Updated March 16, 2023

Definition of Scikit Learn Clustering
Scikit learn clustering is a python learning method that was based on scipy which is released under the license of BSD. Scikit learn is mostly built on python and it will rely on the numpy for the linear algebra and array of high-speed operations. Scikit learn clustering technique allows us to find the groups of similar objects which was related to other than objects into other groups.
Overview of scikit learn clustering
The clustering of unlabeled data is performed by using sklearn.cluster module. The clustering algorithms comes in two variants the class which was implementing the fit method to learn the clusters on trained data and the function which was given in trained data which was returning the array of integer labels will correspond to the different clusters. The class labels for the training data are found in a labels attribute.
Scikit is mostly built on python and it will heavily rely on the numpy of high-speed array operations. The python wrapper around LIBSVM will implement the support for logistic regression and vector machines. It is not possible to implement this method by using python instances. Many of the other python libraries such as matplotlib, pandas and numpy are working well with scikit learn to cluster.
The scikit is an unsupervised ML method that was used to detect the association patterns and similarities across the data samples. The samples are clustered into groups based on the high degree of similarity features. Clustering is significant because it will ensure grouping under the unlabeled data. Clustering is defined as a method of sorting data points into different clusters which were based on similarity.
Key Takeaways
- The scikit learn clustering method is one of the ML methods which was unsupervised. This is used to find the relationship patterns.
- The scikit library contains the sklearn.cluster which was used to perform the clustering of unlabeled data. There are multiple clustering methods available for scikit learn.
Methods
The scikit library contains the function called sklearn cluster which was used to unlabeled the data. The below methods shows scikit learn clustering is as follows.
- Mean shift – This is used to find the blobs into sample density which was smooth. It will assign the data points to the cluster by moving the points to the cluster which contains higher density. It will set the number of clusters automatically rather than relying on any parameter.
- KMeans – The KMeans centroid is computed and iterated until we have not found the best centroid. It will necessitate the number of cluster specification which was presupposed. This algorithm’s primary concept is that cluster data which was reducing the inertia criteria, which was dividing samples into the number of groups in equal variances.
- Hierarchical clustering – This algorithm will create nested clusters by successively merging the clusters. The dendogram or tree will represent the cluster hierarchy.
- BIRCH – This stands for balanced iterative reducing clustering and hierarchy. This is a tool used for hierarchical clustering for huge data sets. As per the given data, it will create the tree called CFT.
- Spectral clustering – This clustering approach will execute the lesser number dimensionality reduction of dimensions by using Eigen values or spectrum of the similarity matrix. When there are multiple number of clusters then this is not recommended.
- Affinity propagation – The message passing idea between samples’ distinct pairs is used until converges. This is not necessary to provide the number of clusters prior to running the algorithm.
- Optics – It will stand for points of order which was used to identify the structure of cluster. In data that was spatial, this technique is finding the clusters which were density based. This cluster core logic is similar to the DBSCAN. While organizing the database points such as the closest it will become to the neighbor.
- DBSCAN – It is nothing but density-based spatial clustering applications by using noise it is an approach based on intuitive concepts. It will state that cluster is lower density than the regions which were dense. This clustering is performed by using the DBSCAN module.
Parameters
Below are the parameters of scikit clustering. These parameters are based on KMeans clustering.
- n_clusters – The data type of this parameter is int and the default value is 8. This will define the number of clusters which was formed.
- Init – The default value of this parameter is k-means++. This parameter is used in method initialization.
- n_init – The data type of this parameter is int and the default value is 10. This parameter defines the number of times the algorithm will run.
- max_iter – The data type of this parameter is int and the default value is 300. It will define the maximum iterations of the algorithm.
- tol – The data type of this parameter is float and the default value is 1e-4. This will define the relative tolerance regarding the forbenius norm of different clusters.
- Verbose – The data type of this parameter is int and the default value is 0. This parameter defines the verbosity mode.
- random_state – The data type of this parameter is int and the default value is none. This parameter determines the random number generation.
- copy_x – If this parameter is true then the original data is not modified.
- Algorithm – The default value of this parameter is llyod. The auto and full value is deprecated and removed from the version of scikit learn 1.3.
Examples of Scikit Learn Clustering
Below are the examples of scikit learn clustering. We are applying KMeans clustering to the digits dataset. This algorithm will identify the same digits.
Code:
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
scikit = load_digits()
scikit.data.shape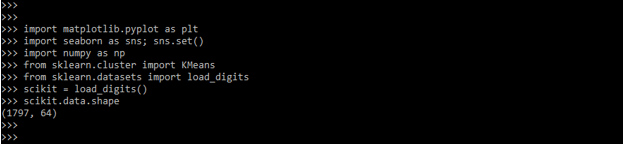
In the below example, we are performing the KMeans clustering as follows. We are defining a random state as zero.
Code:
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
scikit = KMeans(n_clusters = 12, random_state = 0)
clusters = scikit.fit_predict (digits.data)
scikit.cluster_centers_.shape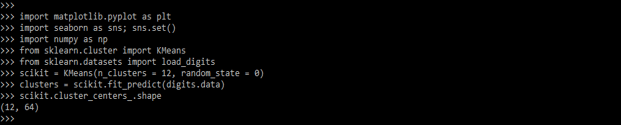
The below example shows that scikit learn clustering are as follows. This output shows cluster digits as follows.
Code –
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
from sklearn.metrics import accuracy_score
accuracy_score (digits.target, labels)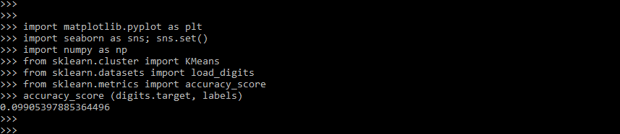
FAQ
1. What is the use of scikit learn clustering in python?
The Scikit clustering is used to perform the clustering on the unlabeled data. There are multiple types of methods available for clustering.
2. Which libraries do we need to use at the time of working with scikit learn clustering in python?
We need to use the seaborn, numpy, and matplotlib library at the time of working with seaborn learn clustering.
3. What is the use of KMeans clustering in Scikit learn clustering?
The KMeans algorithm will compute the centroids and iterate them until finding the optimal centroid point.
Conclusion
Scikit is mostly built on python and it will heavily rely on the numpy of high-speed array operations. Scikit learn clustering technique allows us to find the groups of similar objects which was related to other than objects into other groups.
Recommended Articles
This is a guide to Scikit Learn Clustering. Here we discuss the Definition, overview, method, parameters, examples, and FAQs. You may also have a look at the following articles to learn more –
