Updated June 12, 2023
Definition of Density-based Clustering
Density-based clustering is an unsupervised machine learning algorithm that groups similar data points in a dataset based on their density. The algorithm identifies core points with a minimum number of neighboring points within a specified distance (known as the epsilon radius). It expands clusters by connecting these core points to their neighboring points until the density falls below a certain threshold. Points that do not include any cluster are considered outliers or noise.
Key Takeaways
- The density-based algorithm requires two parameters, the minimum point number needed to form the cluster and the threshold of radius distance defines the neighborhood of every point.
- The commonly used density-based clustering algorithm known as DBSCAN groups data points that are close together and can discover clusters.
Background
“Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu introduced an unsupervised machine learning algorithm called density-based clustering in their 1996 paper ‘A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise.'” The algorithm, known as DBSCAN, was designed to handle large spatial databases with noise and to discover clusters of arbitrary shape.
The traditional clustering algorithms, such as k-means and hierarchical clustering, rely on the assumption that clusters are spherical or follow a specific shape and cannot handle irregularly shaped clusters. Density-based clustering overcomes this limitation by identifying dense regions of points and grouping them, regardless of their shape or size.
Key Concepts in Density-based Clustering
Here are some key concepts in density-based clustering:
- Local density: The idea of local density forms the basis of density-based clustering, which refers to the number of data points within a specified radius ε of a given data point. Density-based clustering classifies points with a high local density as part of a cluster, while it considers facts with a low local density as noise or outliers.
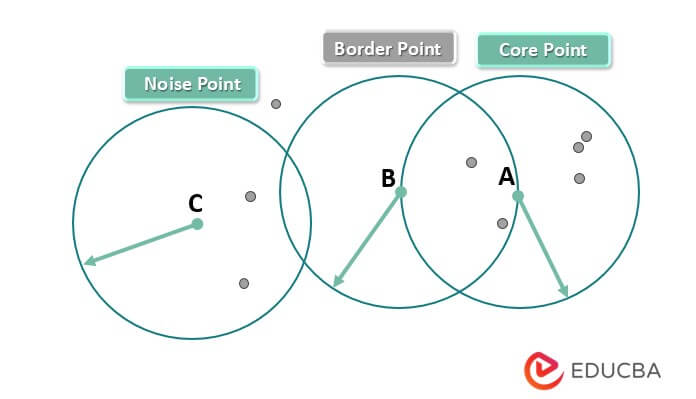
- Core points: Core points are data points with a minimum number of neighboring points within the specified radius ε. The algorithm considers core points as part of a cluster, and it follows a chain of neighboring points to connect other points to them.
- Border points: Border points are data points that are not core points but can be connected to a core point by following a chain of neighboring points. These points are considered part of the same cluster as the core points to which they are connected.
- Noise or outliers: Points that do not belong to any cluster and have no neighboring points within the specified radius ε are considered noise or outliers.
