Updated June 9, 2023
Introduction to Clustering Algorithms
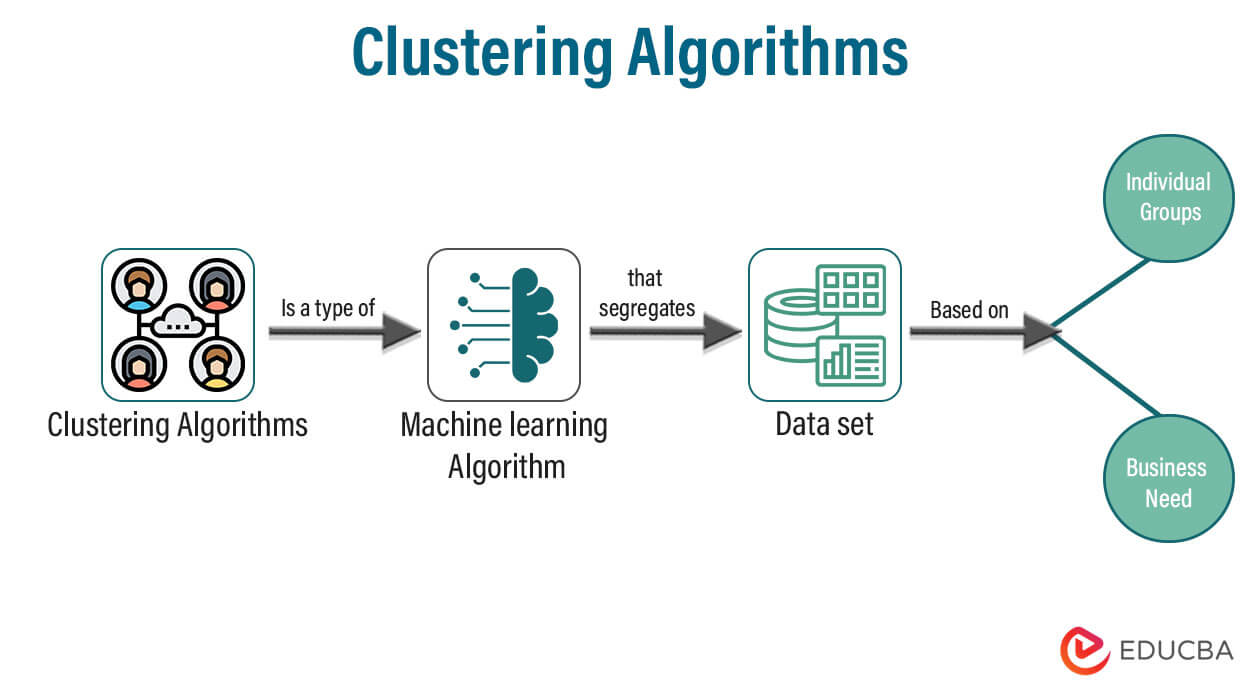
A clustering algorithm is a type of Machine learning algorithm that is useful for segregating the data set based on individual groups and the business need. Machine learning algorithms are a popular category implemented in data science and artificial intelligence (AI). There are two types of clustering algorithms based on the logical grouping pattern: hard clustering and soft clustering.
Some popular clustering methods based on the computation process are K-Means clustering, connectivity models, centroid models, distribution models, density models, and hierarchical clustering. The use cases for clustering algorithms are image segmentation, market segmentation, and social network analysis.
Types of Clustering Algorithms
We subdivide the clustering algorithm into two subgroups, which are:
- Hard Clustering: AA group of similar data entities belonging entirely to a similar trait or cluster. If the data entities do not meet a specific identity condition, the algorithm removes the data entity from the cluster set.
- Soft Clustering: Soft clustering allows each data entity to relax and search for a similar data entity with a high likelihood of forming a cluster. This type of clustering may assign a unique data entity to multiple clusters based on its similarity to other data entities.
What is Clustering Methodology?
Every clustering methodology follows the rules defining the similarities between data entities. There are hundreds of clustering methodologies available in the market today.
