Updated March 17, 2023
Introduction to Scikit Learn Examples
In scikit learn examples, the scikit learn contains two types of learning, i.e., supervised learning and unsupervised learning. In supervised learning, data comes with additional attributes, including classification and regression. While developing an example using scikit learn, we first need to install the scikit learn in our system. It is also possible to use the 2d array using binary indicators in scikit learn.
Scikit is a library of machine learning used in python; it will contain multiple features like classification, regression, and clustering algorithms. Also, it will include the k-mean, random forests, DBSCAN, and gradient boosting algorithms. Scikit learn is designed to work with the library of numpy and pandas; it was written in python, and the core algorithm was written in a cython, an extension of python. Scikit learn is used for good performance and to build machine learning models; it was not recommended for manipulating and summarizing the data.

Key Takeaways
- When using scikit, we need to know the terminology of ml projects. Scikit learn is a tool that is well-documented and easy to use.
- Scikit learn contains a high-level library defining the predictive data model, which we can write in a few lines of code.
Examples of Scikit Learn
Given below are the Scikit Learn examples:
Example #1
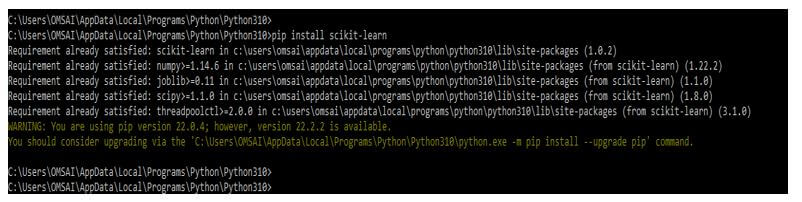
The below example shows we are installing the module of scikit learn by using the pip command. We can also install scikit learn by using other commands.
Code:
pip install scikit-learnOutput:
Example #2
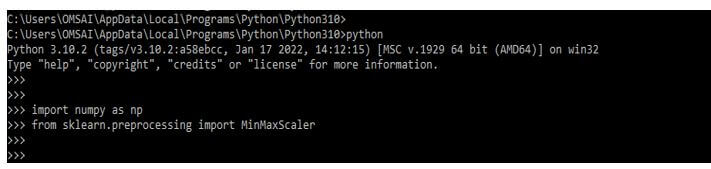
In the below example, we are importing the numpy and sklearn libraries as follows; we are importing the same by using the import keyword.
Code:
import numpy as np
from sklearn.preprocessing import MinMaxScalerOutput:
Example #3
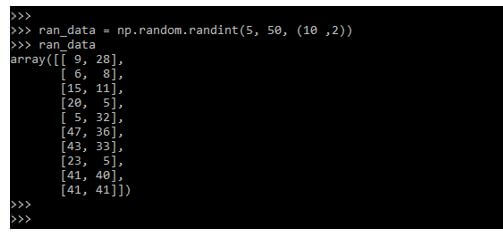
In the below example, we are generating the random data as follows. To generate the random data, we are using a random function.
Code:
ran_data = np.random.randint(5, 50, (10, 2))
ran_dataOutput:
Example #4
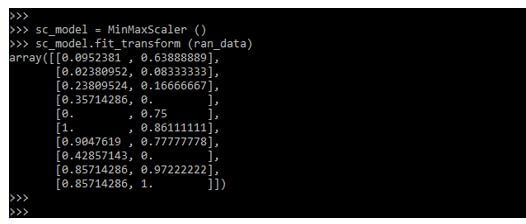
In the below example, we are transforming the data. We are creating the sc_model variable for changing the data as follows.
Code:
sc_model = MinMaxScaler ()
sc_model.fit_transform (ran_data)Output:
Example #5
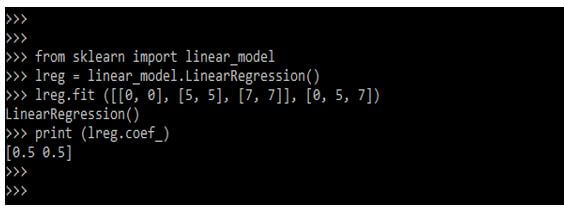
The example below defines the linear regression model in scikit learn as follows. The below dataset will fit into the three datasets for predicting the unknown data value, which was included in the existing data set as follows.
