Updated March 13, 2023

What is NLP in Python?
A technical branch of computer science and engineering dwelling and also a subfield of linguistics, which leverages artificial intelligence, and which simplifies interactions between humans and computer systems, in the context of programming and processing of huge volumes of natural language data, with Python programming language providing robust mechanism to handle natural language data, and implement natural language processing easily, through its various functionalities including various libraries and functions, is termed as NLP (natural language processing) in Python.
How NLP Works in Python?
It is very complex to read and understand English.
The sentence below is an example of difficulty for the computer to comprehend the sentence’s actual thought.
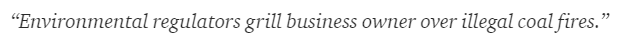
In Machine Learning, a pipeline is built for every problem where each piece of a problem is solved separately using ML. The final result would be the combination of several machine learning models chained together. Natural Language Processing works similar to this, where the English sentence is divided into chunks.

There are several facts present in this paragraph. First, things would have been easy if computers themselves could understand what London is, but for doing so, the computers need to be trained with written language basic concepts.
1. Sentence Segmentation – The corpus is broken into several sentences like below.

This would make our life easier as it is better to process a single sentence than a paragraph as a whole. The splitting could be done based on punctuations or several other complicated techniques that work on uncleaned data.
2. Word Tokenization – A sentence could further be split into the token of words as shown below.
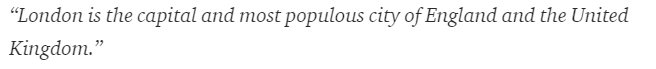
After tokenization, the above sentence is split into –
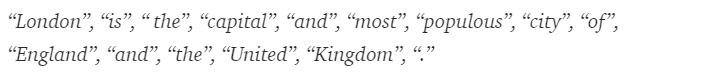
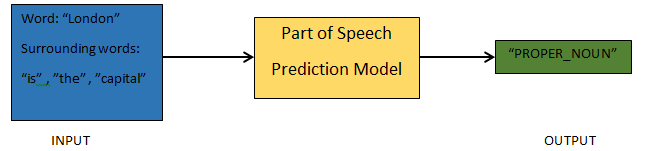
3. Parts of Speech Prediction – This process is about generating the parts of speech for each token. This would enable us to understand the meaning of the sentence and the topic that is talked about in the sentence.
4. Lemmatization – A word in a sentence might appear in different forms. Lemmatization tracks a word back to its root, i.e., the lemma of each word.
5. Stop words Identification – There are a lot of filler words like ‘the’, ‘a’ in a sentence. These words act like noise in a text whose meaning we are trying to extract. Thus it is necessary to filter out those stop words to build a better model.

Based on the application, the stop words could vary. However, there is a pre-defined list of stop works one could refer to.
6. Named Entity Recognition – NER is the process of finding entities like name, place, person, organization, etc., from a sentence.

The context of the appearance of a word in a sentence is used here. To grab structured data out of the text, NER systems have a lot of uses.
Example of NLP in Python
Most companies are now willing to process unstructured data for the growth of their business. As a result, NLP has a wide range of uses, and of the most common use cases is Text Classification. The classification of text into different categories automatically is known as text classification. The detection of spam or ham in an email and the categorization of news articles are common examples of text classification. The data used for this purpose need to be labeled.
The few steps in a text-classification pipeline that needs to be followed are:
- The loading and the pre-processing of the data is the first step, and then it would be split into a train and validation set.
- The Feature Engineering step involves extracting the useful features or creating additional meaningful features to develop a better predictive model.
- To build the model, the labeled dataset is used to train the model.
Pandas, Scikit-learn, XGBoost, TextBlog, Keras, are a few of the necessary libraries we need to install. Then we would import the libraries for dataset preparation, feature engineering, etc.

The data is huge, with almost 3.6 million reviews that could be downloaded from here. A fraction of the data is used. It is download and read into a Pandas data frame.

The target variable is encoded, and the data is split into train and test sets.

Feature engineering is performed using the below different methods.
1. Count Vectors
The count vectors achieve the representation of a document, a term, and its frequency from a corpus.

2. TF-IDF Vectors
In a document, the relative importance of a term is represented by the Term Frequency (TF) and the Inverse Document Frequency (IDF) score.
The TF-IDF could be calculated by:

The TF-IDF vectors could be generated by Word-level, which presents the score of every term, and the N-gram level, which is the combination of n-terms.

3. Word Embedding
The representation of documents and words in the form of a dense vector is known as word embedding. There are pre-trained embedding such as Glove, Word2Vec which could be used, or it could be trained as well.

4. Topic Models
The group of words from a document carries the most information. The Latent Dirichlet Allocation is used here for topic modeling.

The mode is built after the feature engineering is done and the relevant features have been extracted.

5. Naive Bayes
It is based on Bayes Theorem, and the algorithm believes that there is no relationship among the features in a dataset.


6. Logistic Regression
It measures the linear relationship between the features, and the target variable is measured based on a sigmoid function which estimates the probabilities.


7. Support Vector Machine
A hyperplane separates two classes in an SVM.

![]()
8. Random Forest Model
An ensemble model where reduces variance and bags multiple decision trees together.


9. X G Boost
Bias is reduced, and weak learners converted to strong ones.




How would NLP help you in your Career?
Natural Language Processing is a booming field in the market, and almost every organization needs an NLP Engineer to help them process the raw data. Thus it’s imperative to master the skills required as there would be no shortage of jobs in the market.
Conclusion
In this article, we started off with an introduction to NLP in Python and then implemented one use case in Python to show how to work with NLP in Python.
Recommended Articles
This has been a guide to NLP in Python. Here we discussed the example, use cases, and how to work with NLP in Python. You can also go through our other suggested articles to learn more –

