
Introduction to Spark Thrift Server
Spark SQL Thrift server is a port of Apache Hive’s HiverServer2 which allows the clients of JDBC or ODBC to execute queries of SQL over their respective protocols on Spark. This is a standalone application that is used by starting start-thrift server.sh and ending it through a stop-thrift server.sh scripts of the shell. Also, it extends the command lines of spark-submit. Let us see how to use Spark as an SQL engine of cloud-base and also, exposing big data as ODBC or JDBC data source through the help of Spark Thrift Server.
How Spark Thrift Server in SQL Works
We can use Spark as an SQL engine of cloud-base and also, exposing big data as ODBC or JDBC data source through the help of Spark Thrift Server. Evolution of traditional database relational engines like SQL has been happening since due to their scalability problems and a couple of SQL frameworks of Hadoop like Cloudier Impala, Presto, Hive, etc. Frameworks like these are basically cloud-based solutions and each of those has its own limitations. These limitations will be listed further in the article below. Using the distributed SQL search engine, the spark, we can expose data in two forms. Those of which are – Permanent table and In-memory table. Let us dive in further.
In – memory table
In this type of data exposure, the in hive’s data storage of in-memory is in columnar format which is hive context and is scoped to the cluster. This makes it faster to access, therefore latency is lowered, Usage of Spark is done for memory caching.
Physical, Permanent memory
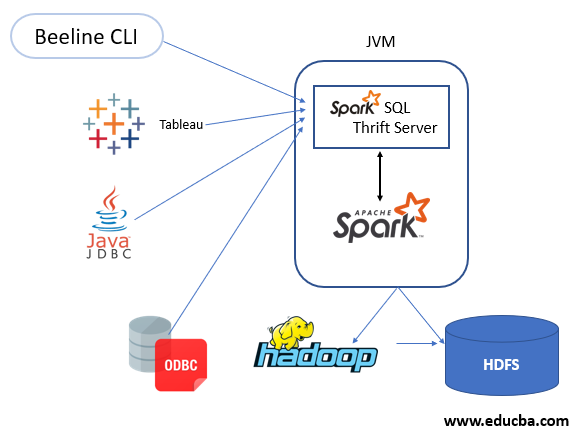
Using the Parquet format, data is stored in S3. Pushing data from multiple sources into the Spark and the expose as a table is one of the two methods mentioned above. In any of the two ways, these tables are made accessible as data sources – ODBC OR JDBC with the help of the Spark thrift server. There are multiple clients. Few of those are – CLI, Beeline, ODBC, JDBC, also a few business intelligence tools such as tableau. And visualization of data can be done by connecting these availabilities to thrift servers.
The below picture shows the above-mentioned illustration.
Spark Thrift server
Do you know HiveServer2 thrift?
Spark thrift server is highly familiar with Hive server2 thrift. However, there are differences such as MapReduce of hive job and were as Spark Thrift server uses SQL spark engine for search which is a main useful capability of spark.
The below mentioned are the different frameworks in SQL – on – Hadoop along with which are mentioned with their drawbacks.
| 1. Impala | YARN is not supported and the data input must be in the format parquet to completely use its benefits. |
| 2. Big SQL | This is a product of IBM and hence used only for IBM customers. |
| 3. Hive | Execution of MapReduce for the query execution and hence can be very slow. |
| 4. Apache drill | This is an interactive query of the SQL engine, which is open-source with a resemblance of impala. Stable release has been done years ago. This has more chances of not getting and becoming into an industry standard. |
| 5. Presto | The original hive creators built this framework that is, Facebook. This is a similar approach to Impala. Input must be given in file format. Debugging and deploying must be comforted first to adopt it for production later. |
Example to Implement Spark Thrift Server
Below is the example of mentioned:
The input is the source of an HDFS file and is registered as table records with the engine Spark SQL. The input can go with multiple sources. For example – few of the sources include XML, JSON, CSV, and others which are as complex as these in reality. Then to register the final data, we need to perform all kinds of aggregations and computations and then the final data registration is done with the Spark table.
Code:
//Here, a Spark session is created
val sparksess = SparkSession.builder()
.appName(“SQL spark”)
.config("hive.server2.thrift.port", “10000")
.config("spark.sql.hive.thriftServer.singleSession", true)
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
val records = sparksess.read.format(“username").load("here/input.username")
records.createOrReplaceTempView(“records")
spark1.sql("table drop records")
ivNews.write.saveAsTable("records")
The execution of the code can be done in two ways.
First one is bu using a Spark shell:
Giving the Spark shell command will give an interactive shell when you can run all the commands of spark. The below given is the spark-shell command:
spark-shell --conf spark.sql.hive.thriftServer.singleSession=true
By copying and pasting this above code will make you registered with your data
The second one is by using Spark submit:
Do a bundle of the above command line and make or create a file – jar out of that. And then, install mvn clean and build the jar file.
After downloading the repository paste the following code and run it.
//This can be local or nonlocal, It depends on where you run it.
spark-submit MainClass --master<master> <master_file_name_of_jar>
another way to get your data registered with a spark.
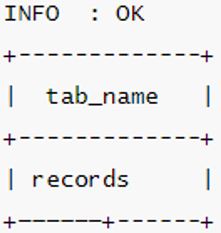
Now you have to make your data available to the world. And for this, the Spark automatically shows the tables which are registered as ODBC/JDBC through spark thrift server followed by accessing the data.
Output:
Conclusion
We have seen Spark Thrift SQL which was developed from Apache Hive on server 2 and also familiar in operating like the Hiveserver2 thrift server. This is supported by clusters of thrift. Later can be used with tools like Beeline command.
Recommended Articles
This is a guide to Spark Thrift Server. Here we discuss an introduction to Spark Thrift Server, how does it work, and programming example. You can also go through our other related articles to learn more –