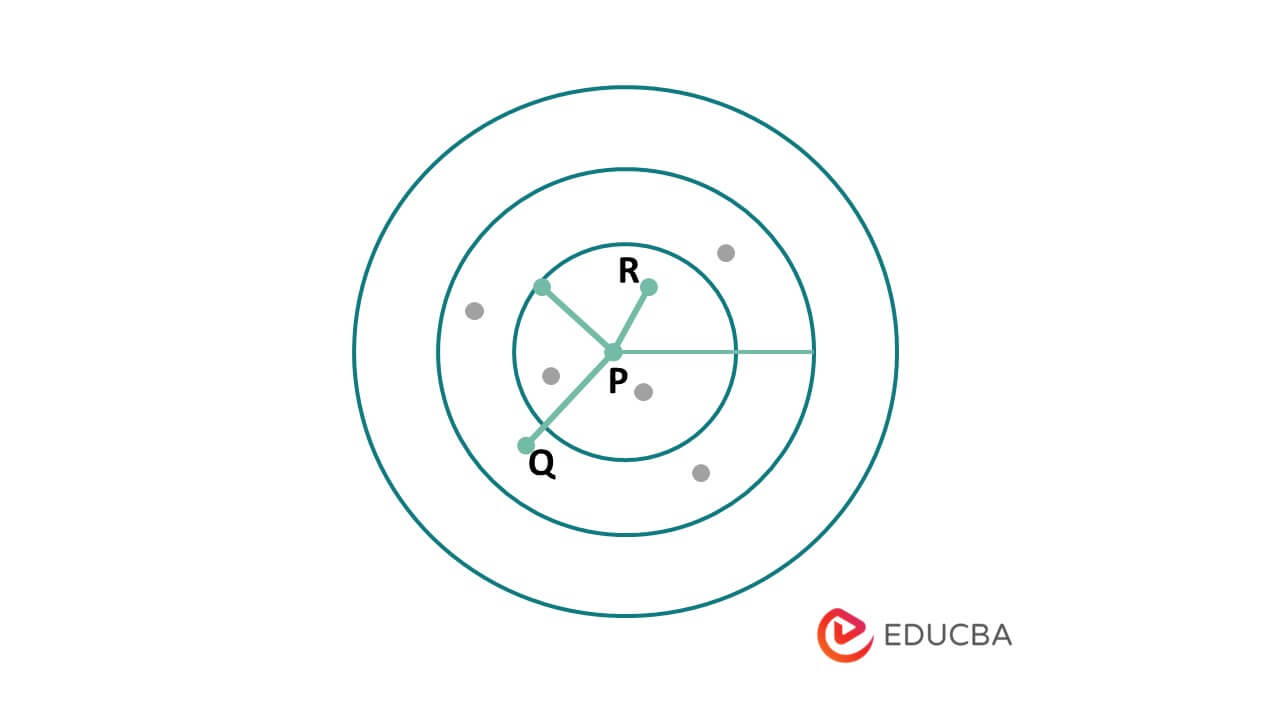
- Epsilon (ε) parameter: We use the ε parameter to determine the maximum distance between two data points considered part of the same cluster. It defines the neighborhood of a data point, typically set by the user based on the density of the dataset and the desired cluster size.
- Minimum points (MinPts) parameter: To be considered part of a cluster, a core point must have, at the very least, the minimum number of data points within its ε-neighborhood as specified by the MinPts parameter. This parameter helps filter out the noise and distinguish between core and border points.
- Density-reachable points: Density-reachable points are data points that are not core points but can still be reached by following a path of neighboring core points within the specified radius ε. These points are essential in expanding the clusters and determining their shape and size.
Parameters to Calculate the Density-based Clustering
Here are the formulas for the two parameters used to calculate density-based clustering:
1. Epsilon (ε):- We use the parameter ε to determine the maximum distance between two data points considered part of the same cluster. The parameter ε defines the neighborhood of a data point. The user typically sets the ε parameter based on the density of the dataset and the desired cluster size.
The formula for calculating ε is.
ε = k-distance, where k-distance is the distance to a data point’s nearest neighbor.
2. Minimum Points (MinPts):- The parameter MinPts specifies the minimum number of data points within the ε-neighborhood of a core point for it to be considered a part of a cluster. This parameter helps filter out the noise and distinguish between core and border points.
The formula for calculating MinPts is
MinPts = minimum number of data points required to form a dense region, as the user determines.