Code:
from sklearn import linear_model
lreg = linear_model.LinearRegression ()
lreg.fit ()
print (lreg.coef_)Output:
Example #6
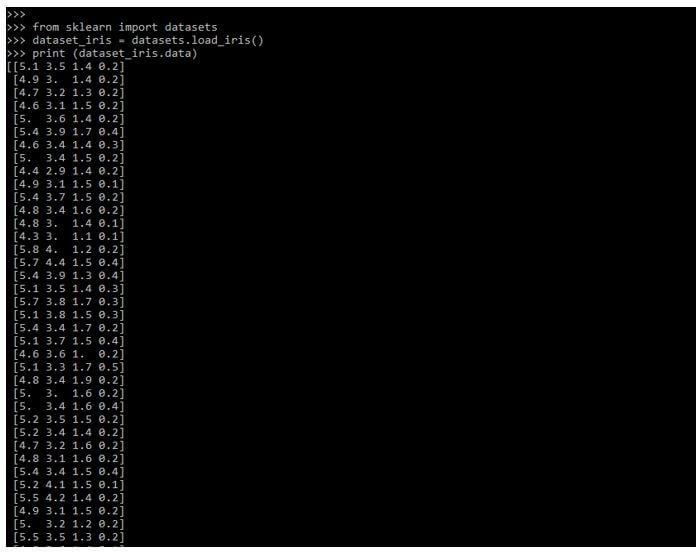
In the below example, we are loading the dataset name as iris dataset function as follows. We are importing the dataset library from the sklearn module.
Code:
from sklearn import datasets
dataset_iris = datasets.load_iris()
print (dataset_iris.data)Output:
Example #7
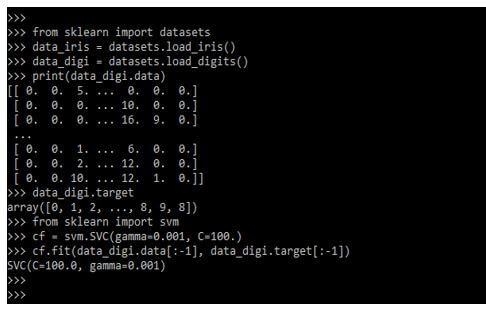
In the below example, we are loading the digits dataset and defining the svc. Also, we are importing the svm and datasets module as follows.
Code:
from sklearn import datasets
data_iris = datasets.load_iris()
data_digi = datasets.load_digits()
print (data_digi.data)
data_digi.target
from sklearn import svm
cf = svm.SVC (gamma=0.001, C=100.)
cf.fit (data_digi.data [:-1], data_digi.target [:-1])Output:
Example #8
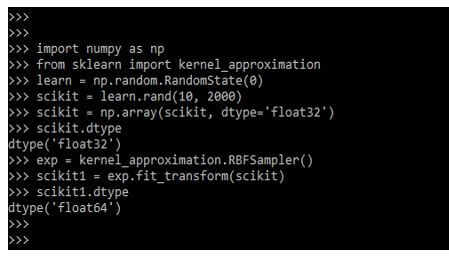
Scikit learns will estimators specific rules, making the behaviour more predictive as follows. The example below defines the random function for loading the data as follows.
Code:
import numpy as np
from sklearn import kernel_approximation
learn = np.random.RandomState(0)
scikit = learn.rand()
scikit = np.array (scikit, dtype='float32')
scikit.dtype
exp = kernel_approximation.RBFSampler()
scikit1 = exp.fit_transform(scikit)
scikit1.dtypeOutput:
Example #9
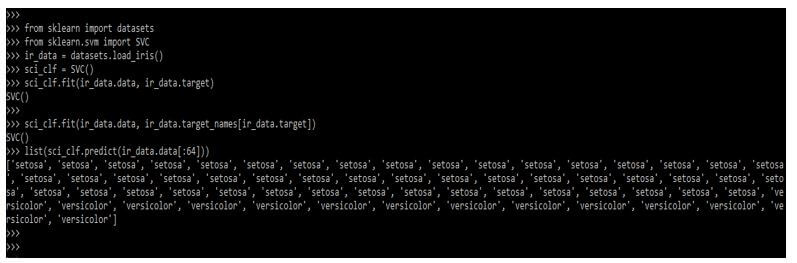
In the example below, regression targets are set to float64, and classification targets are maintained. In the below example, we are loading the iris dataset as follows.
