Updated May 15, 2023

What is Naive Bayes Algorithm?
The naive Bayes Algorithm is one of the popular classification machine learning algorithms that helps to classify the data based upon the conditional probability values computation. It implements the Bayes theorem for the computation and used class levels represented as feature values or vectors of predictors for classification. Naive Bayes Algorithm is a fast algorithm for classification problems. This algorithm is a good fit for real-time prediction, multi-class prediction, recommendation system, text classification, and sentiment analysis use cases. Naive Bayes Algorithm can be built using Gaussian, Multinomial and Bernoulli distribution. This algorithm is scalable and easy to implement for a large data set.
It helps to calculate the posterior probability P(c|x) using the prior probability of class P(c), the prior probability of predictor P(x), and the probability of predictor given class, also called as likelihood P(x|c).
The formula or equation to calculate posterior probability is:
How Naive Bayes Algorithm works?
Let us understand the working of the Naive Bayes Algorithm using an example. We assume a training data set of weather and the target variable ‘Going shopping’. Now we will classify whether a girl will go to shopping based on weather conditions.
The given Data Set is:
| Weather | Going Shopping |
| Sunny | No |
| Rainy | Yes |
| Overcast | Yes |
| Sunny | Yes |
| Overcast | Yes |
| Rainy | No |
| Sunny | Yes |
| Sunny | Yes |
| Rainy | No |
| Rainy | Yes |
| Overcast | Yes |
| Rainy | No |
| Overcast | Yes |
| Sunny | No |
The following steps would be performed:
Step 1: Make Frequency Tables Using Data Sets.
| Weather | Yes | No |
| Sunny | 3 | 2 |
| Overcast | 4 | 0 |
| Rainy | 2 | 3 |
| Total | 9 | 5 |
Step 2: Make a likelihood table by calculating the probabilities of each weather condition and going shopping.
| Weather | Yes | No | Probability |
| Sunny | 3 | 2 | 5/14 = 0.36 |
| Overcast | 4 | 0 | 4/14 = 0.29 |
| Rainy | 2 | 3 | 5/14 = 0.36 |
| Total | 9 | 5 | |
| Probability | 9/14 = 0.64 | 5/14 = 0.36 |
Step 3: Now, we need to calculate the posterior probability using the Naive Bayes equation for each class.
Problem instance: A girl will go shopping if the weather is overcast. Is this statement correct?
Solution:
- P(Yes|Overcast) = (P(Overcast|Yes) * P (Yes)) / P(Overcast)
- P(Overcast|Yes) = 4/9 = 0.44
- P(Yes) = 9/14 = 0.64
- P(Overcast) = 4/14 = 0.39
Now put all the calculated values in the above formula
- P(Yes|Overcast) = (0.44 * 0.64) / 0.39
- P(Yes|Overcast) = 0.722
The class having the highest probability would be the outcome of the prediction. Using the same approach, probabilities of different classes can be predicted.
What is Naive Bayes Algorithm used for?
- Real-time Prediction: Naive Bayes Algorithm is fast and always ready to learn hence best suited for real-time predictions.
- Multi-class Prediction: The probability of multi-classes of any target variable can be predicted using a Naive Bayes algorithm.
- Recommendation system: Naive Bayes classifier with the help of Collaborative Filtering builds a Recommendation System. This system uses data mining and machine learning techniques to filter the information which is not seen before and then predict whether a user would appreciate a given resource or not.
- Text Classification/ Sentiment Analysis/ Spam Filtering: Due to its better performance with multi-class problems and its independence rule, the Naive Bayes algorithm performs better or has a higher success rate in text classification; therefore, it is used in Sentiment Analysis and Spam filtering.
Advantages and Disadvantages of Naive Bayes Algorithm
Given below are the advantages and disadvantages mentioned:
Advantages:
- Easy to implement.
- Fast
- If the independence assumption holds, then it works more efficiently than other algorithms.
- It requires less training data.
- It is highly scalable.
- It can make probabilistic predictions.
- Can handle both continuous and discrete data.
- Insensitive towards irrelevant features.
- It can work easily with missing values.
- Easy to update on the arrival of new data.
- Best suited for text classification problems.
Disadvantages:
- The strong assumption about the features to be independent is hardly true in real-life applications.
- Data scarcity.
- Chances of loss of accuracy.
- Zero Frequency, i.e. if the category of any categorical variable is not seen in the training data set, then the model assigns a zero probability to that category, and then a prediction cannot be made.
How to Build a Basic Model using Naive Bayes Algorithm
There are three types of Naive Bayes models, i.e. Gaussian, Multinomial, and Bernoulli. Let us discuss each of them briefly.
1. Gaussian: Gaussian Naive Bayes Algorithm assumes that the continuous values corresponding to each feature are distributed according to Gaussian distribution, also called Normal distribution.
The likelihood or prior probability of predictor of the given class is assumed to be Gaussian; therefore, conditional probability can be calculated as:
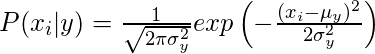
2. Multinomial: The frequencies of the occurrence of certain events represented by feature vectors are generated using multinomial distribution. This model is widely used for document classification.
3. Bernoulli: In this model, the inputs are described by the features, which are independent binary variables or Booleans. This is also widely used in document classification like Multinomial Naive Bayes.
You can use any of the above models as required to handle and classify the data set.
You can build a Gaussian Model using Python by understanding the example given below:
Code:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array([-2,7], [1,2], [1,5], [2,3], [1,-1], [-2,0], [-4,0], [-2,2], [3,7], [1,1], [-4,1], [-3,7]])
b = np.array([3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4])
md = GaussianNB()
md.fit (a, b)
pd = md.predict ([[1, 2], [3, 4]])
print (pd)
Output:
([3, 4])
Conclusion
In this article, we learned the concepts of the Naive Bayes Algorithm in detail. It is mostly used in text classification. It is easy to implement and fast to execute. Its major drawback is that it requires that the features must be independent, which is not true in real-life applications.
Recommended Articles
This has been a guide to Naive Bayes Algorithm. Here we discussed the basic concept, how does it work, along with the advantages and disadvantages. You can also go through our other suggested articles to learn more –
