Updated March 21, 2023

Overview of Spark Stages
Spark stages are the physical unit of execution for the computation of multiple tasks. The Spark stages are controlled by the Directed Acyclic Graph(DAG) for any data processing and transformations on the resilient distributed datasets(RDD). There are mainly two stages associated with the Spark frameworks such as, ShuffleMapStage and ResultStage. The Shuffle MapStage is the intermediate phase for the tasks which prepares data for subsequent stages, whereas resultStage is a final step to the spark function for the particular set of tasks in the spark job. ResultSet is associated with the initialization of parameter, counters and registry values in Spark.
The meaning of DAG is as follows:
- Directed: All the nodes are connected to one another creating an acyclic graph. The sequence of this is determined by the actions called on the RDD.
- Acyclic: The nodes are not connected as a cyclic loop i.e. if an action or a transformation was once done cannot be reverted back to its original value.
- Graph: The entire pattern formed by the edges and vertices arranged together in a specific pattern is called a graph. Vertices are nothing but the RDD’s and the edges are the actions called on the RDD.
DAGScheduler is the one that divides the stages into a number of tasks. The DAGScheduler then passes the stage information to the cluster manager(YARN/Spark standalone) which triggers the task scheduler to run the tasks. Spark driver converts the logical plan to a physical execution plan. Spark jobs are executed in the pipelining method where all the transformation tasks are combined into a single stage.
Transformations
There are 2 kinds of transformations which take place:
1. Narrow Transformations: These are transformations that do not require the process of shuffling. These actions can be executed in a single stage.
Example: map() and filter()
2. Wide Transformations: These are transformations that require shuffling across various partitions. Hence it requires different stages to be created for communication across different partitions.
Example: ReduceByKey
Let’s take an example for a better understanding of how this works.
Example: In this example, we will see how a simple word count works using Spark DAGScheduler.
- val data = sc.textFile(“data.txt”)
Result: data: org.apache.spark.rdd.RDD[String] = data.txt MapPartitionsRDD[46] at textFile at <console>:24
First, a textFile operation is performed to read the given input text file from the HDFS location.
- data.flatMap(_.split(” “)).map(i=>(i,1)).reduceByKey(_ + _).collect
Result: res21: Array[(String, Int)] = Array()
Next, a flatMap operation is performed to split the lines in the entire input file into different words. Then a map operation is done to form (key, value) pairs like (word,1) for each of the words. And the reduceByKey function is called to find the sum of counts for each word. Finally, the collective action will give the end result by collecting all the data.
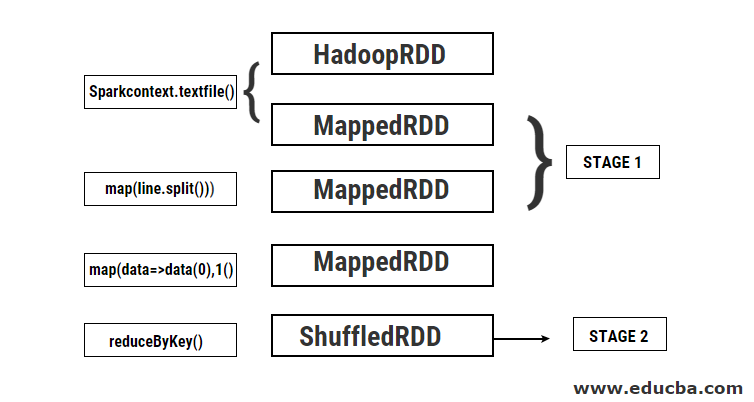
During this program, 2 stages are created by Spark because a transformation is performed here. While transformation operation is done, shuffling needs to be performed because the data needs to be shuffled between 2 or more different partitions. Hence for this, a stage is created and then another single stage for the transformation task is created.
