
Difference Between Apache Hadoop vs Apache Storm
Big Data has become a popular open-source technology in recent times. Developers are adding a new framework to the Hadoop stack daily to solve complex problems related to the massive volume of data. To perform data analysis, Hadoop uses a processing framework like Hadoop with MapReduce for batch processing and Apache Storm for stream processing; hence, Storm and Hadoop help an organization choose the right technology from the Hadoop stack. Let’s look into what is Apache Hadoop and Apache Storm.
Apache Hadoop:
Apache Hadoop is an open-source batch-processing framework that processes large datasets across a cluster of commodity computers. It was the first extensive data framework that used HDFS (Hadoop Distributed File System) for storage and MapReduce framework for computation. The existing system can easily accommodate new nodes if the amount of data increases because of its scalability feature. Due to its fault-tolerance nature system is prone to failure, so the system s available all the time, i.e., high availability.
Apache Storm:
Apache Storm provides real-time data processing capabilities to the Hadoop stack and is also open source. Apache Storm can handle a very large amount of data and delivers results with low latency (near real-time). Apache Storm does not run on a Hadoop cluster; instead, it uses Apache ZooKeeper to coordinate topologies in DAG (Directed Acyclic Graph).
Check out the official website for why to use Storm: http://storm.apache.org/.
Head-to-Head Comparison Between Apache Hadoop vs Apache Storm (Infographics)
Let us check out the Top 6 differences between Apache Hadoop vs Apache Storm in the detailed format in below tabular format:
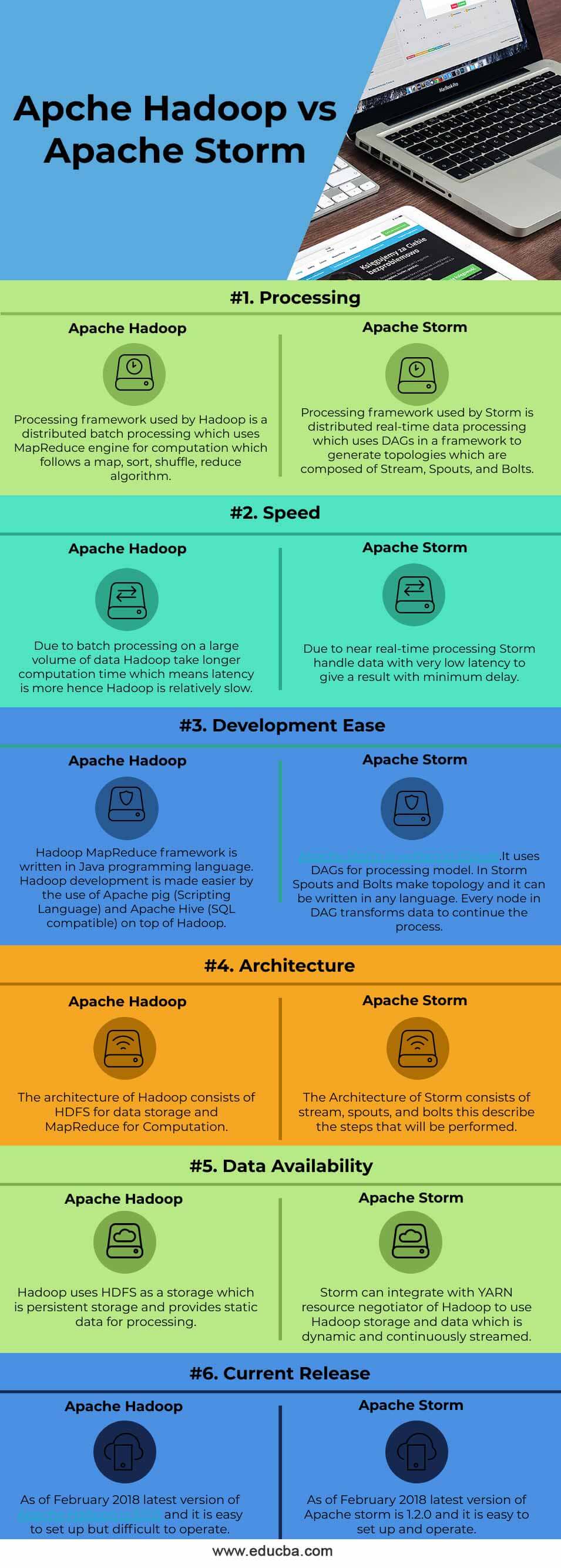
Key Differences Between Apache Hadoop vs Apache Storm
Let us discuss the key difference between Apache Hadoop vs Apache Storm:
| Apache Hadoop | Apache Storm |
| Distributed Batch processing of large volume and unstructured datasets. | Distributed real-time processing of data having a large volume and high velocity. |
| The framework is written in Java. | Storms are written in Half Java and Half Clojure code, but most of the code/logic is written in Clojure. |
| It is Stateful streaming processing. | It is Stateless streaming processing. |
| It uses Apache Zookeeper coordination. | It may or may not use Apache Zookeeper for coordination. |
| MapR jobs are executed sequentially, still, it is completed. | Storm topology runs continuously until the system shutdown. |
| It has High Latency (Slow Computation). | It has Low Latency (Fast Computation). |
| Architecture is based on a topology of Spouts and bolts. | The architecture consists of HDFS and MapReduce. |
| Data is continuously streamed, and it is dynamic. | Data is static and nonvolatile (Data is Persistence). |
| It is easy to set up, but operating a Hadoop cluster is difficult. | It is easy to set up, and operating a storm cluster is also easy. |