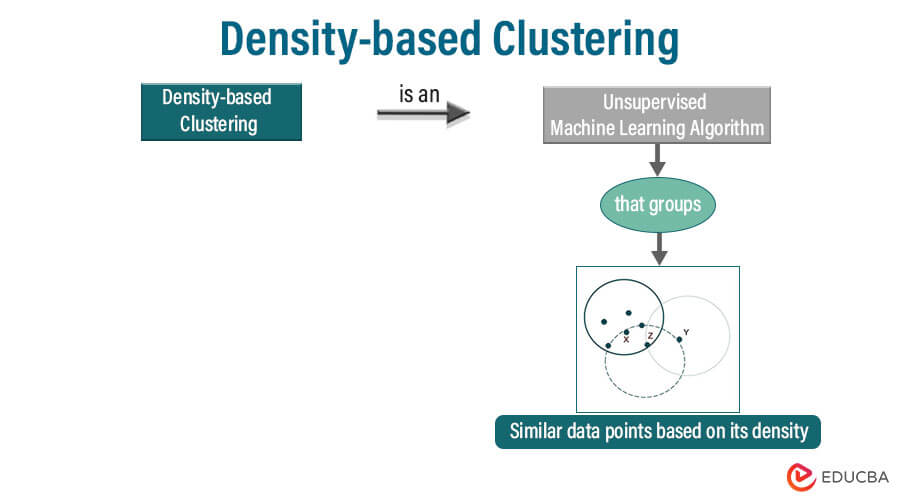
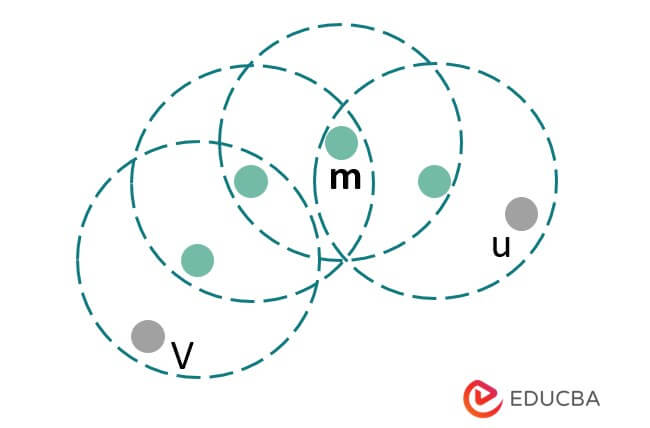
The above example shows density-based clustering. In the above example, the density-based clustering points are x, y, and z. Both points are density connected with each other.
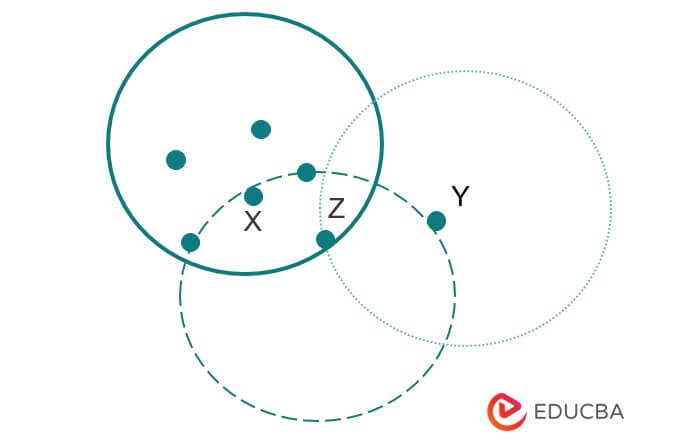
In the below example, we have defined three points. Also, in the below diagram, we have defined neighborhood points of x as follows.
It is the popular unsupervised learning methodology used in ML and model-building algorithms. Two clusters separate the data points in the region. The radius surroundings object is known as the neighborhood object. If neighborhood objects are comprised of the minimum number, they are called core objects.
It is used to identify the cluster datasets with distributions or by using noise points. This is commonly used in areas such as data mining and image processing; also, we can apply the same in a wide range of datasets.
