Updated June 13, 2023
Difference Between Hadoop vs Apache Spark
Hadoop vs Apache Spark is a big data framework and contains some of the most popular tools and techniques that brands can use to conduct big data-related tasks. Apache Spark, on the other hand, is an open-source cluster computing framework. While Hadoop vs Apache Spark might seem like competitors, they do not perform the same tasks and in some situations can even work together. While it is reported that Spark can function more than 100 times faster than Hadoop in some case scenarios, it does not have its own storage system. This is an important criterion as distributed storage is one of the most important aspects of data projects.
So what exactly is Big Data?
Big data is a big buzzword that helps organizations and companies to make sense of large amounts of data. It has received a lot of attention in the past decade and in simple terms, it is defined as big data that is so large for a company that it cannot be processed using conventional sources. Newer tools are being developed daily so that companies can start to make sense of this growing amount of data. That is why big data is one of the biggest technological trends that will affect the outcomes of brands and companies all over the globe.
What is the size of Big Data and how fast is this sector growing?
Technology has always played an integral part in the functioning of brands and companies around the world. This is because technology helps companies to increase their profits and productivity in an effective fashion. For instance, in his presentation, Keg Kruger has described how the US census made use of the Hollerith Tabulating System where a lot of data had to be tabulated in a mechanical manner. To deal with the massive amount of data, Hollerith was combined with three other companies to form the Computing Tabulating Recording Corporation, which is today called IBM or the International Business Machines.
Data is measured in bytes which is a unit that is used to measure digital information. In the field, 8 bits is equal to one byte. From gigabytes to petabytes, the world of big data is expanding. Some values of data are called gigabyte, terabyte, petabyte and exabyte among others.
To put things into perspective, one gigabyte is equal to 1024 megabytes which is data that is stored in a single DVD while one petabyte is the amount of data stored on CDs about 2 miles high or worth 13 years of HD TV video while one exabyte is equal to one billion gigabytes.
Some of the major characteristics of Big Data can be mentioned below:
- The volume of data: The quantity of data is one of the biggest characteristics of Big data. When the size and potential of data are large, there are more chances of them being qualified at being called big data. The name Big Data itself contains the word and that itself is a characteristic of the size.
- Variety of data: Another characteristic of Big data is the variety. It is also important that data analysis needs to be conducted on the said data. In addition, it is also important that analysts are able to use the said data to draw valuable insights that can, in turn, help the company to achieve its goals and objectives.
- The velocity of data: Here the term velocity refers to the speed at which data is generated and processed. This is extremely important because the speed at which data is processed plays a major role in helping companies to achieve their goals. The faster the data is processed the faster companies will be able to reach the next stage of development in an effective fashion.
- Variability: Another feature of Big data is variability. This means that data has to manage in ineffective fashion so that there is no inconsistency in them. An inconsistency of data has to be handled in an effective manner so that it does not affect the quality of data at any stage.
- Complex nature of data: Companies and brands today manage tonnes of data that come from multiple sources. These data need to be linked, connected and correlated so that companies can make sense of these insights and use them to make effective campaigns and plans. That is why complexity is one of the most integral features of big data.
It is, therefore, no surprise that big data is one of the biggest factors to influence the functioning of companies across many forms. In many industries, both accomplished companies and startups are using the power of big data to create solutions that are innovative and competitive. For example, the healthcare industry has greatly benefitted from the use of big data solutions. In this industry, data pioneers are effectively analyzing the outcomes of medical trials and thereby discovering new benefits and risks of medicines and vaccines. These trials that use big data solutions are on a much more large-scale than clinical trials, thereby allowing the healthcare industry to expand their potential and harass unlimited opportunities in an effective fashion. Other industries are also slowly waking up to this and there is increased adoption of data techniques from companies of all sizes and sectors. Such knowledge is allowing brands to not just offer new and innovative products to their current audience but also create innovative designs for future use.