| Use Cases: Twitter, Navisite, Wego, etc. | Use Cases: Black Box Data, Search Engine Data, etc. |
Apache Hadoop vs Apache Storm Comparison Table
Following is the comparison between Apache Hadoop vs Apache Storm.
| Apache Hadoop | Apache Storm |
| Processing: Framework used by Hadoop is a distributed batch processing that uses the MapReduce engine for computation which follows a map, sort, shuffle, and reduce algorithm. | Processing: The framework used by Storm is distributed real-time data processing, which uses DAGs in a framework to generate topologies composed of Stream, Spouts, and Bolts. |
| Speed: Due to batch processing on a large volume of data Hadoop take longer computation time, which means latency is more; hence Hadoop is relatively slow. | Speed: Due to near real-time processing, Storm handles data with very low latency to give a result with minimum delay. |
| Development Ease: Hadoop MapReduce framework is written in Java programming language. Hadoop development is made easier by using Apache Pig (Scripting Language) and Apache Hive (SQL compatible) on top of Hadoop. | Development Ease: Apache Storm is written in Clojure. It uses DAGs for the processing model. Storm Spouts and Bolts make topology, which can be written in any language. Every node in DAG transforms data to continue the process. |
| Architecture: The architecture of Hadoop consists of HDFS for data storage and MapReduce for Computation. | Architecture: The Architecture of a Storm consists of a stream, spouts, and bolts. This describes the steps that will be performed. |
| Data Availability: Hadoop uses HDFS as persistent storage and provides static data for processing. | Data Availability: Storm can integrate with the YARN resource negotiator of Hadoop to use Hadoop storage and data, which is dynamic and continuously streamed |
| Current Release: As of February 2018 latest version of Apache Hadoop is 3.0.0, and it is easy to set up but difficult to operate. | Current Release: As of February 2018 latest version of Apache Storm is 1.2.0, and it is easy to set up and operate. |
Apart from differences, some similarities are also available between Hadoop and Storm. Both are Open Source technologies with scalable and fault-tolerant features in organizations’ business intelligence and significant data analytics sector.
Conclusion
Apache Hadoop provides batch processing for handling large datasets with high latency and uses commodity hardware, making it less expensive. It also supports other frameworks with diverse technology. But for near real-time processing with very low latency, the Storm is the best option which can be used with multiple programming languages. Hence, as per the organization’s need, we can use Apache Storm or Apache Hadoop for real-time or batch processing.
Recommended Articles
This is a guide to Apache Hadoop vs Apache Storm. Here we have discussed the basic concept, head-to-head comparison, key differences, and a comparison table. You may look at the following articles to learn more –