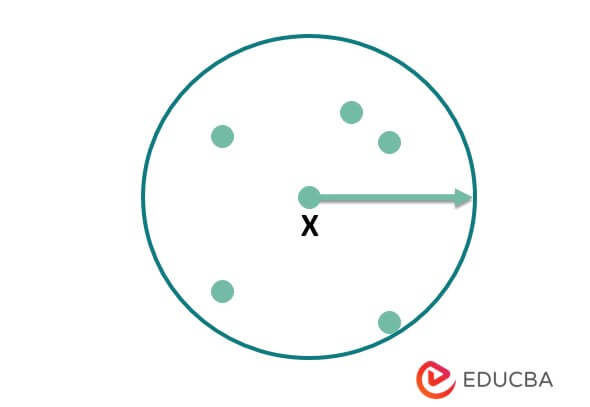
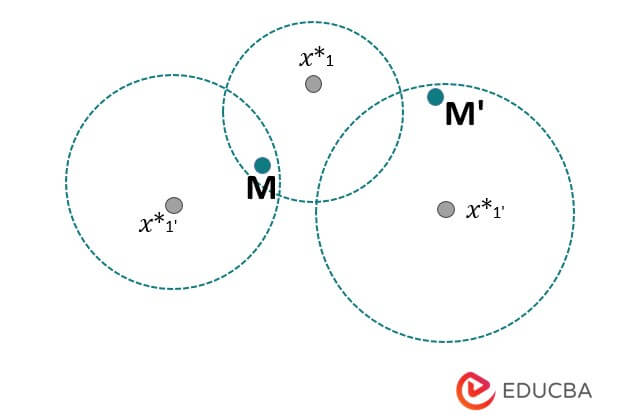
3. Density Reachable:- Point v is density reachable with point u with respect to Ep. If there is a sequence between u and v, it will meet at the point u1. The below example shows the density reachable as follows.
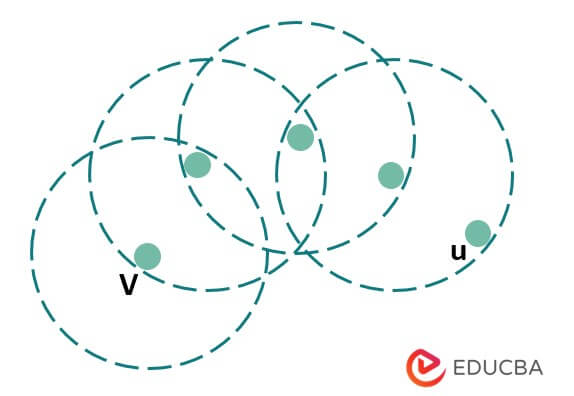
4. Density Connected:- The below example shows the density connected; in the following example, point u is density-connected to point v, and the points u and v are considered density-reachable with respect to the m points.
How does Density-Based Clustering work in Data Mining?
We use density-based clustering techniques to identify groups of similar objects in a dataset based on the feature space. This clustering technique aims to identify high-density regions separated by low-density regions. The most commonly used density-based algorithm is DBSCAN. DBSCAN algorithm works while selecting the number of points in the dataset, and it will also identify all the points with the radius from that specified point. We form a cluster if the number of points within the selected radius is greater than or equal to the specified radius.
DBSCAN continues to expand the cluster while including all the points that fall in the radius of any point within the cluster until we have not added any more points. After identifying all the points within a cluster, DBSCAN proceeds to the next unvisited point in the dataset and repeats the process until it visits all the points.
DBSCAN also identifies outlier points that do not belong to any other cluster, known as noise points. These points do not meet the cluster requirements because they are far away from the existing cluster or do not contain nearby neighbors. Using this technique, we can identify the cluster from the complex datasets.
Handling Noise and Outliers in Density-based Clustering
Handling noise and outliers is an essential aspect of density-based clustering. In density-based clustering, points that fall in low-density areas and do not belong to any cluster are considered noise or outliers. Here are some methods for handling noise and outliers in density-based clustering:
- DBSCAN:- The DBSCAN algorithm, the most widely used density-based clustering algorithm, has a built-in mechanism for controlling noise and outliers. The algorithm identifies noise points that do not belong to any cluster and ignores them in the cluster formation process.
- Outlier Detection:- Before applying density-based clustering algorithms, performing outlier detection to remove noisy data points can be helpful. Outlier detection algorithms, such as Local Outlier Factor (LOF) or Isolation Forest, identify and remove outliers from the dataset.
- Parameter Tuning:- In density-based clustering, the parameters ε and MinPts are crucial in identifying clusters and handling noise and outliers. Choosing appropriate values for these parameters can help to filter out noise and outliers and improve the quality of the clusters.