Code:
from sklearn import datasets
from sklearn.svm import SVC
ir_data = datasets.load_iris()
sci_clf = SVC()
sci_clf.fit(ir_data.data, ir_data.target)
sci_clf.fit(ir_data.data, ir_data.target_names [ir_data.target])
list(sci_clf.predict(ir_data.data[:64]))Output:
Example #10
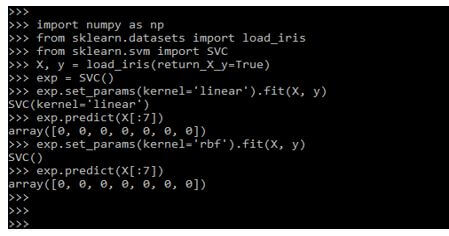
In the below example, we are updating and refitting the parameter as follows. The estimator hyperparameters are updated while constructed using the set_params () method. While calling the fit method, it will overwrite the previous method.
Code:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import SVC
X, y = load_iris(return_X_y=True)
exp = SVC()
exp.set_params (kernel='linear').fit(X, y)
exp.predict(X[:7])
exp.set_params(kernel = 'rbf').fit(X, y)
exp.predict(X[:7])Output:
Example #11
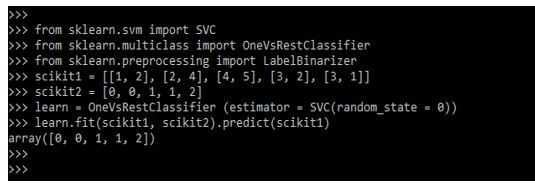
The below example shows a multi-class classifier in scikit learn as follows. The learning task depends on the target data format when using multi-class classifiers.
Code:
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import LabelBinarizer
scikit1 = [ ]
scikit2 = [ ]
learn = OneVsRestClassifier (estimator = SVC (random_state = 0))
learn.fit(scikit1, scikit2).predict (scikit1)Output:
Example #12
In the above example, we can see that classifier is fitted on a single array of the multi-class method by using predict method, and it provides the corresponding multi-class predictions. In the below example, we are using a 2d array as follows.
Code:
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import LabelBinarizer
scikit1 = [ ]
scikit2 = [ ]
scikit2 = LabelBinarizer().fit_transform (scikit2)
classif.fit (scikit1, scikit2).predict(scikit1)Output:
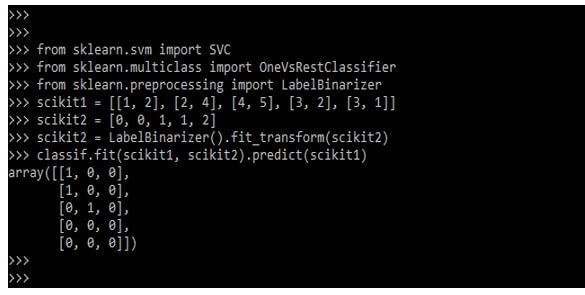
The above example classifier of the 2d array is scikit2; we represent the binary label using a label binarizer. In that case, the predictor will return the 2d array representing the Multilabel predictions.
FAQ
Other FAQs are mentioned below:
Q1. Which features are included in the scikit learn in python?
Answer:
Scikit learn is an open-source library that includes decision-making methods like clustering, classification, and regression. It will support analysis.
Q2. How do we define accuracy in scikit learn?
Answer:
The fraction of predictions was defined in the classification model. We define accuracy as a correct prediction divided by several examples.
Q3. In how many categories are we defining the example data?
Answer:
We define example data in two categories: labelled data and unlabeled data. Labelled data, including all the features.
Conclusion
Scikit learning is used for good performance and to build machine learning models; it was not recommended for manipulating and summarizing the data. In scikit learn examples, the scikit learn contains two types of learning, i.e., supervised learning and unsupervised learning.
Recommended Articles
This is a guide to Scikit Learn Examples. Here we discuss the introduction and examples of scikit learn for better understanding. You may also have a look at the following articles to learn more –
