Updated March 27, 2023
What is HDFS Federation?
HDFS Federation gives a way of separating the existing architecture having two layers called name layer and block storage layer. By doing this it enables to expand the architecture and enables the block storage layer. We can able to create more than one name node in a single cluster and maintain it easily as each name node will have its own namespace. HDFS Federation allows scalability of name node in the horizontal direction and multiple users can run their jobs using different name nodes and it overcomes the single point of failure.
HDFS Federation Architecture
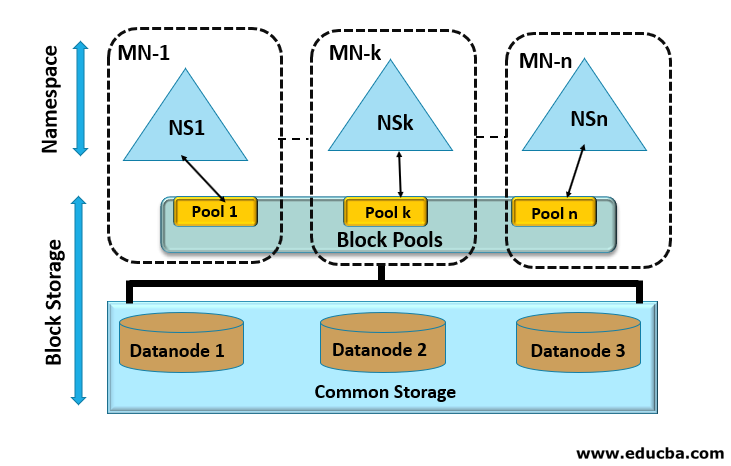
HDFS is a storage system to store large files and it is a file system for Hadoop which handles very large files. HDFS architecture follows legacy master/slave methodology where the master is name node and slaves are data nodes where name node stores the metadata with all the relevant information of data blocks, data, and data nodes. As the current architecture has a single point of failure as there is only a single name node or namespace which controls all the data nodes if it fails the entire system will be down. In order to overcome this issue, HDFS Federation architecture is introduced which is an enhanced version of existing HDFS architecture. It enhances the existing architecture by supporting multiple name nodes so that even one name node fails other nodes will come online so that the entire cluster will be available. As current HDFC architecture has limitations like namespace availability, isolation, tightly coupled namespace, and data node and performance. HDFS Federation uses multiple name nodes so that it can expand the namespace horizontally. In this architecture, all data nodes will be down having all the data of the name nodes. Data nodes send will send signals, reports, and heartbeats to the name nodes frequently. Each namespace has a set of blocks called block pool.
HDFS Federation has two components block pool and namespace and explained as below.
1. Block Pool
Each namespace in the architecture has a set of blocks in it called block pools. These are used to create block ID’s independently even with another namespace. Data node stores all the data blocks with block ids in the block pool in a cluster and each block pool is managed independently. As a result of even a name node failures, it doesn’t affect serving these data blocks. The combination of a data block and a name node is called namespace volume. If we delete the name node it will delete the block pools also and delete the data stored in the data nodes in the corresponding block pools. When a cluster is updated, the entire namespace will be updated once along with its block pools.
2. Namespace
The namespace is nothing but it is a name node that will have metadata like information of directories, files and blocks in the file system and it supports all types of file system operations related to namespace like create, delete, rename and listing of the files in directory and file system.
3. Block Storage Service
Block storage service is nothing but a combination of name node where block pool management is being done and the storage. It handles data node registration, heartbeats and other signals from it. It stores block information like logs, a location where it is stored and operations on blocks like create, delete, modify, location of a block, etc. It manages replication of a name node, block replication for blocks which are failed and deletion of over replicated blocks too. Storage: It is provided by the block pools which are being stored in Data nodes and provides I/O access to files and folders.
4. Cluster-ID
cluster-id is used to identify the nodes present in a single cluster based on the cluster id. The cluster-id is auto-generated or provided when a name node is formatted and used to format the name nodes into the cluster.
5. Configuration of Federation
Federation is designed in such a way that it can be backward compatible. Even with the enhanced architecture, it allows an old model of having a single name node without any changes in the configuration as the main idea of it is to don’t change the configuration based on types of name nodes in the cluster. So that no needs to do different configurations for different nodes in the cluster. We can configure by having NameServiceID which will have all the information of nodes and backup nodes in the form of parameters. In the first step, we need to add parameter dfs.nameservices and configure with the list of NameServiceIDs and it will be used by data nodes to determine the name nodes in the cluster. In the second step, we need to append the secondary/backup node for each name node as configuration parameters to the common configuration file suffixed with NameServiceID.
Benefits of HDFS Federation
HDFS Federation overcomes the limitations in HDFS architecture such as isolation, tightly coupled nature, high availability, and performance. Its main benefits are as below:
- Namespace scalability: In the federation, we can have more than one name node, so whenever a requirement arises it can be scalable horizontally by adding a namespace to the existing clusters.
- Isolation: It offers isolation when multiple name nodes are there. It won’t provide isolation when only a single name node is there but multiple users are there. So when multiple name nodes with multiple users and applications can be isolated to different namespaces according to the mapping.
- Performance: HDFS Federation offers provides I/O operations throughout the multiple name nodes hence performance increase as it is not limiting to single name node read/write operations.
Conclusion
Finally, it’s a wrapping of discussion regarding HDFS Federation architecture. We have discussed so many topics like why it came into the picture, what are its features or components, what are the benefits using this architecture over the existing architecture, how it overcomes the single point of failure etc. I hope you will have a better understanding and knowledge of where to apply, how to use and what are the benefits of HDFS Federation architecture after reading this article.
Recommended Articles
This is a guide to HDFS Federation. Here we discuss the introduction, HDFS Federation Architecture, Benefits of HDFS Federation. You can also go through our other suggested articles to learn more –