So let’s take some of it into consideration, which is very popular nowadays:
1. Connectivity Models
As clarified by its title, in this mechanism, the algorithm finds the nearest similar data entity in the group of set data entities based on the notion that the data points are closer in data space. So the data entity more comparable to the similar data entity will exhibit more similarity than the data entity lying far away. This mechanism also has two approaches.
In the first approach, the algorithm divides a set of data entities into separate clusters and then arranges them according to the distance criteria. In another method, the algorithm subset all the data entities into a particular cluster and then aggregate them according to the distance criteria, as the distance function is a subjective choice based on user criteria.
2. Centroid Models
The iterative algorithm considers a certain centroid point first and then assigns data entities similar to it to a cluster based on their closeness relative to the centroid point. Unfortunately, the most popular K-Means Clustering algorithm was unsuccessful in this type of clustering algorithm. Another critical point to note is that centroid models do not predefine any clusters, thus providing an analysis of the output data set.
3. Distribution Models
In this type of algorithm, the method finds how much is possible that each data entity in a cluster belongs to an identical or same distribution like Gaussian or normal. One drawback of this type of algorithm is that overfitting can occur in the data set entity due to this type of clustering.
4. Density Models
The algorithm isolates the data set based on different density regions in the data space and assigns specific clusters to the data entity.
5. K Means Clustering
One can use this type of clustering to locate a local maximum after each iteration in multiple data entity sets.
This mechanism involves the five steps mentioned below:
- First, we must define the number of clusters we want in this algorithm.
- Each data point is assigned to a cluster randomly.
- Then we have to calculate centroid models in it.
- After this, the relative data entity is re-assigned to its nearest or closest clusters.
- Re-arrange cluster centroid.
- Repeat the previous two steps until we get the desired output.
6. Hierarchical Clustering
This type of algorithm is similar to the k-means clustering algorithm, but there is a minute difference between them which are:
- K- means linear, whereas hierarchical clustering is quadratic.
- Hierarchical clustering produces reproducible results, unlike k-means, which can have multiple results when the algorithm is called multiple times.
- Hierarchical clustering works for every shape.
- You can interrupt the Hierarchical clustering anytime when you get the desired result.
Applications of Clustering Algorithms
Now it’s time to learn about the applications of the clustering algorithm. It has a very vast feature incorporated into it.
A clustering algorithm applicable to various domains which are:
- Anomaly detection.
- Image segmentation.
- Medical imaging.
- Search result grouping.
- Social network analysis.
- Market Segmentation.
- Recommendation engines.
A clustering algorithm is a revolutionized approach to machine learning. It can be used to upgrade the accuracy of the supervised machine learning algorithm. Using clustered data entities in machine-learning algorithms can result in highly accurate supervised results. It is correct that IT can be used in multiple machine-learning tasks.
Conclusion
So it has many applications in various domains, such as mapping, customer reports, etc. Moreover, using clustering, we can quickly increase the accuracy of the machine learning approach. So considering future aspects, I can say that this algorithm is used almost in every technology in software development. So anyone interested in pursuing a career in machine learning needs to know deeply about the clustering algorithm, which is directly related to machine learning and data science. It is also good to always have the technique required in every technology to return a good approach.
Frequently Asked Questions (FAQs)
Q1 What is clustering?
Answer: Clustering is a technique of grouping similar objects so that objects in the same group (called a cluster) are more similar to each other than those in other groups (clusters).
Q2 What is k-means clustering?
Answer: K-means clustering is a type of clustering algorithm that partitions the data into a predetermined number of clusters, where each cluster is represented by its centroid (the mean of all data points in the cluster).
Q3 What are some applications of clustering algorithms?
Answer: Various fields, such as marketing, image processing, bioinformatics, social network analysis, and pattern recognition, widely used clustering algorithms. Customer segmentation, image segmentation, gene expression analysis, community detection, and anomaly detection are among the uses of clustering algorithms.
Recommended Articles
We hope that this EDUCBA information on “Clustering Algorithm” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
