Updated May 24, 2023

Introduction to AWS EMR
The following article provides an outline for AWS EMR. Amazon EMR is a big data platform currently leading in cloud-native platforms for big data with its features like processing vast amounts of data quickly and at a cost-effective scale and all these by using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi and Presto, with the auto-scaling capability of Amazon EC2 and storage scalability of Amazon S3, EMR gives the flexibility to run short-lived clusters that can automatically scale to meet demand task, or for long-running highly available clusters.
AWS EMR provides many functionalities that make things easier for us; some of the technologies are:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
One of the major services provided by AWS EMR, and we will deal with, is Amazon EMR.
EMR, commonly called Elastic Map Reduce, comes with an easy and approachable way to process larger chunks of data. Imagine a big data scenario where we have a huge amount of data, and we are performing a set of operations over them, say a Map-Reduce job is running; Fine-tuning the program to ensure proper utilization of allocated resources is one of the major challenges faced by Big Data applications.
Due to this above tuning factor, the time taken for processing increases gradually. Amazon’s Elastic MapReduce is a web service that provides a cost-effective, fast, and secure framework managing all the necessary features required for Big Data processing. From cluster creation to data distribution over various instances, all these things are easily managed under Amazon EMR. Furthermore, the services here are on-demand, so we can control the numbers based on our data, making it cost-efficient and scalable.
Reasons for Using AWS EMR
So Why Use AMR? What makes it better than others? First, we often encounter a fundamental problem where we cannot allocate all the resources available over the cluster to any application; AMAZON EMR takes care of these problems. It gives the necessary resource based on the data’s size and the application’s demand. Also, being Elastic, we can change it accordingly.
Second, EMR has huge application support, be it Hadoop, Spark, or HBase, making it easier for Data processing. It supports various ETL operations quickly and cost-effectively. It can also be used for MLIB in Spark. We can perform multiple machine learning algorithms inside it. Be it Batch data or Real-Time Streaming of Data, EMR can organize and process both data types.
Working of AWS EMR
Let’s see this diagram of the Amazon EMR cluster and will try to understand how it works:
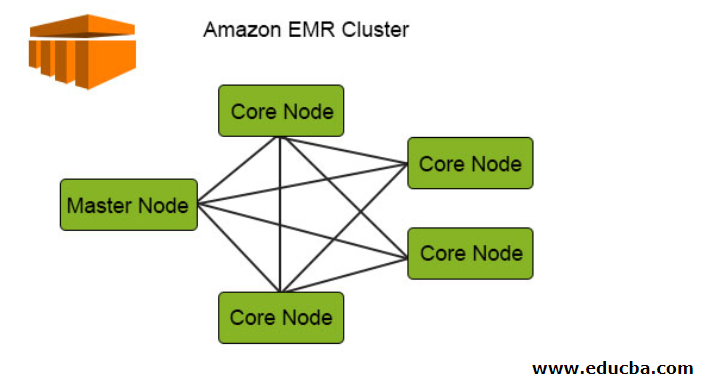
The following diagram depicts the cluster distribution inside EMR.
1. The Clusters are the central component in the Amazon EMR architecture. They are a collection of EC2 Instances called Nodes. Each node has its specific roles within the cluster termed as Node type, and based on their roles, we can classify them into 3 types:
- Master Node
- Core Node
- Task Node
2. The Master Node, as the name suggests, is the master responsible for managing the cluster, running the components, and distributing data over the nodes for processing. It keeps track of proper management, ensures smooth operation, and functions in case of failure.
3. The Core Node runs the task and stores the data in HDFS in the cluster. Additionally, the core Node handles all the processing parts and puts the processed data into the desired HDFS location.
4. The Task Node, being optional, only runs the task. This doesn’t store the data in HDFS.
5. Whenever submitting a job, we have several methods to choose how to complete the work. Being it from the cluster’s termination after job completion to a long-running cluster using EMR console and CLI to submit steps, we have all the privilege to do so.
