
Introduction to NLTK Corpus
NLTK Corpus package modules contain utilities for reading corpus files in various formats. These functions can read both the NLTK corpus files and external corpus files. In addition, every corpus module has one or more corpus reader functions used for corpus document reading. These routines require an item parameter that specifies which document from the corpus should be read. If the item contains a filename, it will be opened.
What is NLTK Corpus?
- The appropriate document from the NLTK corpus package will be loaded into the corpus module’s items variable.
- Additionally, corpus reader methods can take lists of item names, which will return the relevant documents’ concatenation.
- The nltk.corpus package contains a set of class readers that can retrieve the contents of various corpora.
- Each class of corpus readers is tailored to a particular corpus format. Furthermore, the nltk.corpus package offers instances of corpus reader, which was used for accessing the corpora included in the NLTK data package.
- The Corpus Reader Classes analyses the challenges that arise when building the new object of corpus reader classes.
- A corpus is a vast and organized series of texts in linguistics. They are used in corpus linguistics to test hypotheses, check for occurrences, and validate linguistic rules within a language territory.
- The class of corpus readers is tailored to work with a particular corpus format. Furthermore, the nltk.corpus package produces a set of corpus reader instances.
- It is a repository of data sets that were well worth investigating. All corpus of nltk have the same access rules when using the NLTK module, but nothing about them is magical.
- Most files are plaintext, but some are XML, and others are in various formats. We can access them manually or using the module and python. Let’s talk about manually seeing them.
- Our nltk data directory could lurk in various places depending on our setup. To find it, navigate our directory of python.
- NLTK is a package of standard python with ready-to-use functions and utilities. It’s one of the most popular computational linguistics and natural language processing libraries.
- The nltk corpus samples, like the pyplot package from matplotlib – matplotlib.pyplot is accessed using the notation of dot. We need to employ nltk-specific functions, which is a significant difference.
- We can acquire a list of nltk’s sample Gutenberg corpus datasets using the file ids function and the dotted notation.
How to Use NLTK Corpus?
A corpus is a collection of papers written in the same language. It will be a collection of text files stored in a directory, frequently surrounded by other text file directories. In the nltk.data.path variable, NLTK has already defined data paths of directories or lists. For NLTK to find our custom corpora, it must be present in one of these pathways. We may also create a custom nltk data directory and ensure it’s included in the nltk.data.path list of known paths.
Below is the corpus’s reader function, which was named based on the type which information they were returning.
- Word: The return type of word function is a list of str.
- Sents: The return type of the sents function is a list of (list of str).
- Paras: The return type of paras function is a list of (list of (list of str)).
- Tagged_words: The return type of the tagged_words function is a list of the (str, str) tuple.
- Tagged_sents: The return type of the tagged_sents function is a list of (list of (str, str)).
- Tagged_paras: The return type of tagged_paras function is list of (list of (list of (str, str))).
- Chunked_sents: The return type of the chunked_sents function is a list of (Tree w/ (str, str) leaves).
- Parsed_sents: The return type of the parsed_sents function is a list of (Tree with str leaves).
- Xml: The return type of xml function is a single element tree of xml.
- Raw: The return type of basic function is the content of the corpus.
To use words NLTK corpus, we need to follow the below steps as follows:
1. Install nltk by using the pip command.
- The first step is to install NLTK by using the pip command.
- The below example shows to install nltk by using the pip command as follows.
Code:
pip install nltkOutput:
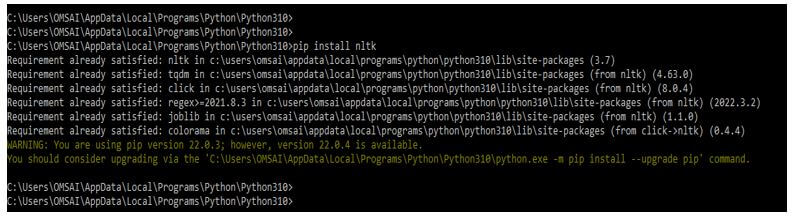
2. After installing the pip command, we log into the python shell using the python command.
Code:
pythonOutput:

3. After login into the python shell, in this step, we are importing the nltk.corpus module in our program by using the import keyword.
Code:
from nltk.corpus import brownOutput:
4. After importing the module in the next step, we print the list as per function.
Code:
print(", ".join(brown.raw ()))
print(", ".join(brown.words ()))Output:
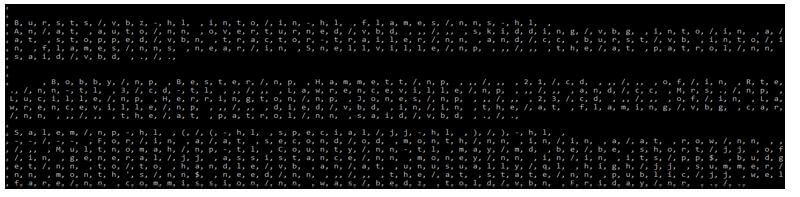

In the above step, we can see that it will print the list as per the function we used in the print method. In the above example, we have used basic and words function, so it will print the data as per functions.
Examples of NLTK Corpus
Different examples are mentioned below:
Example #1
The below example shows the NLTK corpus as follows. In the below example, we use the words function to print the data as follows.
Code:
from nltk.corpus import indian
for py_text in indian.fileids ():
print(py_text, indian.words (py_text)[:10])Output:
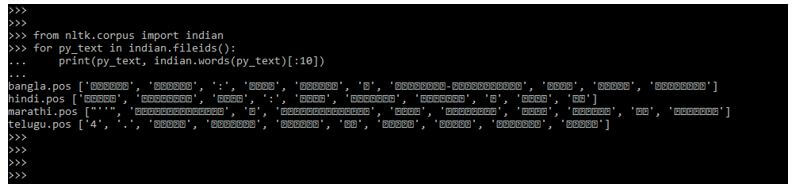
In the above example, the first line we have imported nltk.corpus packages. Using the imported object, we used the loop in the second line. Finally, in the third line, we have used the words function to print the list.
Example #2
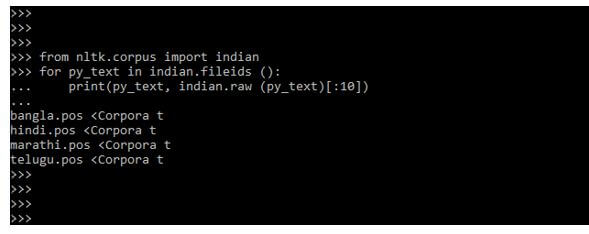
We are using the basic function to print the data in the example below. Likewise, we are using the basic function to print the output.
Code:
from nltk.corpus import indian
for py_text in indian.fileids ():
print(py_text, indian.raw (py_text)[:10])Output:
Conclusion
The nltk.corpus package offers instances of corpus reader, which was used for accessing the corpora included in the NLTK data package. In addition, package modules contain utilities for reading corpus files in various formats. These functions can read both the corpus files and external corpus files.
Recommended Articles
This is a guide to NLTK Corpus. Here we discuss the introduction, examples, and how to use the NLTK corpus. You may also have a look at the following articles to learn more –

