Updated June 2, 2023

Introduction to Big Data Architecture
When it comes to managing heavy data and doing complex operations on that massive data there becomes a need to use big data tools and techniques. When we say using big data tools and techniques we effectively mean that we are asking to make use of various software and procedures which lie in the big data ecosystem and its sphere. There is no generic solution that is provided for every use case and therefore it has to be crafted and made in an effective way as per the business requirements of a particular company. Thus there becomes a need to make use of different big data architecture as the combination of various technologies will result in the resultant use case being achieved. By establishing a fixed architecture it can be ensured that a viable solution will be provided for the asked use case.
What is Big Data Architecture?
- This architecture is designed in such a way that it handles the ingestion process, processing of data and analysis of the data is done which is way too large or complex to handle the traditional database management systems.
- Different organizations have different thresholds for their organizations, some have it for a few hundred gigabytes while for others even some terabytes are not good enough a threshold value.
- Due to this event happening if you look at the commodity systems and the commodity storage the values and the cost of storage have reduced significantly. There is a huge variety of data that demands different ways to be catered.
- Some of them are batch related data that comes at a particular time and therefore the jobs are required to be scheduled in a similar fashion while some others belong to the streaming class where a real-time streaming pipeline has to be built to cater to all the requirements. All these challenges are solved by big data architecture.
Explanation of Big Data Architecture
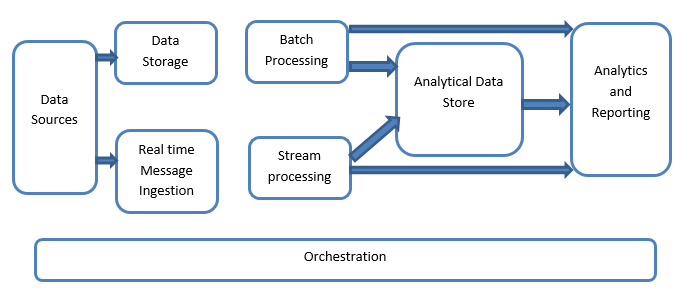
Big Data systems involve more than one workload types and they are broadly classified as follows:
- Where the big data-based sources are at rest batch processing is involved.
- Big data processing in motion for real-time processing.
- Exploration of interactive big data tools and technologies.
- Machine learning and predictive analysis.
1. Data Sources
The data sources involve all those golden sources from where the data extraction pipeline is built and therefore this can be said to be the starting point of the big data pipeline.
The examples include:
(i) Datastores of applications such as the ones like relational databases
(ii) The files which are produced by a number of applications and are majorly a part of static file systems such as web-based server files generating logs.
(iii) IoT devices and other real time-based data sources.
2. Data Storage
This includes the data which is managed for the batch built operations and is stored in the file stores which are distributed in nature and are also capable of holding large volumes of different format backed big files. It is called the data lake. This generally forms the part where our Hadoop storage such as HDFS, Microsoft Azure, AWS, GCP storages are provided along with blob containers.
3. Batch Processing
All the data is segregated into different categories or chunks which makes use of long-running jobs used to filter and aggregate and also prepare data o processed state for analysis. These jobs usually make use of sources, process them and provide the output of the processed files to the new files. The batch processing is done in various ways by making use of Hive jobs or U-SQL based jobs or by making use of Sqoop or Pig along with the custom map reducer jobs which are generally written in any one of the Java or Scala or any other language such as Python.
4. Real Time-Based Message Ingestion
This includes, in contrast with the batch processing, all those real-time streaming systems which cater to the data being generated sequentially and in a fixed pattern. This is often a simple data mart or store responsible for all the incoming messages which are dropped inside the folder necessarily used for data processing. There are, however, majority of solutions that require the need of a message-based ingestion store which acts as a message buffer and also supports the scale based processing, provides a comparatively reliable delivery along with other messaging queuing semantics. The options include those like Apache Kafka, Apache Flume, Event hubs from Azure, etc.
5. Stream Processing
There is a slight difference between the real-time message ingestion and stream processing. The former takes into consideration the ingested data which is collected at first and then is used as a publish-subscribe kind of a tool. Stream processing, on the other hand, is used to handle all that streaming data which is occurring in windows or streams and then writes the data to the output sink. This includes Apache Spark, Apache Flink, Storm, etc.
6. Analytics-Based Datastore
This is the data store that is used for analytical purposes and therefore the already processed data is then queried and analyzed by using analytics tools that can correspond to the BI solutions. The data can also be presented with the help of a NoSQL data warehouse technology like HBase or any interactive use of hive database which can provide the metadata abstraction in the data store. Tools include Hive, Spark SQL, Hbase, etc.
7. Reporting and Analysis
The insights have to be generated on the processed data and that is effectively done by the reporting and analysis tools which makes use of their embedded technology and solution to generate useful graphs, analysis, and insights helpful to the businesses. Tools include Cognos, Hyperion, etc.
8. Orchestration
Big data-based solutions consist of data related operations that are repetitive in nature and are also encapsulated in the workflows which can transform the source data and also move data across sources as well as sinks and load in stores and push into analytical units. Examples include Sqoop, oozie, data factory, etc.
Conclusion
In this post, we read about the big data architecture which is necessary for these technologies to be implemented in the company or the organization. Hope you liked our article.
Recommended Articles
This has been a guide to Big Data Architecture. Here we discussed what is big data? and we’ve also demonstrated the architecture of big data along with the block diagram. You can also go through our other suggested articles to learn more –