- Post-processing:- After running the clustering algorithm, it is possible to perform post-processing to identify and remove noisy clusters. For example, clusters containing a few points or low density can be considered noise and removed from the final output.
Applications of Density-based Clustering
It has a wide range of applications in various fields, including:
- Image Segmentation:- Image segmentation utilizes density-based clustering to partition an image into meaningful regions. Density-based clustering algorithms can segment images into visually distinct regions by clustering pixels based on color or texture similarity.
- Anomaly Detection:- Applying density-based clustering can help identify anomalies by detecting data points that exhibit significant deviations from the rest of the dataset. Clustering data points based on their density allows the identification of anomalies as data points that do not belong to any cluster or belong to a small, low-density cluster.
- Customer Segmentation:- Density-based clustering can be used for customer segmentation in marketing, where the goal is to group customers based on similar characteristics and behavior. By clustering customers based on their purchase history or demographic information, businesses can identify different customer segments and tailor their marketing strategies accordingly.
- Urban Planning:- Urban planners can use density-based clustering to identify different areas of a city based on their characteristics, such as population density, income level, and land use. By clustering areas based on similarities, urban planners can make informed decisions about zoning, transportation, and other urban development policies.
- Recommender Systems:- Density-based clustering can be used for building recommender systems, where the goal is to recommend products or services to users based on their past behavior. By clustering users based on their purchase history or browsing behavior, recommender systems can identify groups of users with similar preferences and recommend products or services that are relevant to them.
Advantages and Disadvantages
Advantages of Density-Based Clustering
- Density-based clustering algorithms can effectively handle noise and outliers in the dataset, making them robust in such scenarios.
- These algorithms can identify clusters of arbitrary shapes and sizes instead of other clustering algorithms that may assume specific forms.
- They don’t require prior knowledge of the number of clusters, making them more flexible and versatile.
- They can efficiently process large datasets and handle high-dimensional data.
Disadvantages of Density-Based Clustering
- The performance of density-based clustering algorithms is highly dependent on the choice of parameters, such as ε and MinPts, which can be challenging to tune.
- These algorithms may not be suitable for datasets with low-density regions or evenly distributed data points.
- They can be computationally expensive and time-consuming, especially for large datasets with complex structures.
- Density-based clustering can need help with identifying clusters of varying densities or scales.
Features of Density-Based Clustering
This clustering technique groups together data points that are close to each other based on density. Below are the features of density-based clustering as follows.
- It does not require specific clusters beforehand:- This clustering technique identifies the varying shapes, clusters, and sizes without requiring the number of users by limiting the number of clusters in advance. It will use the density parameter to determine which parameter belongs to the specified cluster.
- Handle outliers and noise:- This clustering technique handles datasets containing outliers and noise. Outlier is a point that is not part of any cluster.
- Identify varying density cluster:- This clustering technique identifies the varying density cluster. It uses a minimum density parameter that determines the minimum number of points required to form a cluster.
- Identify non-linearly separable clusters:- This technique can identify non-linearly separable clusters that other clustering techniques are missing.
- Efficient:- It is an efficient clustering technique, as it considers specific radius density points. So this technique handles large datasets and will also be scalable for high dimensions.
The density-based clustering is a flexible technique of clustering that can identify clusters of shapes and sizes and also will handle outliers and noise.
Methods of Density-based Clustering
The most widely used density-based clustering method is the DBSCAN (Density-Based Spatial Clustering of Applications with Noise) algorithm, introduced by Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu in 1996. However, there are other methods of density-based clustering as well, such as:
1. DBSCAN
Many people widely use this clustering algorithm. This algorithm is grouped together that is closely packed together, and also it will separate together from lower point density and areas. This algorithm will require two parameters. The first parameter, epsilon, defines the radius around each point, and the second parameter, minimum points, specify the minimum number of points needed to form a cluster. This algorithm starts by selecting unvisited points and finding all the points with an epsilon radius. If the number of points is less than the minimum, it will be labeled noise. If not, the algorithm labels this point as the core point and adds all points in the epsilon cluster to the cluster. Then, the algorithm repeats this process until it visits all the points. The below image shows DBSCAN clustering as follows.
