Updated July 4, 2023

Introduction to Spark flatMap
In Apache Spark, Spark flatMap is one of the transformation operations. These are immutable collections of records that are partitioned, and these can only be created by operations (operations that are applied throughout all the elements of the dataset) like filter and map. The operation developer in Map has the facility to create his own custom logic business. Map() is most similar to flatMap() and can return only 0 or 1 and or more elements from the function map().
Syntax for flatMap in Spark:
RDD.flatMap(<transformation function>)The transformation function from the above syntax code, for each element source of the RDD, can return multiple elements of RDD.
How does Spark flatMap work?
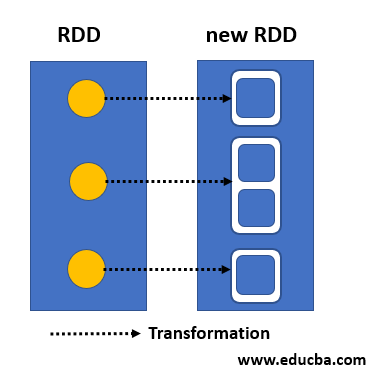
A flatMap is an operation of transformation. This gives many results it, meaning we can get one, two, zero, and many other elements from the flatMap operation applications. Map operation is one step behind flatMap operation technique and is mostly similar.
Example:
Spark
Scala
Java helps
Hello world
How are you doing
Debugging is fun
Code:
flatMap(a => a.split(' '))Output:

flatMap operation of transformation is done from one to many.
Let us consider an example which calls lines.flatMap(a => a.split(‘ ‘)) is a flatMap that will create new files off RDD with records of 6 numbers, as shown in the below picture, as it splits the records into separate words with spaces in between them.
Splitting an RDD key value can also be done using flatMap operation transformation.
1. Spark
2. Scala
3. Java helps
4. Hello world
5. How are you doing
6. Debugging is fun
Code:
flatMap(a => a.split(' '))Output:

One-to-one can also be used in flatMap also one-to-zero mapping. lines.flatMap(a => None) is used in returning an empty RDD as flatMap does not help in creating a record for any values in a resulting RDD.flatMap(a => a.split(‘ ‘))
Spark
Scala
Java helps
Hello world
How are you doing
Debugging is fun
Code:
flatMap(a => None)Output:

Examples of Spark flatMap
Given below are the examples mentioned:
Example #1
String to words – An example in RDD using Java.
Code:
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class flatMapEx{
public static void main(String[] args) {
// Spark configuration is done according to below code
SparkConf sparkConf = new SparkConf().setAppName("Text Reading")
.setMaster("local[2]").set("spark.executor.memory","2g");
// A context of Spark being started
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// A path for input text file is being provided
String path = "data/stringToWords/input_rdd/sample1.txt";
// A text file is read into RDD
JavaRDD<String> lines = sc.textFile(path);
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(s.split(" ")).iterator());
// RDD being collected for printing
for(String word:words.collect()){
System.out.println(word);
}
}
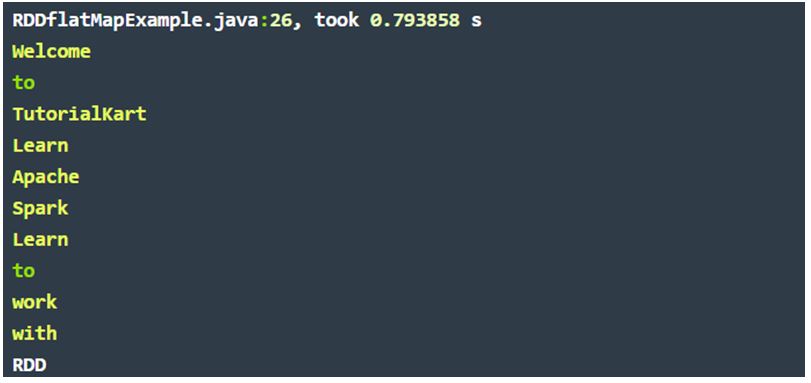
}sample1 – sample1.txt:
Welcome to TutorialKart
Learn Apache Spark
Learn to work with RDD
Output:
Example #2
String to words – An example in RDD using pyp – Python.
Code:
import sys
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
#Using Spark configuration, creating a Spark context
conf = SparkConf().setAppName("Read Text to RDD - Python")
sc = SparkContext(conf=conf)
#Input text file is being read to the RDD
lines = sc.textFile("https://cdn.educba.com/home/tutorialeducba/heythere/spark_rdd/sample1.txt")
#Each line to words conversion using flatMap
words = lines.flatMap(lambda line: line.split(" "))
#A list is made from the collection of RDD
list1 = words.collect()
#Printing of the above list1
for line in list1:
print linespark-submit is given below, which will be run for the above Python code.
Code:
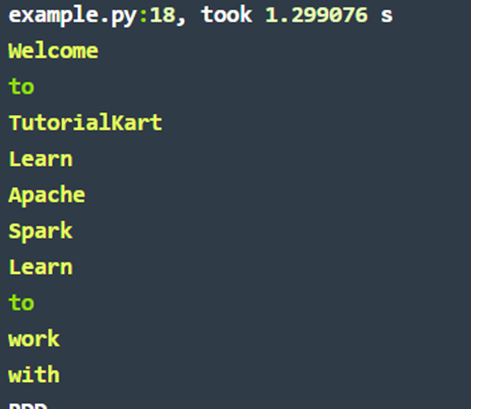
~$ spark-submit flatmap-spark-rdd-exp.pysample1 – sample1.txt:
Welcome to TutorialKart
Learn Apache Spark
Learn to work with RDD
Output:
Important points to be noted about transformation in flatMap Spark:
- Spark flatMap transformation provides flattened output.
- Lazy evaluation is done in this transformation due to the operation of Spark transformation.
- This parameter returns a list, a sequence, or an array.
Conclusion
We have seen the concept of Spark flatMap operation. Transformation operation expresses one-to-many operation transformations, which is a transformation of each element from zero to one, two, three, or more than those valued elements. In the operation of a flatMap, a developer can design his own business of logic custom.
Recommended Articles
This is a guide to Spark flatMap. Here we discuss how it works. along with examples respectively. You may also have a look at the following articles to learn more –
