Updated March 15, 2023
Difference between Hadoop and Redshift
Hadoop is an open-source framework developed by Apache Software Foundation with its main benefits of scalability, reliability, and distributed computing. Data processing, Storage, Access, and Security are several types of features available in the Hadoop Ecosystem. HDFS has a high throughput which means being able to handle large amounts of data with parallel processing capability. Redshift is a cloud hosting web service developed by the Amazon Web Services unit within Amazon.com Inc., Out of the existing services provided by Amazon. It is used to design a large-scale data warehouse in the cloud. Redshift is a petabyte-scale data warehouse service that is fully managed and cost-effective to operate on large datasets.
Let us study more about Hadoop and Redshift in detail:
Hadoop HDFS has high fault tolerance capability and was designed to run on low-cost hardware systems. Hadoop can handle a minimum type size of TeraBytes to GigaBytes of files within its system. HDFS is master-slave architecture consisting of Name Nodes and Data Nodes where the Name Node contains metadata and Data Node contains real data to be processed or operated.
RedShift uses different data loading techniques such as BI (Business Intelligence) reporting, analytical tools, and data mining. Redshift provides a console to create and manage Amazon Redshift clusters. The core component of the Redshift Data Warehouse is a cluster.
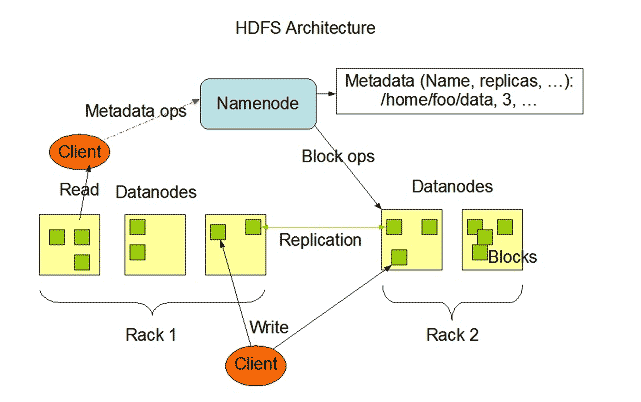
Image Source: Apache.org
RedShift Architecture:
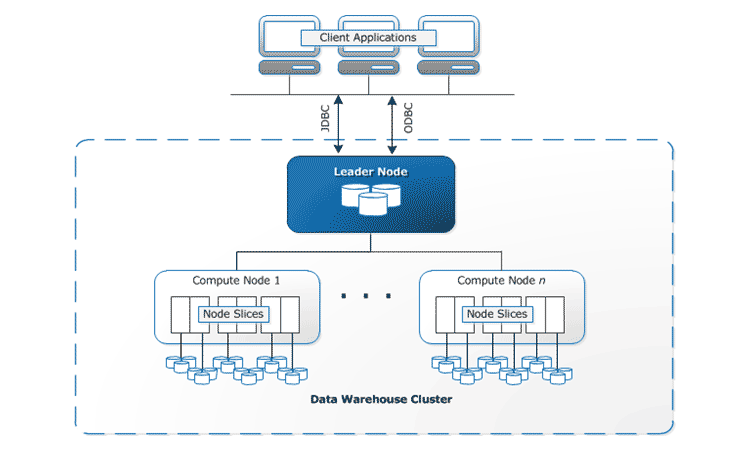 Image Source: Amazon.com
Image Source: Amazon.com
Head to Head Comparison between Hadoop and Redshift (Infographics):
Below is the top 10 comparisons between Hadoop and Redshift are as follows.

Key Differences Between Hadoop vs Redshift
Below is the Key Differences between Hadoop vs Redshift are as Follows
1. The Hadoop HDFS (Hadoop Distributed File System) Architecture is having Name Nodes and Data Nodes, whereas Redshift has Leader Node and Compute Nodes where Compute nodes will be partitioned as Slices.
2. Hadoop provides a command-line interface to interact with file systems whereas RedShift has a Management console to interact with Amazon storage services such as S3, DynamoDB etc.,
3. The database operations are to be configured by developers. Redshift automates the database operations by parsing the execution plans.
