Updated March 22, 2023

Introduction to Hadoop FS Command List
Hadoop works on its own File System which is distributed in nature known as “Hadoop distributed File System HDFS”. Hadoop relies on distributed storage and parallel processing. This way of storing the file in distributed locations in a cluster is known as Hadoop distributed File System i.e. HDFS. In order to perform various operations at the file level, HDFS provides its own set of commands Known as Hadoop File System Commands. Let us explore those commands. In this topic, we are going to learn about Hadoop FS Command.
Commands of Hadoop FS Command List
Any HDFS command has the prefix of “hdfs dfs”. It means that we are specifying that the default file system is HDFS. Let us explore Hadoop FS Commands list one by one
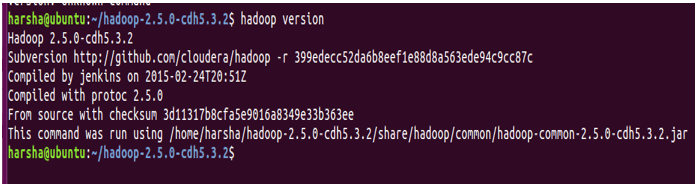
1. Versions
The version command is used to find the version of the Hadoop installed in the system.
Syntax: Hadoop version
2. ls Command
ls command in Hadoop is used to specify the list of directories in the mentioned path. ls command takes hdfs path as parameter and returns a list of directories present in the path.
Syntax: hdfs dfs -ls <hdfs file path>
Example: hdfs dfs -ls /user/harsha

We can also use -lsr for recursive mode
Syntax: hdfs dfs –lsr <hdfs file path>
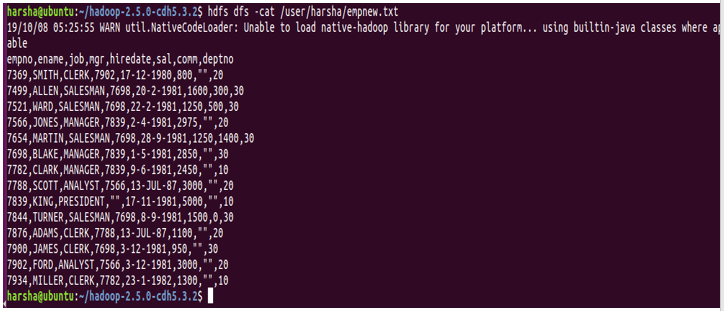
3. Cat Command
Cat command is used to display the contents of the file to the console. This command takes the hdfs file path as an argument and displays the contents of the file.
Syntax: hdfs dfs -cat <hdfs file path>
Example: hdfs dfs -cat /user/harsha/empnew.txt
4. mkdir command
mkdir command is used to create a new directory in the hdfs file system. It takes the hdfs path as an argument and creates a new directory in the path specified.
Syntax: hdfs dfs -mkdir <hdfs path>
Example: hdfs dfs -mkdir /user/example
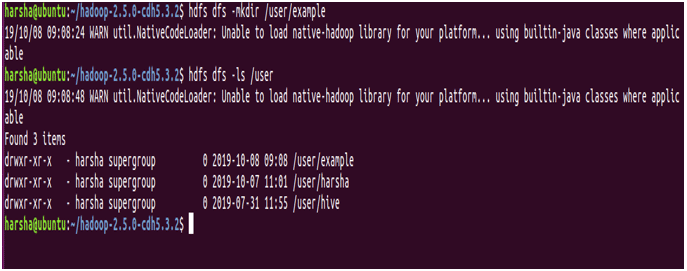
In the above screenshot, it is clearly shown that we are creating a new directory named “example” using mkdir command and the same is shown is using ls command.
Also for mkdir command, we can give the ‘-p’ option. It creates parent directories in the path if they are missing.
