
Introduction to Search Algorithms in AI
Artificial Intelligence is the replication of human intelligence through computer systems or machines. It is done through acquiring knowledge or information and adding rules that information uses, i.e., learning, and then using these rules to derive conclusions (i.e., reasoning) and self-correction.
Properties of Search Algorithms
- Completeness: Consider a search algorithm complete when finding a solution for any input, given there’s at least one solution.
- Optimality: Suppose the algorithm whips up the best solution—with the lowest path cost. Well, then, we’ve hit the jackpot! That solution is what we call the optimal solution.
- Time and Space Complexity: Think of time complexity as how long it takes for an algorithm to finish its job. Space complexity? That’s all about the maximum storage space it needs during the search operation. To understand how search performance affects real-world ranking and visibility, you can use tools like the ai search visibility checker from Semrush. It helps evaluate how effectively your content appears in AI-driven search results
Types of Search Algorithms
There are two types of search algorithms explained below:
- Uninformed
- Informed
1. Uninformed Search Algorithms
Uninformed search algorithms do not have any domain knowledge. It works in a brute force manner, hence called brute force algorithms. It does not know how far the goal node is; all it knows is how to get around and tell the difference between a leaf node and a goal node. Every node is examined without prior knowledge; hence called a blind search algorithm.
Uninformed search algorithms are of mainly three types:
- Breadth-first search (BFS)
- Depth-first search (DFS)
- Uniform cost search
Breadth-First Search(BFS)
- We’re spreading out across the tree or graph when working with breadth-first search. We start at a node—we’ll call it the search key—and from there, we explore all its neighbors at the same depth. Once we’ve covered those, we level up and do it again. It is implemented using the queue data structure that works on the concept of first in first out (FIFO). It is a complete algorithm as it returns a solution if a solution exists.
- The time complexity for the breadth-first search is bd where b (branching factor) is the average number of child nodes for any given node and d is depth.
- The disadvantage of this algorithm is that it requires a lot of memory space because it has to store each level of nodes for the next one. It may also check duplicate nodes.
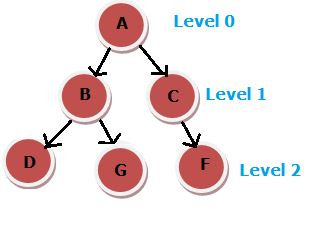
- Example: If the search starts from root node A to reach goal node G, it will traverse A-B-C-D-G. It traverses level-wise, i.e., explores the shallowest node first.
Depth First Search(DFS)
- We’re diving deep into the tree or graph when dealing with a depth-first search. We kick off from a node—let’s call it the search key—and explore all the nodes down the branch. Once we’ve done that, we backtrack and repeat it. We use a stack data structure to make this work. The key concept here? Last in first out (LIFO)
- The time complexity for the breadth-first search is bd where b (branching factor) is the average number of child nodes for any given node and d is depth.
- It stores nodes linearly hence less space requirement.
- The major disadvantage is that this algorithm may go in an infinite loop.
- Example: If the search starts from root node A to reach goal node G, it will traverse A-B-D-G. It traverses depth-wise, i.e., explores the deepest node first.
Uniform Cost Search
- Uniform cost search is different from both DFS and BFS. In this algorithm, the cost comes into the picture. There may be different paths to reach the goal, so the path with the least cost (cumulative sum of costs) is optimal. It traverses the path in the increasing order of cost. It is similar to the breadth-first search if the cost is the same for each transition.
- For a breadth-first search, we calculate the time complexity as bd. Here, ‘b’ stands for the branching factor – that’s the average number of child nodes per node – and ‘d’ stands for depth.

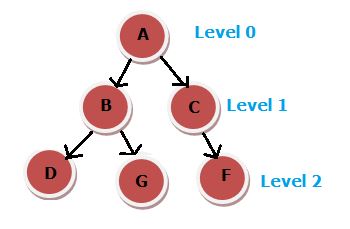
- Example: If the search starts from node A of the graph to reach goal node G, it will traverse A-C-G1. The cost will be 3.
2. Informed Search Algorithms
Informed search algorithms have domain knowledge. It contains the problem description and extra information like how far the goal node is. You might also know it as the Heuristic search algorithm. Although it might not always supply the best solution, it will do so in a timely manner. It can solve complex problems more efficiently than uninformed ones.
It is mainly of two types:
- Greedy Best First Search
- A* Search
Greedy Best First Search
In this algorithm, we expand the closest node to the goal node. The heuristic function h(x) roughly calculates the closeness factor. We expand or explore the node when f(n) equals h(n). We implement this algorithm using the priority queue. It is not an optimal algorithm. It can get stuck in loops.
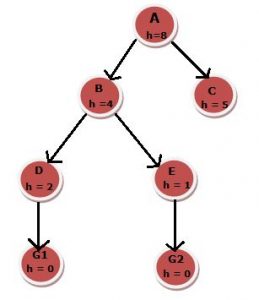
- Example: Let’s say we need to find the lowest-cost path from root node A to any goal state using greedy search. In that case, the solution turns out to be A-B-E-H. It will start with B because it has less cost than C, then E because it has less cost than D and G2.
A* Search
A* search is a combination of greedy search and uniform cost search. In this algorithm, we denote the total cost (heuristic) by f(x), summing the cost in uniform cost search represented by g(x) and the cost of the greedy search represented by h(x).
f (x) = g (x) + h (x)
In this, we define g(x) as the backward cost, which is the cumulative cost from the root node to the current node, and we define h(x) as the forward cost, which is the approximate distance between the goal node and the current node.
Conclusion
This article explains various artificial intelligence search algorithms in detail, using examples. AI is growing rapidly and acquiring the market, and search algorithms are an essential part of artificial intelligence.
Recommended Articles
This is a guide to Search Algorithms in AI. Here we discuss the introduction, properties, and types of search algorithms in AI. You may also have a look at the following articles to learn more –