4. Hadoop has several third-party tools support to be integrated easily whereas Redshift supports only the products developed by Amazon in its cloud.
5. In terms of Hadoop architectural design, network, storage, security, and performance have been considered primary elements whereas in Redshift these elements can be easily and flexibly configured using Amazon cloud management console.
6. Hadoop is a File System architecture based on Java Application Programming Interfaces (API) whereas Redshift is based on a Relational model Database Management System (RDBMS).
7. Hadoop can have integrations with different vendors and Redshift has no support in this case where Amazon is their only vendor. What if a user is dissatisfied with the service? In this case, Hadoop is an advantage.
8. Most of the existing companies are still using Hadoop whereas new customers are choosing RedShift.
9. In terms of, performance Hadoop always lacks behind and Redshift always wins over in the case of query execution on large volumes of data.
10. Hadoop uses Map Reduce programming model for running jobs. Amazon Redshift uses Amazon’s Elastic Map Reduce.
11. Hadoop uses Map Reduce programming model for running jobs. Amazon Redshift uses Amazon’s Elastic Map Reduce.
12. Hadoop is preferable to run batch jobs daily that becomes cheaper whereas Redshift comes out cheaper in the case of Online Analytical Processing (OLAP) technology that exists behind many Business Intelligence tools.
13. Hadoop is 10 times slower than Redshift in running queries in a similar way Hadoop is 10 times costlier than Redshift resulting in Hadoop being the least chosen before Redshift.
14. In terms of Data Loading too, Hadoop has been behind Redshift in terms of hours taken by the system to load data from the storage into its file processing system.
15. Hadoop can be used for low-cost storage, data archiving, data lakes, data warehousing and data analytics whereas Redshift comes under Data warehouse capabilities causing to limiting the multi-purpose usage.
16. Hadoop platform provides support to various external vendors and its own Apache projects such as Storm, Spark, Kafka, Solr, etc., and on the other side Redshift has limited integration support with its only Amazon products
Hadoop vs Redshift Comparison Table
| BASIS FOR
COMPARISON |
HADOOP | REDSHIFT |
| Availability | Open Source Framework by Apache Projects | Priced Services provided by Amazon |
| Implementation | Provided by Hortonworks and Cloudera providers etc., | Developed and provided by Amazon |
| Performance | Hadoop MapReduce jobs are slower | Redshift performs more faster than Hadoop cluster |
| Scalability | Limitations in scalability | Easily be down/upsized as per requirement |
| Pricing | Costs $ 200 per month to run queries | The price depends on the region of the server and is cheaper than Hadoop
Eg: $20/month |
| Speed | Faster but slower compared to Redshift | 10 times faster than Hadoop |
| Query Speed | Takes 1491 seconds to run 1.2TB of data | 155 seconds to run 1.2TB data |
| Data Integration | Flexible with the local file system and any database | Can load data from Amazon S3 or DynamoDB only |
| Data Format | All data formats are supported | Strict in data formats such as CSV file formats |
| Ease of Use | Complex and trickier to handle administration activities | Automated backup and data warehouse administration |
Conclusion
The final statement to conclude the big winner in this comparison is Redshift that wins in terms of ease of operations, maintenance, and productivity whereas Hadoop lacks in terms of performance scalability and the services cost with the only benefit of easy integration with third-party tools and products. Redshift has been recently evolving with tremendous growth and acceptance by many customers and clients due to its high availability and less cost of operations compared to Hadoop makes it more and more popular. But, till now most of the existing Fortune 1000 companies have been using Hadoop platforms in its architectures to manage the customer data.
In most the cases RedShift has been the best choice to consider for the business purposes by any client or customer in order to handle the large and sensitive data of any financial institutions or public information with more data integrity and security.
Apart from this Hadoop has its own advantages being an open source project and had been available for many years also cause the existing systems to be replaced as a cost incurring process. The product should be finally chosen based on the requirement and flexibility rather than pricing or popularity based on the driven business needs.
Recommended Article:
This has been a guide to Hadoop vs Redshift, their Meaning, Head to Head Comparison, Key Differences, Comparision Table, and Conclusion. You may also look at the following articles to learn more –
