Updated March 20, 2023
Introduction to Classification Algorithms
This article on classification algorithms gives an overview of different methods commonly used in data mining techniques with different principles. Classification is a technique that categorizes data into a distinct number of classes, and labels are assigned to each class. The main target of classification is to identify the class to launch new data by analysis of the training set by seeing proper boundaries. In a general way, predicting the target class and the above process is called classification.
For instance, the hospital management records the patient’s name, address, age, previous history of the patient’s health to diagnosis them; this helps to classify the patients. They can be characterized into two phases: a learning phase and an evaluation phase. Learning phase models the approach base on training data, whereas the evaluation phase predicts the output for the given data. We could find their applications in email spam, bank loan prediction, Speech recognition, Sentiment analysis. The technique includes the mathematical function f with input X and output Y.
Explain Classification Algorithms in Detail
Classification can be performed on both structured and unstructured data. Classification can be categorized into
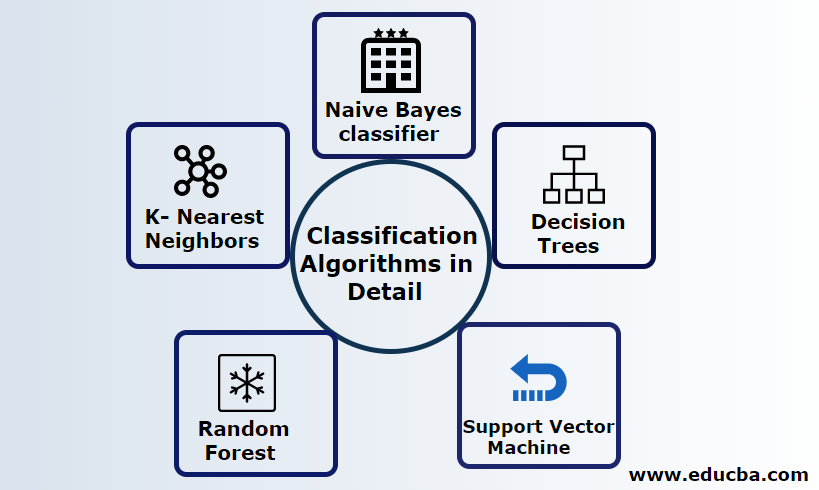
- Naive Bayes classifier
- Decision Trees
- Support Vector Machine
- Random Forest
- K- Nearest Neighbors
1. Naive Bayes classifier
It’s a Bayes’ theorem-based algorithm, one of the statistical classifications, and requires few amounts of training data to estimate the parameters, also known as probabilistic classifiers. It is considered to be the fastest classifier, highly scalable, and handles both discrete and continuous data. In addition, this algorithm is used to make a prediction in real-time. There are different types of naive classifier, Multinomial Naïve Bayes, Bernoulli Naïve Bayes, Gaussian naive.
Bayesian classification with posterior probabilities is given by
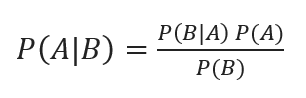
Where A, B are events, P(A|B)- Posterior probabilities.
If two values are independent of each other then,
P(A, B) =P(A) P(B)
Naïve Bayes can be built using the python library. Naïve’s predictors are independent, though they are used in recommendation systems. They are used in many real-time applications and are well knowingly used in document classification.
Advantages:
Advantages are they require very less computational power, are assumed in multiple class prediction problems, accurately work on large datasets.
Disadvantage:
The main disadvantage of this classifier is they will assign zero probability. And they have features that are independent of each other.
2. Decision tree
It’s a top-down approach model with the structure of the flowchart that handles high dimensional data. The outcomes are predicted based on the given input variable. A decision tree is composed of the following elements: A root, many nodes, branches, leaves. The root node does the partition based on the attribute value of the class; the internal node takes an attribute for further classification; branches make a decision rule to split the nodes into leaf nodes; lastly, the leaf nodes gives us the final outcome. The time complexity of the decision tree depends upon the number of records, attributes of the training data. If the decision tree is too long, it is difficult to get the desired results.
Advantage: They are applied for predictive analytics to solve the problems and used in day to daily activities to choose the target based on decision analysis. Automatically builds a model based on the source data. Best in handling missing values.
Disadvantage: The size of the tree is uncontrollable until it has some stopping criteria. Due to their hierarchical structure tree is unstable.
3. Support Vector Machine
This algorithm plays a vital role in Classification problems, and most popularly, machine learning supervised algorithms. It’s an important tool used by the researcher and data scientist. This SVM is very easy, and its process is to find a hyperplane in an N-dimensional space data point. Hyperplanes are decision boundaries which classify the data points. All this vector falls closer to the hyperplane, maximize the margin of the classifier. If the margin is maximum, the lowest is the generalization error. Their implementation can be done with the kernel using python with some training datasets. The main target of the SVM is to train an object into a particular classification. SVM is not restricted to become a linear classifier. SVM is preferred more than any classification model due to their kernel function, which improves computational efficiency.
Advantage: They are highly preferable for their less computational power and effective accuracy. Effective in high dimensional space, good memory efficiency.
Disadvantage: Limitations in speed, kernel, and size
4. Random Forest
It’s a powerful machine-learning algorithm based on the Ensemble learning approach. The basic building block of Random forest is the decision tree used to build predictive models. The work demonstration includes creating a forest of random decision trees, and the pruning process is performed by setting stopping splits from yielding a better result. Random forest is implemented using a technique called bagging for decision making. This bagging prevents overfitting of data by reducing the bias; similarly, this random can achieve better accuracy. Finally, a final prediction is taken by an average of many decision trees, i.e. frequent predictions. The random forest includes many use cases like Stock market predictions, fraudulence detection, News predictions.
Advantages:
- It doesn’t require any big processing to process the datasets and is a very easy model to build. In addition, it provides greater accuracy helps in solving predictive problems.
- Works well in handling missing values and automatically detects an outlier.
Disadvantage:
- Requires high computational cost and high memory.
- Requires much more time period.
5. K- Nearest Neighbors
Here we will discuss the K-NN algorithm with supervised learning for CART. They use a K positive small integer; an object is assigned to the class based on the neighbors, or we shall assign a group by observing in what group the neighbor lies. This is chosen by distance measure Euclidean distance and brute force. The value of K can be found using the Tuning process. KNN doesn’t prefer to learn any model to train a new dataset and use normalization to rescale data.
Advantage: Produces effective results if the training data is huge.
Disadvantage: The biggest issue is that if the variable is small, it works well. Secondly, choosing the K factor while classifying.
Conclusion
In conclusion, we have gone through different classification algorithms’ capabilities that still act as a powerful tool in feature engineering, image classification, which plays a great resource for machine learning. Classification algorithms are powerful algorithms that solve hard problems.
Recommended Articles
This is a guide to Classification Algorithms. Here we discuss that the Classification can be performed on both structured and unstructured data with pros & cons. You can also go through our other suggested articles –
