Updated March 17, 2023

Introduction to Hadoop Alternatives
Apache Hadoop is a monstrous framework that uses several other components such as HDFS, Hive, Spark, YARN, and Zookeeper. It is used to process and analyze data retrieved from internal or external sources. It can scale from several machines or servers to thousands of them. There are many in-built library functions that can detect and handle malfunctions.
Components of Hadoop
Below are the components of the Hadoop:
- Hadoop Distributed File System (HDFS): This is the storage tank of data in Hadoop. It works on the principle of distributed data, where huge sets of data are broken into small parts and stored across multiple machines in a cluster.
- MapReduce: It is a programming model to perform analyses in a parallel manner on the data that reside in different nodes of a cluster.
- Hive: An Open-Source framework that is used to query the structured data using a Hive-Query language. The indexing feature is used to accelerate the querying process.
- Ambari: A platform to monitor cluster health and automate operations. It has a simple Web UI and can easily be installed and configured.
List of Hadoop Alternatives
Below is the Different Alternatives, which are as follows:
1. Batch Processing
Here the processing is done only on the archival data. For example, financial audits & Census are an analysis done on old data to provide a better prediction of future outcomes. This data may contain billions of rows and columns. Batch-Processing is best suited for large data processing without the need for real-time analysis.
2. Real-Time Processing
It is also known as Stream-Processing. Here the data is processed from time to time as they are generated to provide a quick insight into the probable outcomes. Earthquake detection & Stock Markets are the best examples where real-time analysis is a must.
3. Apache Spark
Spark is a framework used along with Hadoop to process batch or real-time data on clustered machines. It can also be used as a Standalone, retrieving and storing data in third-party servers without using HDFS. It is an open-source product. It provides APIs that are written using SCALA, R or Python that supports general processing. To process structured data, Spark-SQL can be used. Spark Streaming performs much needed real-time analytics. Spark provides support to machine learning using MLIB. In the end, the processed data can be viewed using Graphix.
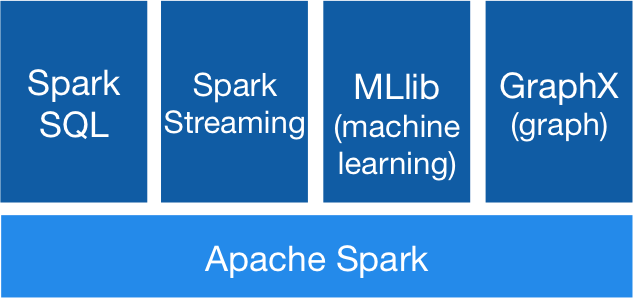
The most notable feature of Spark is In-Memory processing. The entire processing of the data takes place in the memory and not in the disk. This method saves the read-write time of the input to the disk and the output back from it. Spark is lightning quick and is almost 100times faster than Hadoop processing. The entire function is defined and submitted to the Spark context. Only then, the processing begins from scratch. This method is known as Lazy-execution. Kafka, Flume is used as inputs for streaming data. Structured or Unstructured data can be used by Spark for analysis. Data streams are a bunch of data for a given time interval in Spark Streaming. They are converted into batches and submitted to the Spark Engine for processing. Structured data are converted into Data frames before using Spark-SQL for further analysis.
4. Apache Storm
Apache Storm is also one of the alternatives of Hadoop, which is best suited for distributed, real-time analytics. It is easy to set up, User-friendly and provides no data loss. A storm has the very high processing power and provides low latency (usually in seconds) compared to Hadoop.
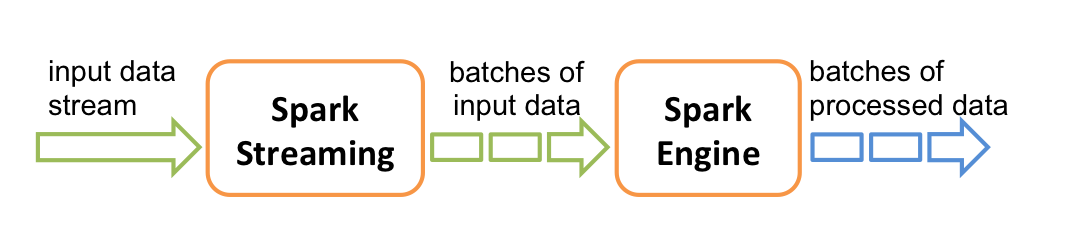
We will take a closer look at the workflow of Storm:
- The Storm Topology (similar to a DAG but a physical execution plan) is submitted to Nimbus (Master Node).
- The tasks and the order in which they should be carried out are submitted to the Nimbus.
- The Nimbus evenly distributes the available tasks to the supervisors (Spouts), and the process is done by the Worker Nodes (Bolts).
- The health of the Spouts and Bolts is continuously monitored through Heartbeats. Once the supervisor dies, the Nimbus allocates the task to another Node.
- If the Nimbus dies, it is automatically restarted by the monitoring tools. Meanwhile, the supervisors continue performing the tasks which were assigned earlier.
- Once the Nimbus is restarted, it continues to work from where it stopped. Hence there is no data loss, and each data passes through the topology at least once.
- The topology continues to run unless the Nimbus is terminated or forcefully shut down.
- Storm makes use of Zookeeper to monitor the Nimbus and the other supervisor nodes.
5. Big Query
Databases are used for transactional processing. The managers create reports and analyze the data from various databases. Data warehouses were introduced to fetch data from multiple databases across the organization. Google developed Big query, which is a data warehouse managed on its own self. To handle very complex queries, one might need very high performing servers and Node machines which can cost enormously. The setting up of the infrastructure may take up to several weeks. Once the maximum threshold is reached, then it must be scaled up.
To overcome these issues, Big query provides storage in the form of the Google cloud. The worker nodes scale up to the size of a data center if necessary to perform a complex query within seconds. You pay for what you use, i.e. the querying. Google takes care of the resources and their maintenance and security. Running queries on normal databases may take from minutes to hours. Big query processes data much faster, and it is mainly suited for streaming data such as online gaming and the Internet of Things (IoT). The processing speed is as high as billions of rows in a second.
6. Presto
A Presto query can be used to combine data from various sources across the organization and analyze them. The data can be residing in the Hive, RDBMS, or Cassandra. Presto is best suited for analysts who expect the entire queried report within minutes. The architecture is analogous to a classic database management system with the use of multiple nodes across a cluster. It was developed by Facebook for performing analysis and finding insights from their internal data, including their 300PB data warehouse. More than 30,000 queries are run on their data to scan over a petabyte per day. Other leading companies such as Airbnb and Dropbox make use of Presto too.
Recommended Article
This has been a guide to Hadoop Alternatives. Here we discuss the components of Hadoop, batch processing and Real-Time processing of Hadoop Alternatives. You may also look at the following articles to learn more:
