Updated April 18, 2023

Definition of XPath Ancestor
The ancestor axis chooses all of the current node’s ancestor elements (parent, grandparent, great-grandparents, and so on). The root node is always present on this axis (unless the current node is the root node). All nodes that are ancestors, or the parent, and the parent’s parent, and so on, are selected by the ancestor-or-self axis, including the node in reference. In this article, we will learn how to fetch the ancestor details in Xpath and will see the working model of the respective functionality.
Syntax:
The Syntax of Xpath Ancestor is given below:
//ancestor::tagname
How XPath ancestor works?
A pattern that picks a set of XML nodes is specified by an XPath expression. An XPath expression’s nodes refer to more than simple elements. Text and characteristics are also mentioned. This axis shows all of the ancestors of the context node, all the way up to the root node. The parent axis (parent: 🙂 denotes the context node’s parent. ../X should not be confused with the expression parent::X. If the parent of the context is X or empty, the former will yield a sequence of exactly one element. The latter is a shortcut for parent: node( )/X, which selects all siblings of the context node named X, including the context itself.
To brief it again, In XPath, the ancestor axis is used to pick all of the current node’s parent (and parent of the parent) items. It’s useful in situations where we can recognise the child element’s node but not its parent or grandparent nodes. In these cases, we can utilise the child node as a reference point and recognise the parent node using the “ancestor” axis. Take a look at the following illustration. Let’s imagine we want to find the user form on the webpage “https://examturf.com/login,” but we can’t because of its dynamic features. However, we can see the “Username” label on the website. The ancestor axis can be used to locate the parent node in this case.
Xpath Expression is given as:
//label[text()='Username']
However, we need to find the <wrap tag, which is two levels above this element. Let’s create an XPath expression to find the wrap node.
//label[text()='Username']/ancestor::wrap
We used XPath to detect the child node first, and then the ancestor axis to get the form node. One thing to remember is that if there are multiple parent nodes with the same tag, the same XPath will detect numerous separate items. To write any axes method from the current method give a Slash (/) then write the specific axes method then place two colons. To inspect all the labels in the form or whose type is text. Then write it has
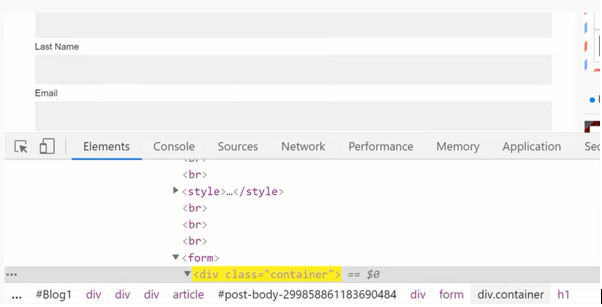
//div[@class =’container’] / child::input
Following is an Example of Xpath Expression
Imagine we have an XML file like:
<Top>
<aa id="0">
<st attr="vl"/>
<aa id="11">
<st attr="xxx"/>
</aa>
<aa id="12">
<st attr="vl">
<child1>ab</child1>
<child2>
<child3>ca</child3>
</child2>
</st>
</aa>
</aa>
</Top>
A valid Xpath Statement for the context node is given as :
./ancestor::aa[str[@attr='vl']][position() = 11]
So here an Ancestor <aa> with the predicates is displayed.