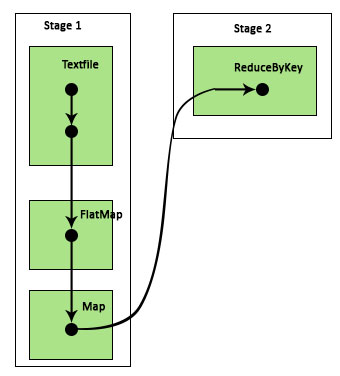
Also internally these stages will be divided into tasks. In this example, each stage is divided into 2 tasks since there are 2 partitions that exist. Each partition runs an individual task.
Types of Spark Stages
Here are the two types described in detail.
1. ShuffleMapStage
This is basically an intermediate stage in the process of DAG execution. The output of this stage is used as the input for further stage(s). The output of this is in the form of map output files which can be later used by reducing task. A ShuffleMapStage is considered ready when its all map outputs are available. Sometimes the output locations can be missing in cases where the partitions are either lost or not available.
This stage may contain many pipeline operations such as map() and filter() before the execution of shuffling. Internal registries outputLocs and _numAvailableOutputs are used by ShuffleMapStage to track the number of shuffle map outputs. A single ShuffleMapStage can be used commonly across various jobs.
2. ResultStage
As the name itself suggests, this is the final stage in a Spark job which performs an operation on one or more partitions of an RDD to calculate its result. Initialization of internal registries and counters is done by the ResultStage.
The DAGScheduler submits missing tasks if any to the ResultStage for computation. For computation, it requires various mandatory parameters such as stageId, stageAttempId, the broadcast variable of the serialized task, partition, preferred TaskLocations, outputId, some local properties, TaskMetrics of that particular stage. Some of the optional parameters required are Job Id, Application Id, and Application attempt Id.
Advantages of Spark Stages
Below are the different advantages of Spark Stages:
1. Dynamic allocation of executors
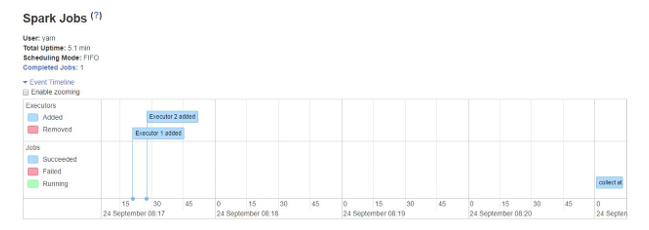
By seeing the Spark Job Event Timeline we can see that the allocation of executors is done dynamically. This means the executors are called from the cluster depending on the workload during the course of task execution. It is then released back to the cluster as soon as its job is done. This saves the resource allocation memory and allows the other applications running on the same cluster to reuse the executors. Hence the overall cluster utilization will increase and be optimal.
2. Caching
RDD’s are cached during the operations performed on them on each stage and stored in the memory. This is helpful in saving computational time when the end result requires the same RDD’s to be read again from HDFS.
3. Parallel execution
Spark jobs that are independent of each other are executed in parallel unless and until there is a shuffling required or the input of one stage is dependent on its previous output.
4. DAG Visualization
This is very helpful in cases of complex computations where a lot of operations and their dependencies are involved. Seeing this DAG Visualization, one can easily trace the flow and identify the performance blockages. Also, one can see each of the tasks run by each stage by clicking on the stages shown in this visualization. In this expanded view, all the details of the RDD’s which belong to this stage are shown.
5. Fault tolerance
Due to the caching operation performed on RDD’s, DAG will have a record of each action performed on them. Hence suppose in any case an RDD is lost, it can easily be retrieved with the help of DAG. Cluster manager can be used to identify the partition at which it was lost and the same RDD can be placed again at the same partition for data loss recovery.
Due to the above-mentioned benefits, Apache Spark is being widely used instead of the previously used MapReduce. It is nothing but an extended version of the MapReduce. Since MapReduce required the data to be read from and written to the HDFS multiple times, Spark was introduced which does these actions in its in-memory.
Conclusion
Hence we can conclude that it is more efficient because of their in-memory computation, increased processing speed even for iterative processing.
Recommended Articles
This is a guide to Spark Stages. Here we discuss the basic concept with types of transformation and advantages of Spark Stages respectively. You may also have a look at the following articles to learn more –