2. OPTICS
This is another type of density-based clustering method; it is similar to the DBSCAN algorithms. This algorithm creates the plot of reachability, which shows the distance of neighboring points. This algorithm starts by selecting the random points and will find all the points from the epsilon radius. Then, the technique sorts these points based on distance reachability, the maximum distance a point can reach from a higher-density point. The below figure shows OPTICS clustering as follows.
3)DENCLUE
This clustering will represent density-based clustering. Its clustering approach depends on the function of density distributions. This algorithm uses the cluster model and will rely on kernel density estimation. The below figure shows the denclue algorithm as follows.
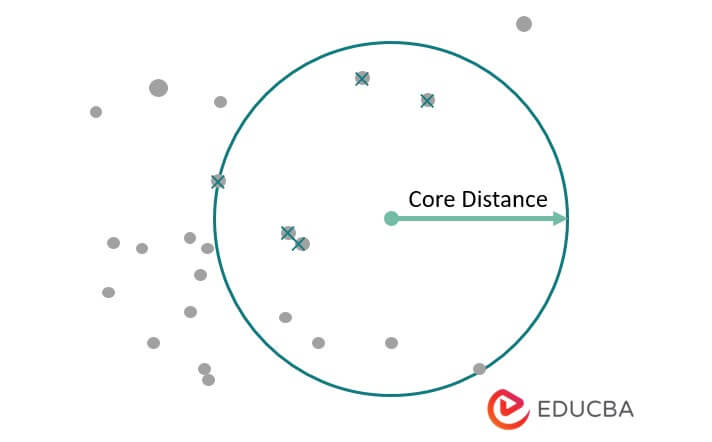
4)HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise)
This algorithm uses the range of distances to separate the cluster from the noise. This algorithm is a data-driven clustering algorithm, and it will require minimum user input. The below figure shows HDBSCAN as follows.
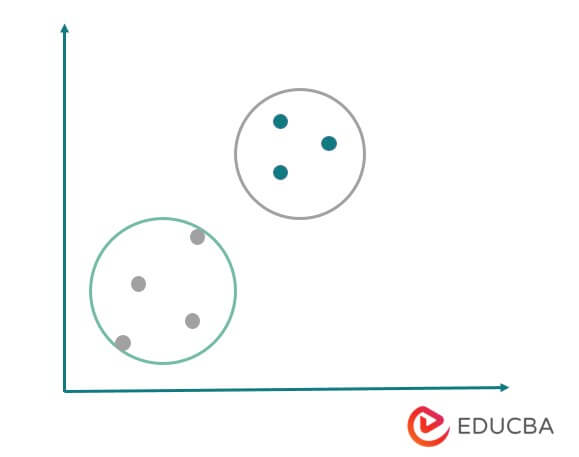
5)Mean Shift Clustering
This is a non-parametric clustering method based on the concept of mean shift. It works by assigning each data point to the nearest mode, which is the peak of the density function. The algorithm iteratively moves the data points toward the modes until convergence, forming clusters. In the below example, we can see that the point moved from one location to another. The below figure Mean shift clustering algorithm is as follows.
Conclusion
Density-based clustering techniques are widely used in data analysis and ML. It will identify the clusters with varying sizes and shapes. Two popular algorithms used in density-based clustering are DBSCAN and OPTICS. Density-based clustering does not require specifying the number of clusters in advance, which is its main advantage. Setting the appropriate value of a density parameter is a challenging task in density-based clustering.
FAQs
Q1. What are the applications of density-based clustering?
Answer: It contains a wide range of applications, which includes anomaly detection, image segmentation, and spatial analysis. People also use it in bioinformatics and other fields where clustering is necessary.
Q2. What is the difference between density-based clustering and other clustering techniques?
Answer: Density-based clustering differs from other clustering techniques, such as hierarchical clustering and k-means, in that it does not require a predetermined number of clusters.
Q3. Can density-based clustering handle high-dimensional data?
Answer: The density-based clustering technique handles high-dimensional data and is a scalable clustering technique.