Example: hdfs dfs -mkdir -p /user/test/example2
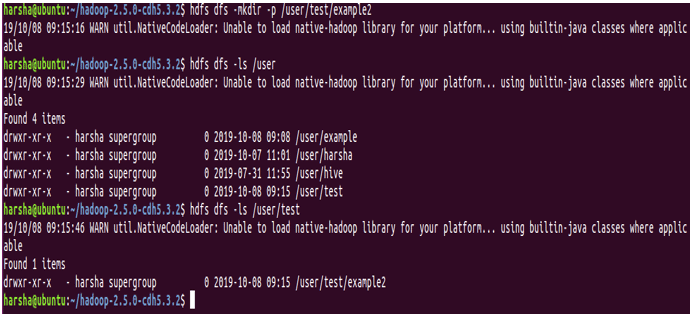
In the above screenshot, it is quite evident that we have -p option and in the path /user/test/example2, both tests and example2 directories are created.
5. put command
put the command in HDFS is used to copy files from given source location to the destination hdfs path. Here source location can be a local file system path. put command takes two arguments, first one is source directory path and the second one is targeted HDFS path
Syntax: hdfs dfs -put <source path> <destination path>
Example: hdfs dfs -put /home/harsha/empnew.txt /user/test/example2
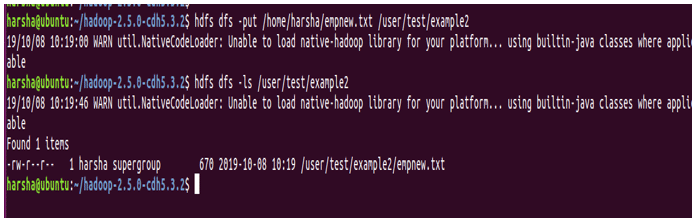
In the above screenshot, we can clearly see that the file is copied from source to destination.
6. copyFromLocal command
copyFromLocal command in HDFS is used to copy files from source path to the destination path. Source in this command is restricted to the local file system
Syntax: hdfs dfs -copyFromLocal /home/harsha/empnew.txt/user/harsha/example

Difference between put command and copyFromLocal Command: There is no much difference between these two hdfs shell commands. Both of them are used to copy from the local file system to target the HDFS file path.
But put command is more useful and robust as it permits to copy multiple Files or Directories to destination in HDFS
hdfs dfs -put <source1> <source2> <destination>
7. get Command
get command in hdfs is used to copy a given hdfs file or directory to the target local file system path. It takes two arguments, one is source hdfs path and other is target local file system path
Syntax: hdfs dfs -get <source hdfs> <destination local file system>
Example: hdfs dfs -get /user/test/example2 /home/harsha
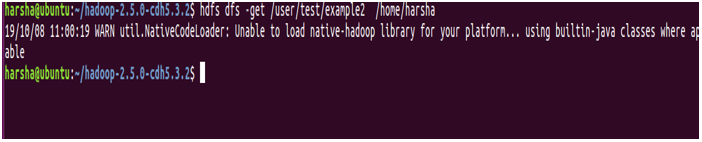
8. copyToLocal command
copyToLocal command in hdfs is used to copy a file or directory in hdfs to the local file system. In this command, the destination is fixed to the local file system. This copyFromLocal command is similar to get command.
Syntax: hdfs dfs -copyToLocal <source hdfs> <local file system>
Example: hdfs dfs -copyToLocal /user/harsha/example /home/harsha
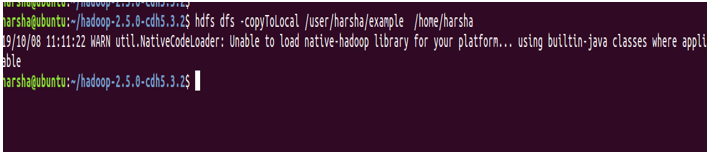
9. count command
count command in hdfs is used to count the number of directories present in the given path. count command takes a given path as an argument and gives the number of directories present in that path.
