Updated March 4, 2023

Introduction to Oracle hash join
In a hash join a hash table is created which is a technique used for joining two or more tables. Whenever the memory of the computer is made to set up at that time the best choice of the oracle’s optimizer is to use the hash join. Whenever we are joining two or more tables, the oracles optimizer selects the smallest table out of them and generates a hash table on that join using the join key for those tables. After that, the optimizer chooses the other remaining table which is usually a bigger one in that join for scanning, and then the hash table and that table are together probed to find the appropriate match.
Conditions for hash join to occur
The Oracle optimizer chooses hash join in a very efficient manner only when the parameter PGA_AGGREGATE_TARGET has a very large value which is sufficient enough to carry out the join. In case if we use a MEMORY_TARGET parameter, then the value of MEMORY_TARGET is added to the PGA_AGGREGATE_TARGET and together considered for hash join. But still, it is suggested to set both of the parameter values to the minimum necessary. Specification of SGA_TARGET does not include the value of parameter PGA_AGGREGATE_TARGET in it. Hence, even if the SGA_TARGET is set, you must also set the PGA_AGGREGATE_TARGET.
Whenever the nested loops join becomes inefficient because of the absence of a useful index then hash joins prove to be very efficient. There might be a situation when hash join can behave even faster than that of sort-merge join. Because in the case of the hash join probing different values of the hash table proves to be much faster than that of b- tree index traversing. Hash joins are useful only when there are equijoins. The working of hash join can become slow if the sort memory is not sufficient because if this happens then the hash joins to use the I/O services and memory resources of the temporary space for the tables. We can use the hash joins in oracle only when we use the cost-based optimization. This is the most frequent scenario that we have if our application is running on the Oracle 11g. The building of a hash table on one of the tables is the only affecting factor that contributes to the cost of hash join.
Example
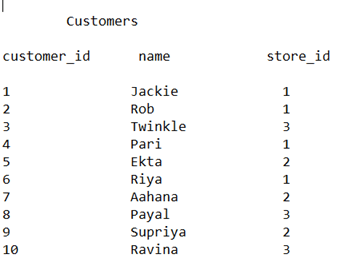
Consider that there are two tables named the customers and the stores. Both the tables are joined based on the join key named store id. The contents of the customers and stores table are as shown in the below image –
Customers Table –
Stores Table –

Suppose that the SQL query which is fired is as shown below on the table customers and stores on the join key store_id.
SELECT cust.name, store.store_id
FROM Stores AS stores
JOIN Customers AS cust
WHERE cust.store_id = store.store_id;
When the hash join is performed on the above-shown customer’s table and stores the table as the set of input then the oracle optimizer internally generates a hash table on the smaller table values. In this example, the hash table will be generated based on the join key which is store_id for the table customers in memory. Further, the optimizer takes every record of the customer’s table and probes for the matching value by comparing it to the hash table. All the records for the customer table are checked for the value in the store table.
For, each record in the store table all the records of the customer table are scanned and the loop continues till all the store records are completed for match and all the records are segregated. In the case of stores, the number of the loops that will be necessary to perform the hash join to sort will be for three times.
The first loop will find all the records of the customer’s table who have the store id as 1. The records retrieved after the first loop when the records are matched for the store is 1 are as shown below –

The second loop will segregate all the records of the customer’s table who will have the store id as 2. The records retrieved after the first loop when the records are matched for the store is 2 are as shown below –

Finally, the last scan will be made to find all the matching records with store id having value 3. The records retrieved after the first loop when the records are matched for the store is 3 are as shown below –

The fourth loop will not return any value because there were none of the records in the customer table with store id as 4.
When the hash table does not fit in the PGA area then the oracle optimizer uses the temporary space to accommodate the small portions of the hash table. These temporary space portions are also called partitions. Other than the hash table, some parts of the large table are also stored in partitions. The process includes the following steps followed by the oracle database’s algorithm.
It performs the complete scan on the smaller table which contains less number of the records compared to both the tables of join and stores the hash buckets in PGA as well as on disk. When the PGA area fills up then the biggest part of the hash table is chosen and stored in the temporary space of the disk. In this way, when the PGA area is not enough the data is stored in both the memory as well as the disk partition.
Conclusion
In the hash join technique whenever a join is performed in oracle in cost-based optimization manner a hash table is generated based on the join key on the smaller table. Further, all the records of the bigger table are scanned one by one to probe the matching values. This process continues for all the join key hash values. We have to be careful that the PGA variables are set to proper values to accommodate all the data of the hash tables.
Recommended Articles
This is a guide to Oracle hash join. Here we discuss the Conditions for hash join to occur along with the examples and outputs. You may also have a look at the following articles to learn more –
