Updated February 18, 2023

Introduction to NLTK Tokenize
NLTK tokenize is the process of breaking down a sentence into a word list called tokens. Tokenization can be done in several ways. We can say that NLTK tokenization is breaking down a big amount of text into smaller chunks known as tokens. These tokens are extremely valuable for pattern recognition and are used as a foundation for lemmatization and stemming.
What is NLTK Tokenize?
- Tokenization can also be used to replace sensitive data with non-sensitive data. Text classification, intelligent chatbots, and other applications rely on natural language processing. To attain the goal mentioned above, it’s critical to comprehend the text’s pattern.
- While working with data, tokenization is a common activity for data scientists. It entails breaking down a large text into little tokens. Tokenization is the initial stage in most Natural Language Processing (NLP) projects because it is the foundation for building strong models and aids in better understanding the text.
- Although writing split to tokenize in Python is straightforward, it is not efficient in some situations.
- For the time being, don’t worry about lemmatization; instead, think of them as steps in cleaning textual data with NLP.
- NLP is used in tasks like text classification and spam filtering and deep learning libraries like Keras and Tensorflow.
- The NLTK tokenize sentences module, which comprises sub-modules, is a key part of the Natural Language Toolkit.
- To separate a statement into words, we call the method word to tokenize. Then, the word tokenization result can be transformed into a Data Frame for enhanced applications.
- It can also be a starting point for text cleaning operations, including punctuation removal and stemming. Finally, to train and generate a prediction, machine learning models require numerical data.
- The nltk.word tokenize method will be used to tokenize words and sentences with NLTK. NLTK Tokenization is a method of breaking down vast data into smaller chunks to analyze the text’s character.
- NLTK is used to train machine learning models and clean up text in Natural Language Processing.
How to Use NLTK Tokenize?
With NLTK, tokenized words and phrases can be vectorized and transformed into a data frame. Tokenization with the Natural Language Tool Kit (NLTK) entails stemming and the training of machine learning algorithms.
Toolkit for Natural Language the tokenization module “tokenize” is available in Python Library. Two types of tokenization functions in the NLTK “tokenize” package.
Words tokenization with the Natural Language Tool Kit entails parsing a text into words using the Natural Language Tool Kit. Follow the instructions below to tokenize words using NLTK. The below steps show how to use it as follows.
- Import module.
from nltk.tokenize import word_tokenize
- Fill a variable with the text. The below example shows the fill the variable with text.
py_word = "Python nltk tokenize steps"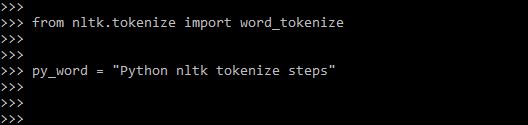
- For the variable, use the “word tokenize” function.
print (word_tokenize(py_word))
- Take a look at the tokenization result.

To use tokenize in python code, first, we need to import the tokenize module; after importing, we can use this module in our program. The example below shows how to import the word_tokenize module into our code.
Code:
from nltk.tokenize import word_tokenize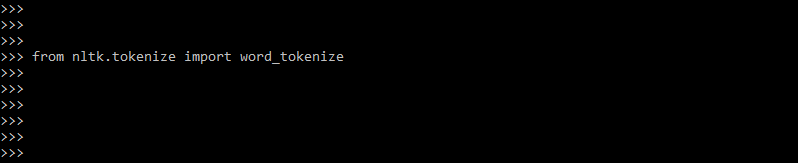
The example below shows how we can use it in our code. In the example below, first-line, we have imported the word_tokenize module using nltk.tokenize module.
After importing the module in the next line, we have to create the object of word tokens; after creating the object in the next line, we printed this object using the print method.
We have created object of word with name as py_word are as follows.
Code:
from nltk.tokenize import word_tokenize
py_word = "Python nltk tokenize"
print (word_tokenize(py_word))
NLTK Tokenize Words
Sent tokenize a sub-module of NLTK tokenize. Sentence tokenization is necessary for NLTK tokenize module. We will need both the NLTK sentence and word tokenizes to determine the ratio. Output is useful for machine learning. Tokens refer to each component.
To tokenize a sentence, use the sent tokenize function. It uses the nltk.tokenize.punkt module’s ‘PunktSentenceTokenizer’ instance. In the below example, we have used the word_tokenize module.
Code:
from nltk.tokenize import word_tokenize
py_token = "python nltk tokenize words"
print (word_tokenize(py_token))
In the above example, we can see that first, we have imported the module name as word_tokenize from nltk.tokenize.
After importing the module, we have provided multiple words in sentences. Then, we have created the object of those words. Next, we created the word sentence’s object as py_token. Then we print the object using the word_tokenize module and print method.
NLTK Tokenize Code
To run the NLTK tokenize code, we need to install NLTK in our system. The below example shows to install the NLTK by using the pip command.
pip install nltk
The above example shows that NLTK is already installed in our system, showing that the requirement is already satisfied. In the below example, we have created the object of the word sentence name as py_token.
The below example is as follows.
Code:
from nltk.tokenize import sent_tokenize
py_token = "Python nltk tokenize code"
print(sent_tokenize(py_token))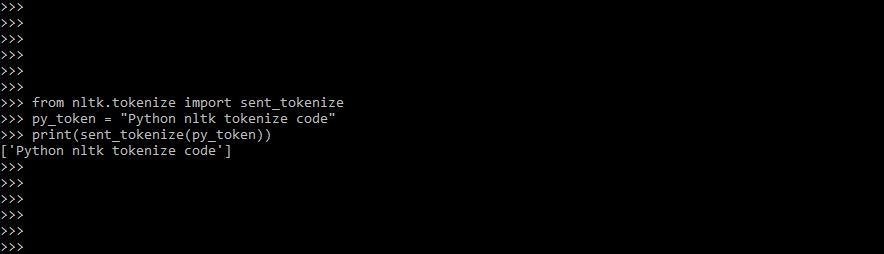
Program
The NLTK must be installed on our system to run the python program. The NLTK module is a large toolkit designed to assist us with many aspects of NLP. For example, a token is nothing but a component of whatever has been divided up according to rules. When any sentence is tokenized into words, each word, for example, is a token if we tokenize the sentences from a paragraph.
The below programs are as follows.
Code:
from nltk.tokenize import sent_tokenize, word_tokenize
py_word = "Nltk tokenize program"
print (sent_tokenize(py_word))
print (word_tokenize(py_word))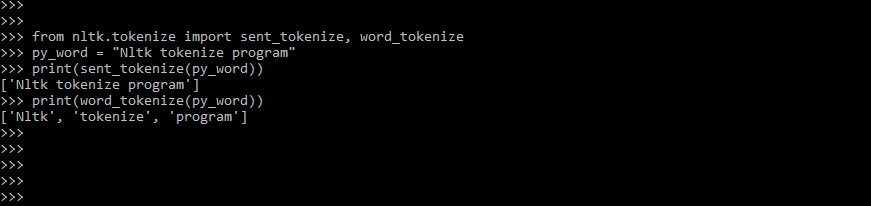
Conclusion
The NLTK tokenize sentences module, which comprises sub-modules, is a key part of the Natural Language Toolkit. It is breaking down a sentence into a word list called tokens. Tokenization can be done in several ways.
Recommended Articles
This is a guide to NLTK Tokenize. Here we also discuss the definition and how to use NLTK Tokenize along with code implementation and programs. You may also have a look at the following articles to learn more –