6. We can directly Run the Job on the EMR by connecting it with the master node through the interfaces and tools available that run jobs directly on the cluster.
7. We can also run our data in various steps with the help of EMR; all we have to do is submit one or more ordered steps in the EMR cluster. The Data is stored as a file and is processed sequentially. Starting it from “Pending state to Completed state,” we can trace the processing steps and find the errors from ‘Failed to be Canceled’ all these steps can be easily traced back to this.
8. The completed state for the cluster is achieved once all instances have been terminated.
Architecture for AWS EMR
The architecture of EMR introduces itself, from the storage to the Application part.
- The first layer includes the storage layer, including different file systems used with our cluster. From HDFS to EMRFS to local file systems, these are all used for data storage over the entire application. These technologies that come with EMR enable the caching of intermediate results during MapReduce processing.
- The second layer comes with Resource Management for the cluster; this layer is responsible for resource management for the clusters and nodes over the application. This helps as the management tools that distribute the data over the cluster and proper managing. The Default resource Management tool EMR uses is YARN which was introduced in Apache Hadoop 2.0. It centrally manages the resources for multiple data processing frameworks. It handles all the information needed for the cluster well-running, from node health to resource distribution with memory management.
- The third layer comes with the Data processing Framework; this layer is responsible for analyzing and processing data. EMR supports many frameworks that are important in parallel and efficient data processing. Some of the framework it supports, and we are aware of, is APACHE HADOOP, SPARK, SPARK STREAMING, etc.
- The fourth layer includes the application and programs like HIVE, PIG, streaming library, and ML Algorithms that help process and manage large data sets.
Advantages of AWS EMR
Given below are the advantages mentioned:
- High Speed: Since all the resources are utilized properly, the query processing time is comparatively faster than the other data processing tools, with a much clearer picture.
- Bulk Data Processing: Be larger the data size EMR can process huge amounts of data in ample time.
- Minimal Data Loss: Since data are distributed over the cluster and processed parallelly over the network, there is a minimum chance for data loss, and the accuracy rate for the processed data is better.
- Cost-Effective: Being cost-effective, it is cheaper than any other alternative available, making it strong over industry usage. Since the pricing is less, we can accommodate large amounts of data and process them within budget.
- AWS Integrated: It integrates with all the services of AWS, making them easily accessible under one roof, thereby integrating security, storage, networking, and all other aspects in one place.
- Security: It has an amazing Security group to control the inbound and outbound traffic. Also, IAM Roles’ use makes it more secure as it comes up with various permissions that make data secure.
- Monitoring and Deployment: We have proper monitoring tools for all the applications running over EMR clusters, making it transparent and easy for the analysis portion. It also includes an auto-deployment feature that automatically configures and deploys the application.
There are many advantages to having EMR as a better choice than other cluster computation methods.
AWS EMR Pricing
EMR comes with a fantastic price listing that attracts developers or the market towards it. Since it comes with an on-demand pricing feature, we can use it just over an hourly basis and the number of nodes in our cluster. We can pay for a per-second rate for every second we use, with one minute as a minimum. We can choose between Reserved Instances or Spot Instances for our instances, with Spot Instances being a more cost-saving choice.
We can calculate the total bill over a simple monthly calculator from the below link:
https://calculator.s3.amazonaws.com/index.html#s=EMR
For more details on the exact pricing details, you can refer to the doc below by Amazon:
https://aws.amazon.com/emr/pricing/
Conclusion
The above article showed how EMR could be used for fair data processing with all the resources being utilized conventionally. Having EMR solves our basic data processing problem and reduces the processing time by a good number, being cost-effective. In addition, it is easy and convenient to use.
Recommended Articles
This is a guide to AWS EMR. Here we discuss the introduction, working of AWS EMR, architecture, and advantages. You can also go through our other suggested articles to learn more –