All of a node’s ancestors are traversed by the ancestor and ancestor-or-self axes. All div elements that are ancestors of the context node are returned by the following expression:
Ancestor::div
Examples
Let us understand the concept with an example in the following sections:
Example #1
<!DOCTYPE html>
<html>
<body>
<div class="Department" align="center">
<h2>College</h2>
<div class="Science" align="left" >
<h3 align="left">Scientific Mechanism</h3>
<div class="Laws" white-space=:pre>
<h4 >Newton Law</h4>
</div>
<div class="Electronics">
<h4>Wave Length</h4>
<div class="Communication">
<h5>Electronic Waves</h5>
</div>
<div class="Digital">
<h5>Logical Circuit</h5>
<div class="Circuits">
<h6>Devices</h6>
</div>
<div class="EMF">
<h6>Force</h6>
</div>
</div>
</div>
<div class="Mechanical">
<h4>Drawing Graphical</h4>
</div>
</div>
<div class="Automobile">
<h3>Engine Sections</h3>
<div class="Oil Dept">
<h4>Insect</h4>
</div>
<div class="Mechanical Force">
<h4>Force and Torque </h4>
</div>
</div>
</div>
</body>
</html>
Explanation
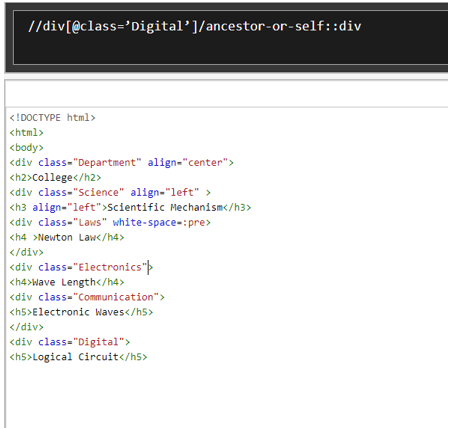
For an Xpath Expression
//div[@class='Digital']/ancestor-or-self::div
Output:
Example #2
pp.xml
<?xml version="1.0" standalone="yes"?>
<prodinfo>
<prod id="1">
<name>MAC VINEY</name>
<Origin State="USA" Year="4 year">Face products</Origin>
<email>[email protected]</email>
</prod>
<prod id="2">
<name>Olay Primee</name>
<Origin State="Canada" Year="10 year">Cosmetics</Origin>
<email>[email protected]</email>
</prod>
<prod id="3">
<name>Maybelline</name>
<Origin State="Thailand" Year="15 year">Skinny</Origin>
<email>[email protected]</email>
</prod>
</prodinfo>
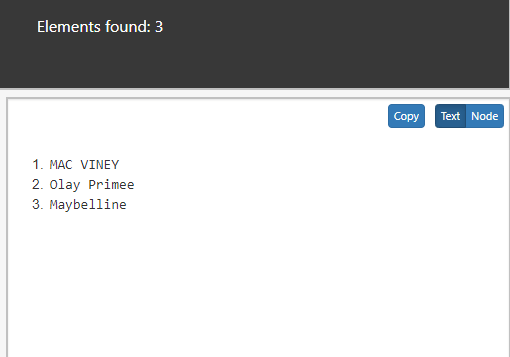
//name/self::*
Output:
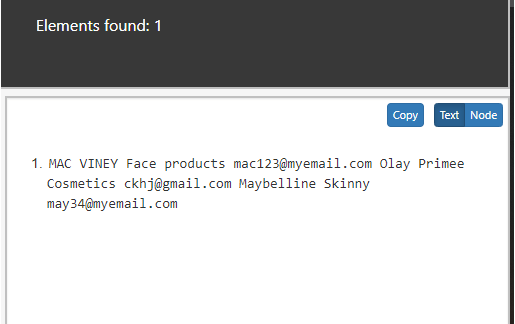
2. Select all ancestor node of the Prod node.
//prod/ancestor::*
Output:
3.
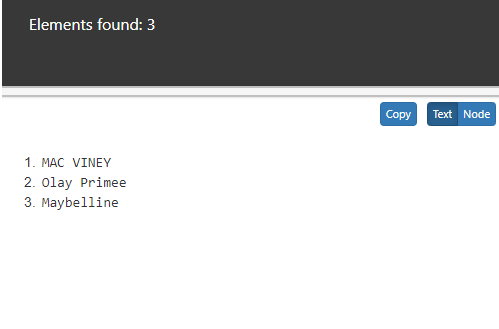
//ancestor::name
Output:
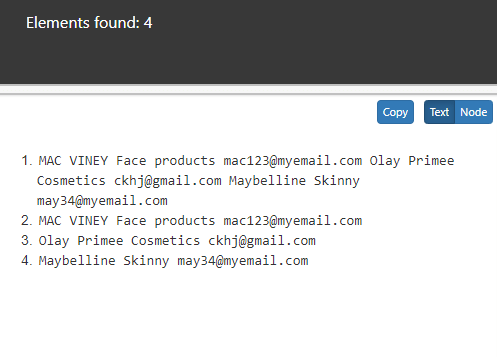
4. Select all of the employee nodes’ ancestors, as well as the context node itself.
//prod/ancestor-or-self::*
Output:
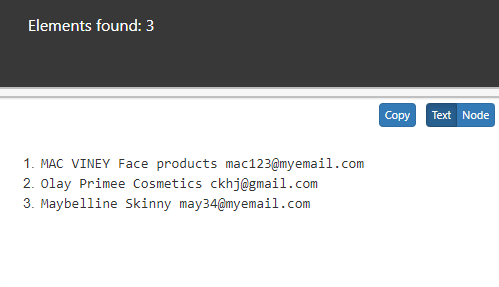
5. With the context node itself, choose all ancestor of Name node.
//name/ancestor-or-self::prod
Output:
Example #3
trav.xml
<?xml version="1.0" encoding="UTF-8"?>
<Travellers>
<Traveller>
<UId>4567</UId>
<uname>
<FName>Lesta</FName>
<LName>Olivia</LName>
<Sname>Gullsal</Sname>
</uname>
<Residence>
<City>German</City>
<Country>Europe</Country>
</Residence>
<Sex>Male</Sex>
<DateOfBirth>02/06/1980</DateOfBirth>
<Email>[email protected]</Email>
</Traveller>
<Traveller>
<UId>2345</UId>
<uname>
<FName>Prathap</FName>
<LName>Davidson</LName>
<Sname>Kaelvon</Sname>
</uname>
<Residence>
<City>Mumbai</City>
<Country>India</Country>
</Residence>
<Sex>Male</Sex>
<DateOfBirth>08/06/1985</DateOfBirth>
<Email>[email protected]</Email>
</Traveller>
</Travellers>
Ancestor.java
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import java.io.IOException;
public class Ancestor {
private static DocumentBuilderFactory buf = DocumentBuilderFactory.newInstance();
private static DocumentBuilder bur = null;
private static XPath xP = null;
private static Document doc = null;
public static void main(String q[]) {
try {
bur = buf.newDocumentBuilder();
doc= bur.parse(Ancestor.class.getResourceAsStream("https://cdn.educba.com/trav.xml"));
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
xP = XPathFactory.newInstance().newXPath();
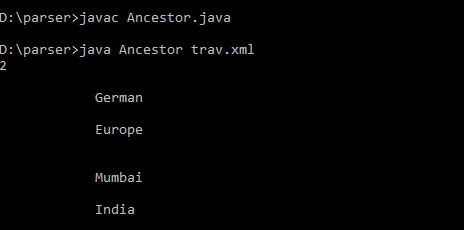
String expression = "//Country/ancestor::Residence";
try {
NodeList nod= (NodeList) xP.compile(expression).evaluate(doc, XPathConstants.NODESET);
System.out.println(nod.getLength());
System.out.println(nod.item(0).getTextContent());
System.out.println(nod.item(1).getTextContent());
System.out.println(nod.item(3).getTextContent());
} catch (XPathExpressionException e) {
e.printStackTrace();
}
}
}
Explanation
Above is the java file which use XPath expression to extract node information from the XML file. Now we’ve declared a class called Ancestor, and we’re using JAXP to parse the XML file. To begin, we must load the document into the DOM Document object. That trav.xml file is now in the current working directory. Here the Ancestor node is targeted from which a textual content is extracted and when we execute the Ancestor.java below is the generated output.
Output:
Conclusion
Using its functions and axes, XPath can even locate elements in a dynamic web context, making it one of the most common Selenium locators’ strategies. Coming to an end we have seen ancestors’ concepts with an example. We can use the XPath functions and axes to select appropriate XPath for uniquely locating elements on a web page in this manner.
Recommended Articles
This is a guide to XPath Ancestor. Here we discuss Definition, syntax, How XPath ancestor works, examples with code implementation respectively. You may also have a look at the following articles to learn more –