Many organizations are today in the middle of a lot of information flows where data about products and services, buyers and sellers, consumers’ intents among others must be studied in a proper manner. If brands want to survive in the future markets, then they must be able to use the capabilities offered by Big data in a fashion that is effective and successful. One of the most important aspects of big data adoption is the framework that companies would like to adopt for their use. Two of the most popular big data framework that exists in the market include Hadoop and Spark. While Spark has overtaken Hadoop as the most active open-source, both these frameworks are used by multiple companies across sectors. While the comparison between Hadoop vs Apache Spark is not really possible, both of these systems have some very similar uses and functions.
Hadoop vs Apache Spark Infographics
Below is the top 6 Comparisons between Hadoop vs Apache Spark
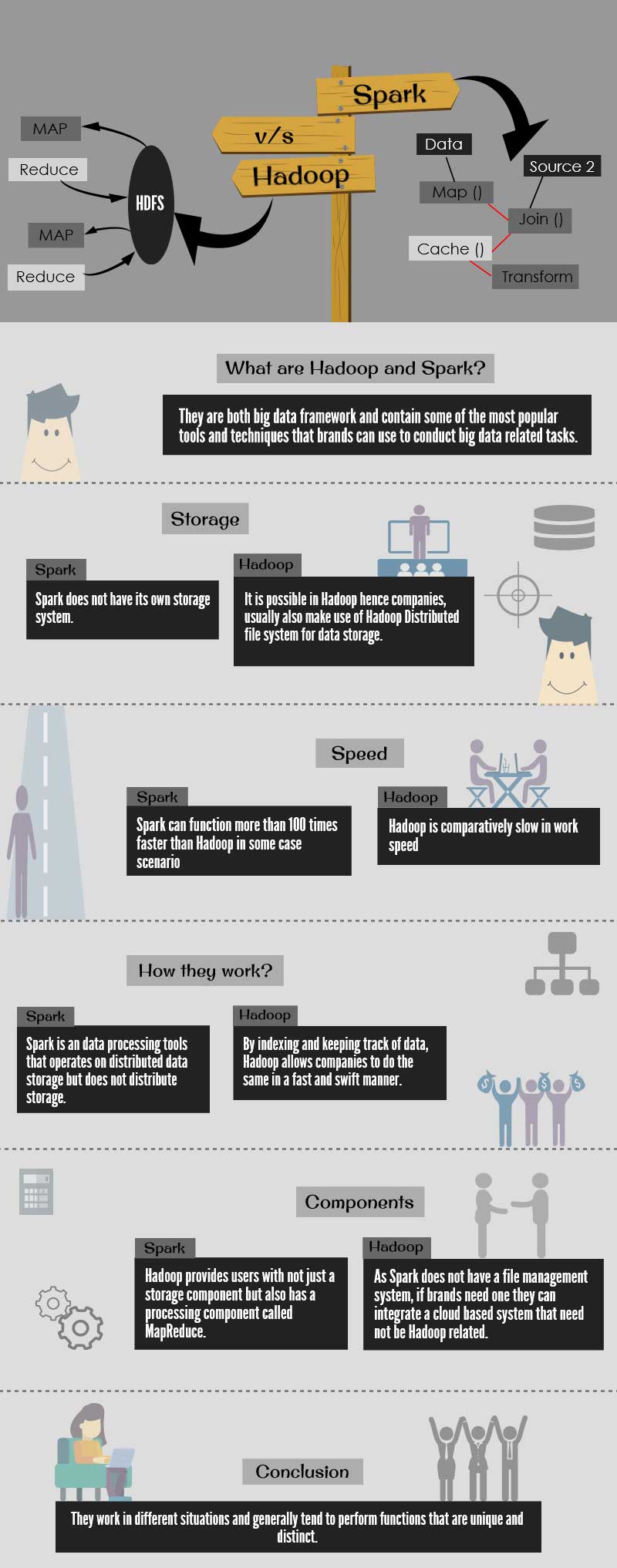
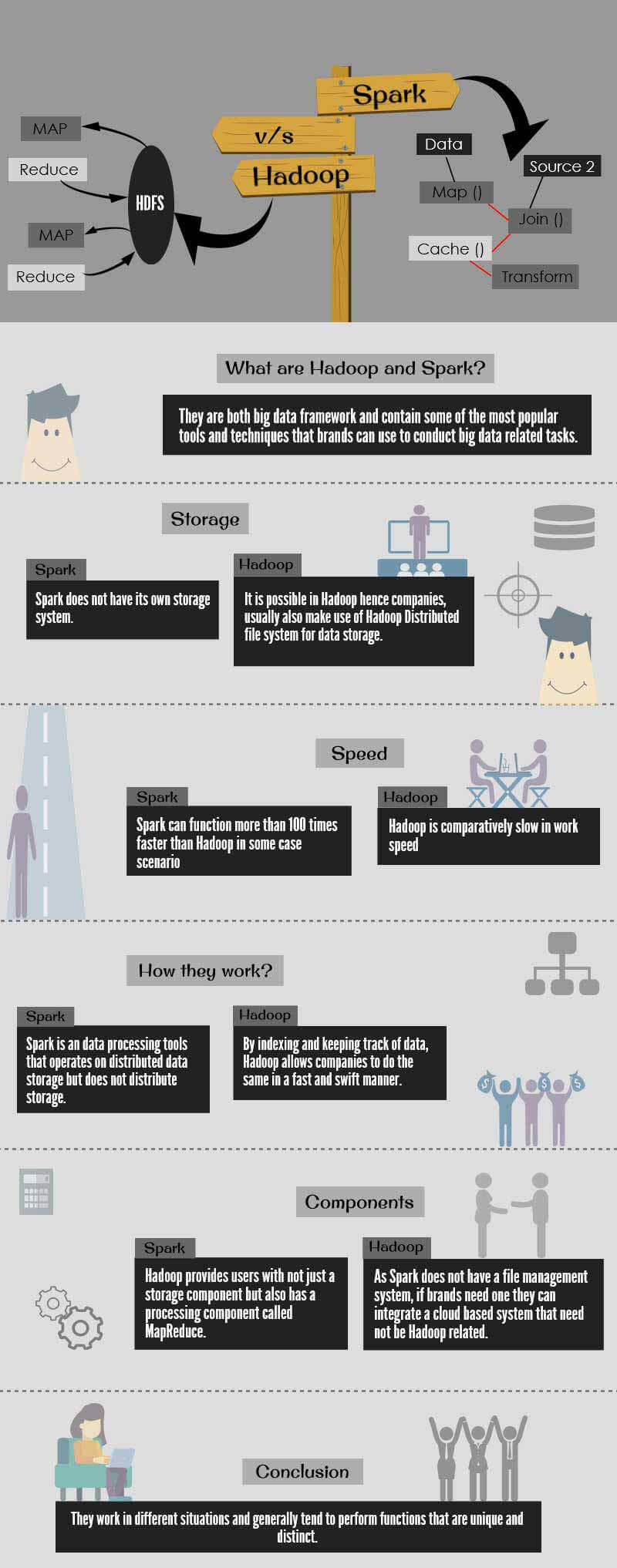
Both Hadoop vs Apache Spark is a big data framework and contains some of the most popular tools and techniques that brands can use to conduct big data-related tasks.
Created by Doug Cutting and Mike Cafarella, Hadoop was created in the year 2006. At that time, it was developed to support distribution for the Nutch search engine project. It later became one of the most important big data frameworks and until recently it dominated the market as a major player. Apache Spark, on the other hand, is an open-source cluster computing framework that was developed at the AMPLab in California. Later it was donated to the Apache Software Foundation, where it remains today. n February 2014, Spark became a top-level Apache project and later in November of the same year, the engineering team at Databricks set a new record in large able sorting with the use of Spark framework. Both Hadoop vs Apache Spark is an extremely popular data framework that is used by multiple companies and is competing with each other for more space in the market.
