Introduction to Text Mining
But understanding the meaning of the text is a challenging job. We need a helpful business intelligence tool to help us understand the information quickly. It is the process of understanding information from a set of texts. These contents can be in Word documents, emails,s or social media posts. It uses automated methods to understand the knowledge in text documents.
Text Mining can also make the computer understand structured or unstructured data. Qualitative data or unstructured data are data that cannot be measured in terms of numbers. These data usually contain information like color, texture, and text. It is an interdisciplinary field that includes information retrieval, data mining, machine learning, statistics, etc. Text Mining is a slightly different field from data mining.
Advantages of Text Mining
There are a lot of advantages which are listed below.
- It saves time and resources and performs more efficiently than human brains.
- It helps to track opinions over time.
- It helps to summarize the documents.
- Text analytics helps to extract concepts from the text and present it more thoroughly.
- You can plug in any vocabulary to use the terminology in your area of interest.
Uses of Text Mining
- The names of different entities and relationships between the text can be easily found using various techniques.
- It helps to extract patterns from a large amount of unstructured data.
- Systematic reviewing of literature – It can go for in-depth research of text, find out key themes, and highlight the repeated terms or text and the popular topics over a period of time.
- Testing of Hypothesis – A particular hypothesis can be tested through text mining to see whether the document confirms or denies the idea. Mostly an established belief is stretched over the form first.
Importance of Text Mining
- It helps to solve knowledge discovery problems in different areas of business.
- Text mining allows you to visualize the data in many ways, like HTML tables, charts, graphs, etc.
- It is a great productivity tool. It gives better results faster than any other device.
Applications of Text Mining
1. Analyzing open-ended survey responses
Open-ended survey questions will help the respondents to give their views or opinion without any constraints. This will help to know more about the customers’ opinions than relying on structured questionnaires.
2. Automatic processing of messages, emails
Text Mining can filter unnecessary mail using certain words or phrases. Such emails will automatically discard such emails to spam. Such an automatic classifying and filtering of selected emails and sending them to the corresponding department is done using the Text Mining system. It will also alert the email to remove the emails with offending words or content.
3. Analyzing warranty or insurance claims
In most business organizations, information is collected mainly in text. For example, in a hospital, the patient interviews can be narrated briefly in text form, and the reports are also in text.
4. Investigating competitors by crawling their websites
Another important application area is processing the contents of web pages in a particular domain. This way, the text mining system will automatically find a list of terms used on the site. This way, one can see the most important terms used on the website. In this way, one can know the competitors’ capabilities, which can help you deliver business efficiently.
The other applications of Text Mining include the following
- Business Intelligence
- E-Discovery
- Bioinformatics
- Records Management
- National Security or Intelligence works
- Social Media Monitoring
Techniques Used in Text Mining
There are five essential technologies used in the Text Mining system. They are discussed in detail below.
1. Information Extraction
This analyzes the unstructured text by finding the essential words and relationships between them. This technique uses pattern matching to find the order in the text. It helps in transforming the unstructured text into a structured form. The Information extraction technique involves language processing modules.
2. Categorization
The categorization technique classifies the text document under one or more categories. It is based on input-output examples to do the classification. The categorization process includes pre-processing, indexing, dimensional reduction, and type. The text can be categorized using a Naive Bayesian classifier, a Decision tree, a Nearest Neighbour classifier, and Support Vendor Machines.
3. Clustering
The clustering method is used to group text documents that have similar contents. It has partitions called clusters; each section will have several copies with similar contents. Clustering makes sure that no record will be omitted from the search, and it derives all the documents which have identical contents. K-means is the frequently used clustering technique. This technique also compares each cluster and finds how well the form is connected. Companies use this technique to create a database with thousands of similar documents.
4. Visualization
This technique uses text flags to represent documents or documents and uses colors to indicate compactness. Visualization technique helps to display textual information more attractively. The below picture will represent the Visualization technique
5. Summarization
The summarization technique will help reduce the length of the document and summarize the document’s details in brief. It makes the document work by reading for the users and understanding the content at a glance. Summarization replaces the entire set of documents. It summarizes a large text document easily and quickly. Humans take more time to read and translate the paper, but this technique makes it very fast. It helps to highlight the significant points in a form.
Methods and Models Used in Text Mining
Based on information retrieval Text Mining has four main methods.
1. Term Based Method (TBM)
The term in a document means a word that has a semantic meaning. This method analyzes the entire set of documents based on the time. One main disadvantage of this method is the problem of synonymy and polysemy. Synonymy is where multiple words have the same meaning. Polysemy is where a single word has more implications.
2. Phrase-Based Method (PBM)
In this method, the document is analyzed based on phrases that are less obvious, to more meanings, and are more discriminative. The disadvantages of this method include
- They have inferior statistical properties in terms
- They have a low frequency of occurrence
- They have a large number of noisy phrases
3. Concept-Based Method (CBM)
This method analyzes the document based on the sentence and document level. In this method, there are three main components. The first component examines the meaningful part of the sentences. The second component produces a conceptual ontological graph to explain the structures. The third component extracts top concepts based on the first two components. This method can differentiate between important and unimportant words.
4. Pattern Taxonomy Method (PTM)
In this method, the document is analyzed based on the patterns. Patterns in a copy can be found using data mining techniques like association rule mining, sequential pattern mining, frequent itemset mining, and closed pattern mining. This method uses two processes – pattern deploying and pattern evolving. This method performs better than all the other models or strategies.
How does Text Mining Work?
It would help if you understood that text mining allows you to understand the text better than anything else. Text Mining system exchanges words from unstructured data into numerical values. Text mining helps identify patterns and relationships within a large amount of text. Text mining often uses computational algorithms to read and analyze textual information. Without text mining, it won’t be easy to understand the text easily and quickly.
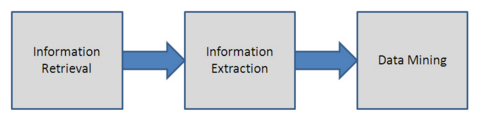
Step 1: Information Retrieval
This is the first step in the process of data mining. This step involves a seaengine’s helpline to find out the text collection, also known as a corpus of tetrastich, which might need some conversion. Usually, XML is the standard for text mining.
Step 2: Natural Language Processing
This step allows the system to perform a grammatical analysis of a sentence to read the text. It also analyzes the text in structures.
Step 3: Information extraction
It also involves adding names or locations to the reader. This step lets the search engine get the information and find out the relationships between them using their metadata.
Step 4: Data Mining
The final stage is data mining using different tools. This step finds the similarities between the information with the same meaning, which will be otherwise difficult to find. Text Mining is a tool that boosts the research process and helps to test the queries.
Text Mining includes the following list of elements.
- Text Categorization
- Text Clustering
- Concept/entity extraction
- Granular taxonomies
- Sentiment Analysis
- Document Summarization
- Entity Relation Modelling
Challenges
The main challenge faced by the Text Mining system is the natural language. Natural language faces the problem of ambiguity. Another limitation is that using an Information Extraction system involves semantic analysis. But these days, there is a need for more text understanding.
Text Mining also has a limitation with copyright legislation. There are a lot of restrictions in text mining a document. Most of the time, it includes the rights of the copyright holders. One more limitation is that text mining does not generate new facts and is not an end process.
Conclusion
Text mining or text analytics is a booming technology, but the results and depth of analysis vary from business to business. An organization can use text mining to gain knowledge about content-specific values.
Recommended Articles
We hope that this EDUCBA information on “Text Mining” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

