Updated February 14, 2023
Introduction to XPath Selector
Xpath selector is used to select the nodes from an xml document. As we know that the xpath language is used for selecting the nodes from the documents of xml, we can also use the same in css or html. The xpath selector is the xml path selector; basically, the xpath is the query language that helps identify the xml document. It uses the expression navigate in xml.

What is XPath Selector?
It allows us to navigate the DOM when looking for elements for the scrape test. It is compatible with the old browsers; creating the xpath selector is easier compared to the css selector. When we don’t know the name of an element, we can use the search for possible matches. It uses the type of tree diagram flows. It is a path of XML, which was used to navigate from the structure of html page. It is beneficial and essential in the xml documents.
When to Use XPath Selector?
The use of the xpath selector depends on the context which we are using in our code. However, it is a potent tool for accessing the web elements and the entire DOM.
The below points show how we can use the xpath selectors as follows:
- It is faster than the other selectors we are using in xpath.
- It is straightforward to understand, and the syntax of the xpath selector is more readable.
- We can easily use the xpath selector in our development. It is doing everything which was the other selectors were doing.
- At the time of describing a presentation of documents written in a markup language such as html or xml. It explains how html documents are displayed on the screen.
- It adds variations, designs, and layouts to display the different device sizes of the screen.
- We can use it in cases where we only need to support the type of xpath selector.
- If suppose while using css selector, most of the browser is not supporting the css selector at the same time we are using xpath selectors.
- For doing the task which was only supported by xpath-like element finding, which is moving back to DOM, we are using xpath selectors.
It is used in xml path language; xpath is the query language used to select the nodes from the xml document. Finding the element based on the id of xpath works well, and it is more flexible. Xpath expression is similar while working with the traditional computer system.
We use chrome and firefox browsers with xpath selectors for fined tuning performance. It operates faster on IE 11. Using it, we can search elements backward and forward into the hierarchy of DOM. Using the xpath locator, we can locate the parent element by using the elements of the child. All the browser’s table traversal and nested sibling traversal are done using xpath ID.
Using XPath Selector
It is used to locate an element on a webpage; observe point is used to find the item for clicking and entering the text into and doing other transactions. The default selector in xpath is the ID element, but we can also use the alternate selector to increase where we have no ID element in the target. For example, if we suppose to know the element of XPath, then we can find the same using developer tools. We can find the xpath selector by inspecting an element. We can find it by using the xpath ID.
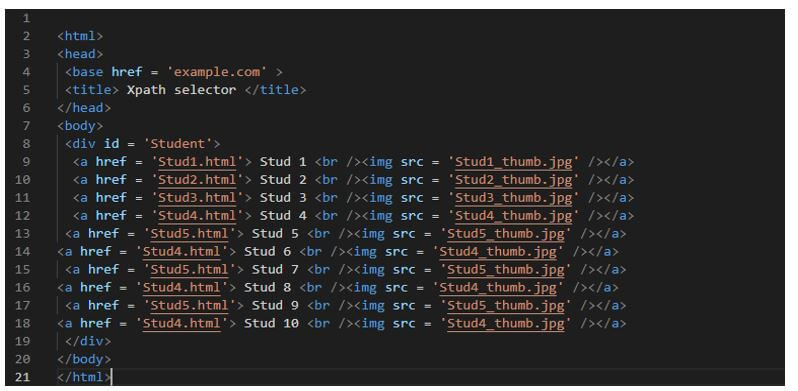
In the example below, we are creating the html file to use the xpath selector; in the html file, we are defining the stud images as follows.
Code:
<html>
<head>
<base href = 'example.com' >
<title> Xpath selector </title>
</head>
<body>
<div id = 'Student'>
<a href = 'Stud1.html'> Stud 1 <br /><img src = 'Stud1_thumb.jpg' /></a>
<a href = 'Stud2.html'> Stud 2 <br /><img src = 'Stud2_thumb.jpg' /></a>
<a href = 'Stud3.html'> Stud 3 <br /><img src = 'Stud3_thumb.jpg' /></a>
<a href = 'Stud4.html'> Stud 4 <br /><img src = 'Stud4_thumb.jpg' /></a>
<a href = 'Stud5.html'> Stud 5 <br /><img src = 'Stud5_thumb.jpg' /></a>
<a href = 'Stud4.html'> Stud 6 <br /><img src = 'Stud4_thumb.jpg' /></a>
<a href = 'Stud5.html'> Stud 7 <br /><img src = 'Stud5_thumb.jpg' /></a>
<a href = 'Stud4.html'> Stud 8 <br /><img src = 'Stud4_thumb.jpg' /></a>
<a href = 'Stud5.html'> Stud 9 <br /><img src = 'Stud5_thumb.jpg' /></a>
<a href = 'Stud4.html'> Stud 10 <br /><img src = 'Stud4_thumb.jpg' /></a>
</div>
</body>
</html>Output:
The document is broken down into elements representing the skeleton in a full path selector. To go from top to bottom from the resulting document, every node makes the xpath shorter.
Element
As we know, xpath is the language used to query documents. The element is used in xml as well as html documents. The xpath selectors element allows the tester to navigate the structure of xml for any document. An element consists of path expression along with the conditions.
Below is the syntax of xpath as follows:
Syntax:
Xpath = //name_of_tag [@attrubute_name = 'value_of_attribute']The “//” parameter is used to select the current node. The tag name is the name of the tag for a particular node. We can also use the attribute name and value of an attribute in xpath.
Different elements are mentioned below:
| Sr. No | Xpath Selector Element |
Description |
| 1 | //* | Defines all elements |
| 2 | //p | Defines all p elements |
| 3 | //p/* | Defines all child elements |
| 4 | //*[@id = ‘’] | Defines element by ID |
| 5 | //*[contains(@class, ‘’)] | Defines element by class |
| 6 | //*[@title] | Defines element with attribute |
| 7 | //p/*[0] | Defines first child with all p |
| 8 | //p[a] | Defines all p with a child |
| 9 | //p/following-sibling:: *[0] | Defines the next element |
| 10 | //p/preceding-sibling:: *[0] | Defines the previous element |
Conclusion
It is compatible with the old browsers; creating the xpath selector is easier compared to the css selector. It is used to select the nodes from xml documents as we know that xpath language is used for determining the nodes from the documents of xml.
Recommended Articles
This is a guide to XPath Selector. Here we discuss the introduction, XPath selector element, and use for better understanding. You may also have a look at the following articles to learn more –