While Hadoop vs Apache Spark might seem like competitors, they do not perform the same tasks and in some situations can even work together. While it is reported that Spark can function more than 100 times faster than Hadoop in some case scenarios, it does not have its own storage system. This is an important criterion as distributed storage is one of the most important aspects of data projects. This is because data storage framework allows data to be stored in multi-PETA datasets that in turn can be stored on an infinite number of hard drives, making it extremely cost-effective. Additionally, data frameworks must be scalable in nature so that more drivers can be added to the network as and when the size of data increases. As Spark does not have its own system for data storage, this framework requires one that is provided by another party. That is why for many Big Data projects, companies that install Spark for advanced analytics application, usually also make use of Hadoop Distributed file system for data storage.
Speed is, therefore, the one thing that gives Spark an extra edge over Hadoop. Because Spark handles its functions by copying them from distributed physical storage. Because there are no slow clunky mechanical hard drives in Spark, the speed in which it can perform its functions in comparison to Hadoop is faster. In case of Hadoop, data is written is saved in Hadoop’s MapReduce System which also writes all the data back to the physical storage medium after every function. This copying of data was done so that a full recovery was possible in case something went wrong during the process. As data stored in an electronic manner is more volatile, this was considered important. In case of Spark system, data is arranged in a system called resilient distributed datasets that can be recovered in case something goes wrong during the big data process.
Another thing that sets Spark ahead of Hadoop is that Spark is able to process tasks in the real-time and has advanced machine learning. Real-time processing means that data can be entered into an analytical application the moment it is known, and insights can be immediately gained. This means that immediate actions can be taken on those insights, thereby allowing companies to take advantage of the current opportunities. In addition, machine learnings are defined as algorithms that can think for themselves, thereby allowing them to create a solution for large sets of data. This is is the sort of technology that is at the heart of advanced industries and can help management to deal with problems before they even arise on one hand and also create innovative technology that is responsible for driverless cars and ships on the other hand.
Hadoop vs Apache Spark are therefore two different database systems and here are a few things that set them apart:
- Both these systems work in a different manner: Hadoop vs Apache Spark is big data frameworks that have different functions. While Hadoop is a distributed data infrastructure, which distributes huge data collection across multiple nodes. This means that users of Hadoop do not have to invest and maintain custom hardware that is extremely expensive. By indexing and keeping track of data, it allows companies to do the same in a fast and swift manner. On the other hand, Spark is a data processing tools that operate on distributed data storage but does not distribute storage.
- It is possible to use one system without the other: Hadoop provides users with not just a storage component (Hadoop Distributed File System) but also has a processing component called MapReduce. This means that users who purchased Hadoop need not purchase Spark for their processing needs. At the same time users of Spark, need not install anything related to Hadoop. As Spark does not have a file management system if brands need one they can integrate a cloud-based system that need not be Hadoop related.
- Spark is much speedier than Hadoop but not all organizations may need analytics to function at such rapid speed: MapReduce’s processing style is good but if your companies have functions that are more static, they can conduct data analytic functions through batch processing as well. However, if companies need to stream data from sensors on a factory floor or require multiple operations, it is best to invest in Spark big data software. In addition, many machine learning algorithms require multiple operations and some common applications for the Spark tool includes online product recommendation, machine monitoring, and cyber security among others.
Hadoop vs Apache Spark is really two major Big data frameworks that exist in the market today. While both Hadoop vs Apache Spark frameworks is often pitched in a battle for dominance, they still have a lot of functions that make them extremely important in their own area of influence. They work in different situations and generally tend to perform functions that are unique and distinct.
Recommended Courses
This has been a guide to Hadoop vs Apache Spark here we have discussed the era of big data is something that every brand must look at so that they can yield results in an effective fashion because the future belongs to those companies that extract value from data in a successful fashion. You may also look at the following Hadoop vs Apache Spark article to learn more –
