Updated April 25, 2023
Overview of Replication in MongoDB
The following article provides an outline for Replication in MongoDB. MongoDB is an open-source Document-oriented database that is highly scalable; it is a NoSQL database. It is majorly used for high-volume data storage. MongoDB stores the data in JSON-like format, which is very flexible, and the document model then maps to the objects in application codes.

What is MongoDB Replication?
By replication, we mean the cluster of servers performing the same functionality. In the case of MongoDB, we have MongoDB servers for storing the data. The purpose of replication is to ensure that we have high data availability. If any servers go down, we should always have a copy of the data available on another server so that availability is not affected.
We need to replicate data periodically and at regular intervals to ensure that we do not lose any data. Even if the primary server goes down, the second one should serve the user requests.
The replication is also very effective in the case of load balancing; for example, If several users try to read or write data to servers, it would be unfair to send or retrieve all requests from just one server. A balancing mechanism should equally distribute the load to the available servers in the cluster to ensure that no server runs out of memory or bandwidth and goes down.
Working of Replication in MongoDB Process
To achieve replication in MongoDB, you can use Replica sets, which group MongoDB servers. A primary server receives all the requests or writing operations from clients. To enable read operations, you can add additional instances, known as secondary instances, to the replica set.
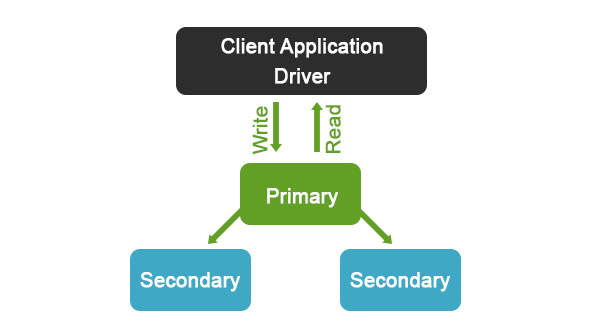
- As illustrated in the above diagram, all the data replicates the primary node to secondary nodes, and there will be only one primary node in any replica set.
- The cluster elects a new primary node whenever a failover occurs, or someone performs maintenance activity.
- Once the system recovers from failover, the failed node operates as a secondary node.
- The client application always communicates with the primary node, which is then followed by the replication of data to all the secondary nodes.
Replica Sets, Creation, and Operations
We must create a replica set of MongoDB instances to create a full-fledged replication of MongoDB servers.
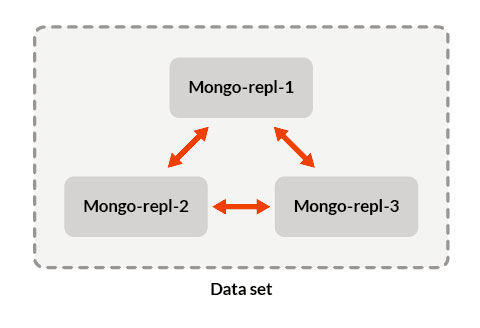
Let us imagine that we have three servers, repl1, repl2, and repl3, where repl1 is the primary server, and the remaining are secondary ones.
#1 Adding Primary Node Replication in MongoDB
- Please ensure that you have installed mongo.exe instances on all the given servers.
- All the mongod.exe must be able to ping each other, i.e., they can communicate. To check the same, please run the following commands from the primary servers (at first), i.e., repl1 in our case.
mongo –host repl2 –port 27017
mongo –host repl3 –port 27017Similarly, we can do the same test from other servers as well
- By using the command mongo –replset, we should start our first mongod.exe instance.
Mongo –replset “Replica_A,” Where Replica_A is the name of our replica set. - As for now, we have added the first server to our replica set, and the next step is to initiate the replica set by issuing the command rs.initiate().
- The next step is the verification step, where we will ensure that whatever we have configured so far is correct, and we can do that by running the command rs.conf().
#2 Adding Secondary Node Replication in MongoDB
After adding the primary server, issuing the command rs.add() makes it easy to add other secondary nodes.
Hence, run the below command, given that repl1 is our primary server and repl2 and repl3 are secondary servers.
Code:
rs.add("repl2")
rs.add("repl3")#3 Removing Servers from Replica Set
We can remove a server from any replica set by using the command rs.remove(). The process involves the following steps:
- Firstly, we need to shut down the instance you want to remove. We can do this by running the command db.shutdown server via mongo cell.
- The next step is to connect to the primary server.
- Run the following command; let’s say we have repl1, repl2, and repl3 as primary and secondary servers, respectively, and we want to remove repl3, then we will run the following command.
Code:
rs.remove("repl3")Some Commands for Troubleshooting
- All the mongod.exe must be able to ping each other, i.e., they can communicate. To check the same, please run the following commands from the primary servers (at first), i.e., repl1 in our case.
mongo –host repl2 –port 27017
mongo –host repl3 –port 27017Similarly, we can do the same test from other servers as well
- The rs.status() will give the status of your replica set
- For checking oplog, which is a log for recording all the write operations that were made, issue this command – rs.printReplicationInfo.
Advantages of Replication in MongoDB
The purpose of replication is to ensure that we have high data availability. To ensure availability, it’s essential to maintain a copy of the data on another server in case of server downtime. The replication is also very effective in load balancing, for example, if several users are trying to read or write data to servers.
So long story short, the main advantages of replication serve the following purpose:
- High availability
- Load Balancing
Conclusion
As we have seen, MongoDB replication is a process where we replicate the data in more than one server to ensure high availability. To do this, you can create a replica set and add the primary and secondary servers.
Frequently Asked Questions (FAQs)
Q1. How does replication work in MongoDB?
Answer: Replication in MongoDB involves maintaining multiple copies of data across a set of servers called a replica set, with a primary server receiving write operations and replicating the changes to secondary servers.
Q2. What is a primary and secondary server’s role in a replica set?
Answer: In a replica set, the primary server receives all write operations and replicates the changes to the secondary servers. The secondary servers act as read-only copies of the primary server, handling read operations and serving as a failover in case of primary server failure.
Q3. How does MongoDB ensure consistency and reliability in replication?
Answer: MongoDB ensures consistency and reliability in replication by using a two-phase commit protocol.
- In this protocol, the primary server sends a prepared message to all secondary servers before committing a write operation. Once the secondary servers acknowledge the prepared message, the primary server commits the operation and sends a commit message to the secondary servers.
- If any secondary servers fail to acknowledge the commit message, the primary server rolls back the operation to maintain consistency across the replica set. Additionally, MongoDB uses heartbeat messages to monitor the health of servers and automatically detect and recover from server failures.
Recommended Articles
We hope that this EDUCBA information on “Replication in MongoDB” was beneficial to you. You can view EDUCBA’s recommended articles for more information,
