Updated July 28, 2023

Introduction to Data Mining
This is a data mining method used to place data elements in their similar groups. Cluster is the procedure of dividing data objects into subclasses. Clustering quality depends on the way that we used. Clustering is also called data segmentation as large data groups are divided by their similarity.
What is Clustering in Data Mining?
Clustering is the grouping of specific objects based on their characteristics and their similarities. As for data mining, this methodology divides the data that is best suited to the desired analysis using a special join algorithm. This analysis allows an object not to be part or strictly part of a cluster, which is called the hard partitioning of this type. However, smooth partitions suggest that each object in the same degree belongs to a cluster. More specific divisions can be created like objects of multiple clusters, a single cluster can be forced to participate, or even hierarchic trees can be constructed in group relations. This filesystem can be put into place in different ways based on various models. These Distinct Algorithms apply to each and every model, distinguishing their properties as well as their results. A good clustering algorithm is able to identify the cluster independent of cluster shape. There are 3 basic stages of clustering algorithm which are shown below
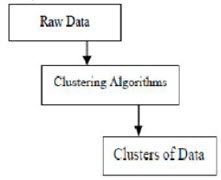
Clustering Algorithms in Data Mining
Depending on the cluster models recently described, many clusters can partition information into a data set. It should be said that each method has its own advantages and disadvantages. The selection of an algorithm depends on the properties and the nature of the data set.
Methods of Clustering in Data Mining
The different methods of clustering in data mining are as explained below:

- Partitioning based Method
- Density-based Method
- Centroid-based Method
- Hierarchical Method
- Grid-Based Method
- Model-Based Method
1. Partitioning based Method
The partition algorithm divides data into many subsets.
Let’s assume the partitioning algorithm builds a partition of data and n objects present in the database. Hence each section will be represented ask ≤ n.
This gives an idea that the classification of the data is in k groups, which can be shown below
Figure 1 shows original points in clustering

Figure 2 shows Partition clustering after applying an algorithm
This indicates that each group has at least one object, and every object, must belong to exactly one group.
2. Density-Based Method
These algorithms produce clusters in a determined location based on the high density of data set participants. It aggregates some range notion for group members in clusters to a density standard level. Such processes can perform less in detecting the group’s Surface areas.
3. Centroid-based Method
A vector of values references almost every cluster in this type of os grouping technique. Compared to other groups, each object is part of the group with a minimum difference in value. The number of groups should be predefined, which is the most significant algorithm problem of this type. This methodology is the closest to the subject of identification and is widely used for problems of optimization.
4. Hierarchical Method
The method will create a hierarchical decomposition of a given set of data objects. Based on how the hierarchical decomposition is formed, we can classify hierarchical methods. This method is shown as follows
- Agglomerative Approach
- Divisive Approach
Agglomerative Approach is also known as Button-up Approach. Here we begin with every object that constitutes a separate group. It continues to fuse items or groups close together
Divisive Approach is also known as the Top-Down Approach. We begin with all the things in the same cluster. This method is rigid, i.e., it can never be undone once a fusion or division is completed
5. Grid-Based Method
Grid-based methods work in the object space instead of dividing the data into a grid. Grid is divided based on characteristics of the data. By using this method, non-numeric data is easy to manage. Data order does not affect the partitioning of the grid. An important advantage of a grid-based model it provides faster execution speed.
Advantages of Hierarchical Clustering are as follows
- It applies to any attribute type.
- It provides flexibility related to the level of granularity.
6. Model-Based Method
This method uses a hypothesized model based on probability distribution. By clustering the density function, this method locates the clusters. It reflects the data points’ spatial distribution.
Application of clustering in Data Mining
Clustering can help in many fields such as Biology, Plants, and animals classified by their properties and marketing; Clustering will help identify customers of a particular customer record with similar conduct. In many applications, such as market research, pattern recognition, data and image processing, the clustering analysis is used in large numbers. Clustering can also help advertisers in their customer base to find different groups. And their customer groups can be defined by buying patterns. It is used in biology to determine plant and animal taxonomies for the categorization of genes with similar functionality and insight into population-inherent structures. In an earth observation database, clustering also makes it easier to find areas of similar use in the land. It helps to identify groups of houses and apartments by type, value, and destination of houses. The clustering of documents on the web is also helpful for the discovery of information. The cluster analysis is a tool for gaining insight into the distribution of data to observe each cluster’s characteristics as a data mining function.
Conclusion
Clustering is important in data mining and its analysis. In this article, we have seen how clustering can be done by applying various clustering algorithms and its application in real life.
Recommended Article
This has been a guide to What is Clustering in Data Mining. Here we discussed the basic concepts, different methods along with the application of Clustering in Data Mining. You can also go through our other suggested articles to learn more –

