Updated March 15, 2023

Introduction to Scikit Learn SVM
The following article provides an outline for Scikit Learn SVM. SVM is nothing but the set of supervised learning algorithms of machine learning, basically used for regression, classification, and detection. The SVM supports the learning method, which is used for high-dimensional spaces, and we can use it when we have several dimensions more significant than the size of samples. When we require high prediction accuracy compared to other classifiers or logistic regression, we can use SVM in scikit.
Support vector machines (SVMs) are robust yet adaptable managed AI techniques for order, relapse, and anomaly recognition. SVMs are highly effective in high layered spaces and, by and large, are utilized in characterization issues. SVMs are well-known and memory influential because they use a subset of preparing focuses in the choice capability.
The fundamental objective of SVMs is to partition the datasets into several classes to find the most extreme peripheral hyperplane (MMH), which should be possible in the accompanying two stages:
- Support Vector Machines will initially create hyperplanes iteratively that isolate the classes most effectively.
- After that, it will pick the hyperplane that separates the types accurately.
A few significant ideas in SVM are as per the following:
- Support Vectors: They might be the data points nearest to the hyperplane. Support vectors assist in choosing the isolating with coating.
- Hyperplane: The choice plane or space that partitions a set of items having various classes.
- Edge: The hole between two lines on the storeroom data of interest of multiple classes is called the edge.
How to Use Scikit Learn SVM?
Let’s see how we can use SVM in Scikit as follows. For implementation, we need to follow the different steps as follows. First, we need to import all required libraries as below:
Code:
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltIn the next step, we need to import a required dataset; if we have already downloaded it, then we need to download it as per our requirement.
Let’s assume we have already downloaded the dataset, so we need to use the code below:
Code:
sampledata= pd.read_csv(“required file path”)Now we need to write the code for data analysis. There are different ways to analyze the datasets with the help of various python libraries. For simplification, here, we can check only the dimensions of the data of the first few records and make the analysis.
Code:
sampledata.shapeIf we want to see the actual data then we need to use the below command as follows:
Code:
sampledata.head()Now everything is fine we need to process the data so we need to divide data into the different attributes and labels to create the trained dataset.
So to differentiate data we need to use the below code as follows:
Code:
X = sampledata.drop(‘Class’, axis =1)
Y = sampledata[‘Class’]When the information is partitioned into characteristics and names, the last preprocessing step is to separate data into preparing and test sets. Fortunately, the model_selection library of the Scikit-Learn library contains the train_test_split technique that permits us to isolate information into preparing and test sets flawlessly. We need to train the algorithm to use SVM on training data. Scikit-Learn contains the SVM library, which includes work in classes for various SVM calculations. Since we will play out a grouping task, we will utilize the help vector classifier class, composed of SVM in Scikit-Learn’s SVM library.
Now everything is ok, we need to make the prediction, so apply the prediction method of SVC as shown below code as follows:
Code:
prediction = svclassifier.predict(test_data)Now let’s see how we can evaluate algorithms, so we can use the Confusion matrix, and precision these are the most commonly used evaluation techniques.
So we can use the following code as follows:
Code:
from sklearn.metrics import classification_report, confusion_matrix
print()confusion matrix(tes_date, prediction)Finally, we can see the result.
Scikit Learn SVM of Classification
SVM supports the different types of classification as follows:
- LinearSVC: Basically, it is Linear Support Vector Classification. It provides the two options such as loss functions and penalties. Typically LinearSVC is used to handle a massive amount of data.
- NuSVC: This is nothing but the Nu Support Vector Classification. It is used to conduct the multiclass categorization; the working nature of NuSVC is the same as SVC.
- SVC: It is a C-based support vector classification and supports the multiclass support and the one-to-one mechanism used.
Classification of SVM that can perform binary and multiclass type on our database as shown in the below screenshot.
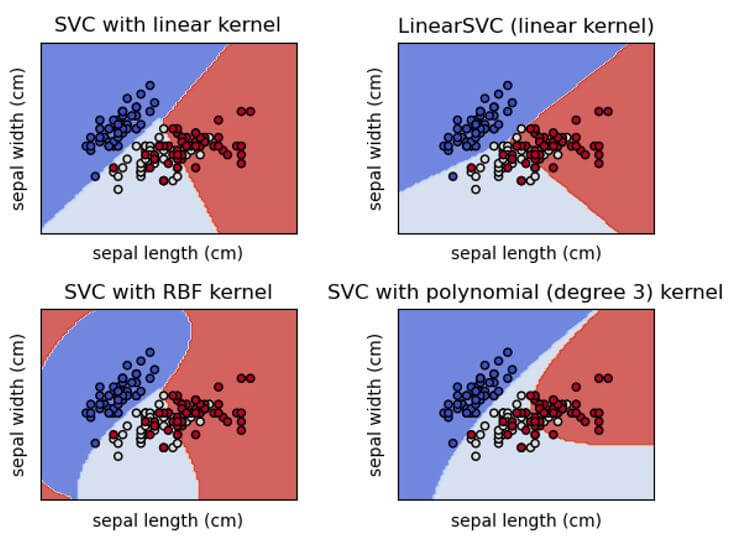
SVC and NuSVC are comparative strategies; however, they acknowledge various arrangements of boundaries and have different numerical plans (see segment mathematical definition). Then again, LinearSVC is another (quicker) execution of Support Vector Classification for the instance of a straight piece.
As well as it requires different parameters as follows:
- C: This is used to show the error.
- kernel: This is used to specify the type of kernel.
- degree: It shows the degree of the poly kernel function.
- gamma: The gamma is nothing but the kernel coefficient.
- coef0: This independent parameter is only associated with poly and sigmoid kernel types.
SVM also has many other parameters that we can use per the classification algorithm’s requirement.
Example of Scikit Learn SVM
Given below is the example of SVM with different classifications as follows:
Code:
import numpy as num
x_var = num.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y_var = num.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf_data = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf_data.fit(x_var, y_var)Explanation:
- In the above example, we are trying to implement the SVC classification, and the result is shown in the below screenshot.
Output:

Conclusion
In this article, we are trying to explore Scikit Learn SVM. In this article, we saw the basic ideas of Scikit Learn SVM and the uses and features of these Scikit Learn SVM. Another point from the report is how we can see the basic implementation of Scikit Learn SVM.
Recommended Articles
This is a guide to Scikit Learn SVM. Here we discuss the introduction, and how to use scikit learn SVM? classification and example respectively. You may also have a look at the following articles to learn more –
