is very useful in Python programming language. Nltk in Python, we can learn new things, nltk is very useful to learn new technology.
Linux and Windows users are using the NLTK. It is also a community-driven, free, open-source project. The abbreviation of nltk is natural language processing. It is a tool for teaching and working in computational linguistics with Python, according to one reviewer, and an amazing library to play with natural language, according to another. Python for Natural Language Processing is a hands-on introduction to language processing programming.

Table of Contents
Why Learn NLTK?
- Natural Language Toolkit can help us to learn new skills while also improving our NLP expertise. Professionals working in AI and NLP using Python will benefit from learning the library.
- It walks the reader through the principles of developing Python programs, dealing with corpora, and categorizing.
- It is a branch of computer science that focuses on creating a language of human-understandable to computers.
Installation Process
- That data must first be preprocessed before it can be analyzed programmatically. NLTK is a Python-based NLP toolbox. It gives us access to a number of text-processing libraries as well as a large number of test datasets.
- Tokenizing and parse tree visualization are only two of the things that NLTK can help us with.
- Steven Bird and Edward Loper of the University of Pennsylvania created a Python-based set of tools and programs used for statistical and symbolic language processing. The package offers graphical demos as well as sample data.
- Natural Language Toolkit is a Python module for NLP. Unstructured data with human-readable text makes up a large part of the data we could be examining.
- It is designed to aid research and teaching in natural language processing (NLP) and closely related fields such as empirical linguistics and machine learning.
- It has been effectively used as a teaching tool, a personal study tool, and developing research systems.
Below is the installation process as follows.
1) To install, our first pre-requisite is to check that Python is installed in our system. We are checking the Python installation by using the following commands are as follows.
Code:
python –version
pythonOutput:
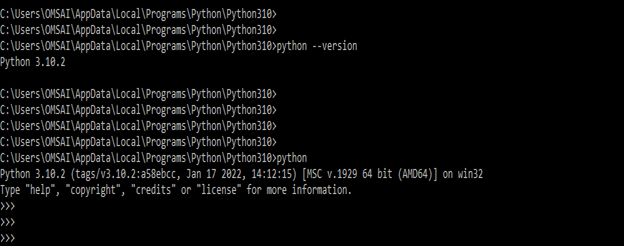
- In the above example, we can see that we have already installed the Python version of 3.10.2 in our system. So we have no need to install it again. Now we need to install it by using the pip command.
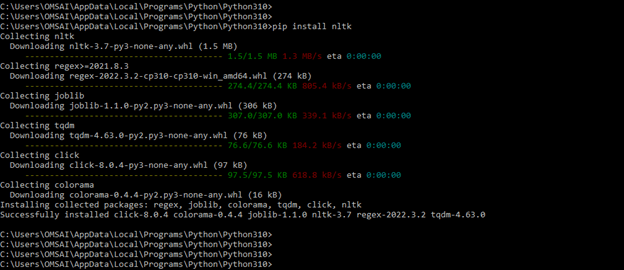
2) In the second step, we have to install the nltk by using the pip command. The below example shows an installation by using the pip command as follows. To install it in our system, we also need to install the dependency packages like regex, joblib, Colorama, tqdm. These packages will get automatically installed on our system; we have no need to install them separately.
Code:
pip install nltkOutput:
- We may easily divide up sentences or text words by tokenizing. It will allow us to work with chunks of text that are still cohesive and comprehensible even when taken out of context. It’s the initial step toward transforming unstructured data to be more easily analyzed.
- When analyzing text, we will tokenize by word and sentence. Here’s what each sort of tokenization has to offer.
Accessing and Processing
- To use nltk in our Python code, first, we need to import the nltk by using the import keyword. The below example shows how to import the nltk by using the import keyword as follows.
Code:
import nltkOutput:
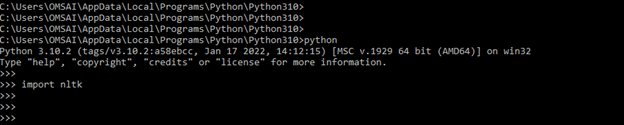
- In the above example, nltk has not issued any error, so we can say that it is successfully imported into our code.
- In this step, we have downloaded the required book or data by using the following command.
Code:
nltk.download()Output:
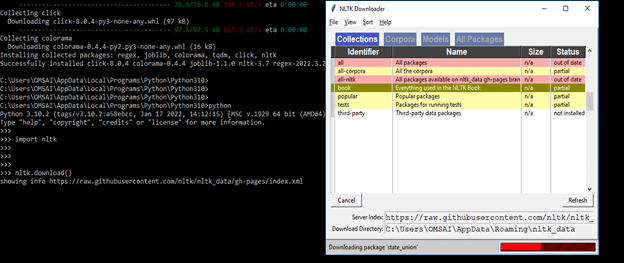
- We can use the Python interpreter to load part of the data once it has been downloaded to our machine. The first step is to type from nltk.book import * at the Python prompt, which instructs the interpreter to load.
- After downloading the book in this step, we are loading some contents of the book. The below example shows to load the content of the book as follows.
Code:
from nltk.book import *Output:
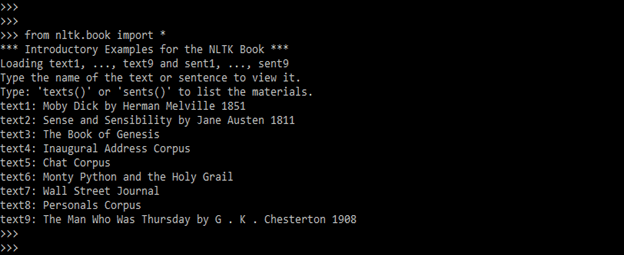
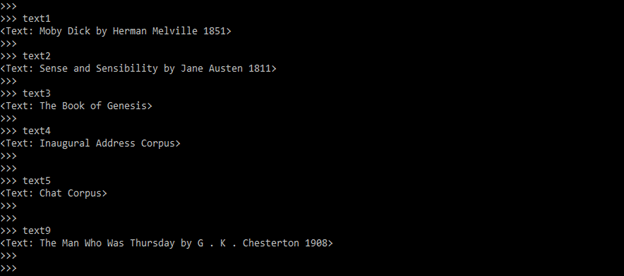
- To find the element of the text, we only need to enter the name of the text. The below example shows to find the element of the text as follows.
Code:
text1
text2
text3
text4
text5
text9Output:
- We can also count the vocabulary by using the len method. The below example shows counting vocabs as follows.
Code:
len (text1)
len (text2)
len (text9)Output:

NLTK Techopedia
- It is a toolkit for the Python programming language that was originally created for use in development and education by Steven Bird and Ewan Klein.
- It includes a hands-on approach that covers issues in Python programming, computational linguistics, and foundations, making it ideal for linguists with little or no programming experience, engineers, and researchers interested in computational linguistics, students, and educators.
- Lin’s Dependency Thesaurus is among the more than 50 corpora and lexical sources included in NLTK.
- It is a Python programming environment for working with human language data in NLP.
- It includes tokenization, parsing, categorization, stemming, tagging, and semantic reasoning text processing packages. It also comes with a recipe book and a book that describes the principles behind the core language as well as graphical examples and sample data sets.
Conclusion
NLTK is a branch of computer science that focuses on creating a language of humans understandable to computers. Natural Language Toolkit can help us to learn a new skill while also improving our NLP expertise. Professionals working in AI and NLP using Python will benefit from learning the NLTK library.
Recommended Articles
We hope that this EDUCBA information on “NLTK” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