Syntax: hdfs dfs -count <path>
Example: hdfs dfs -count /user

10. mv command
mv command in hdfs is used to move a file in between hdfs. mv command takes file or directory from given source hdfs path and moves it to target hdfs path.
Syntax: hdfs dfs -mv <hdfs path> <hdfs path>
Example: hdfs dfs -mv /user/test/example2 /user/harsha
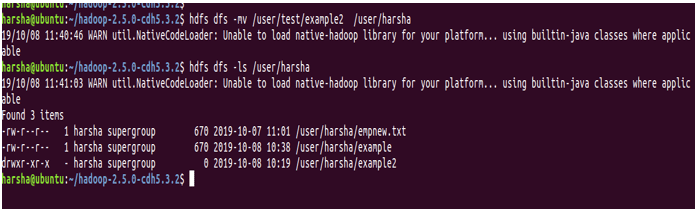
In the above screenshot, we can see that the example2 directory is now present in /user/harsha
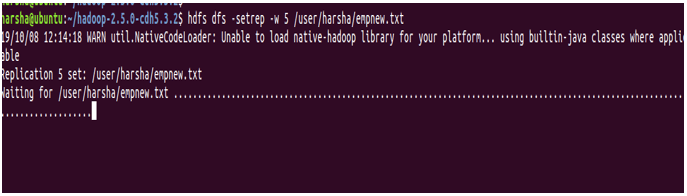
11. setrep command
setrep command in hdfs is used to change the replication factor of the given file. By default hdfs has a replication factor of ‘3’. If the given path is a directory, this command will change the replication factor of all the files present in that directory.
Syntax: hdfs dfs -setrep [-R] [-w] <rep> <path>
-w: This flag specifies that command should wait for replication to get completed.
rep: replication factor
Example: hdfs dfs -setrep -w 5 /user/harsha/empnew.txt
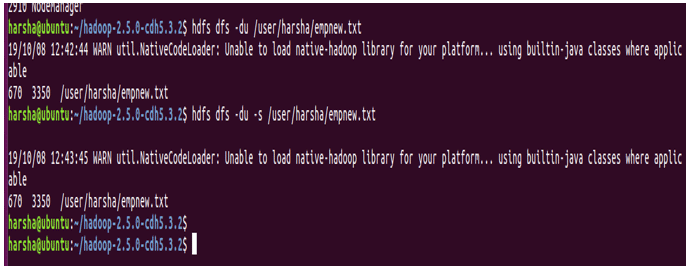
12. du command
du command in hdfs shows disk utilization for the hdfs path given. It takes the hdfs path as input and returns disk utilization in bytes.
Syntax: hdfs dfs -du <hdfs path>
Example: hdfs dfs -du /user/harsha/empnew.txt
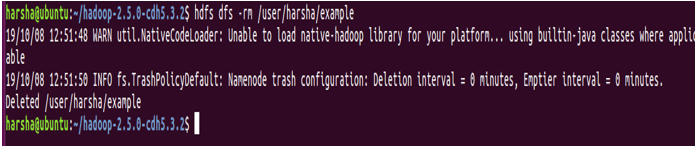
13. rm command
rm command in hdfs is used to remove files or directories in the given hdfs path. This command takes the hdfs path as input and removes the files present in that path.
Syntax: hdfs dfs -rm <hdfs path>
Example: hdfs dfs -rm /user/harsha/example
Conclusion
We have hereby come to know about various hdfs commands, their respective syntaxes with examples as well. We should note kick start any hdfs commands, we need run bin/hdfs script. hdfs is followed by an option known as dfs, which indicates that we are working with the Hadoop distributed file system. With the help of the above-mentioned commands, we can negotiate with the HDFS File System.
Recommended Articles
This is a guide to Hadoop FS Command. Here we have discussed basic, intermediate as well as advanced commands along with tips and tricks to use effectively. You may also look at the following article to learn more –
