Updated March 23, 2023

Introduction to Apache Flume
Apache Flume is Data Ingestion Framework that writes event-based data to Hadoop Distributed File System. It is a known fact that Hadoop processes Big data, a question arises how the data generated from different web servers is transmitted to Hadoop File System? The answer is Apache Flume. Flume is designed for high volume data ingestion to Hadoop of event-based data.
Consider a scenario where the number of web servers generates log files and these log files need to transmit to the Hadoop file system. Flume collects those files as events and ingests them to Hadoop. Although Flume is used to transmit to Hadoop, there is no rigid rule that the destination must be Hadoop. Flume is capable to write to other Frameworks like Hbase or Solr.
Flume Architecture
In general Apache Flume architecture is composed of the following components:
- Flume Source
- Flume Channel
- Flume Sink
- Flume Agent
- Flume Event
Let us take a brief look of each Flume component
1. Flume Source
A Flume Source is present on Data generators like Face book or Twitter. Source collects data from the generator and transfers that data to Flume Channel in the form of Flume Events. Flume supports various types of sources like Avro Flume Source—connects on Avro port and receives events from Avro external client, Thrift Flume Source- connects on Thrift port and receives events from external Thrift client streams, Spooling Directory Source, and Kafka Flume Source.
2. Flume Channel
An Intermediate Store that buffers the Events sent by Flume Source until they are consumed by Sink is called Flume Channel. Channel acts as an intermediate bridge between Source and Sink. Flume Channels are transactional in nature.
Flume provides support for the File channel and Memory channel. File channel is durable in nature that means once the data is written to channel it will be not lost, although if the agent restarts. In Memory, channel events are stored in memory, so it is no durable but very fast in nature.
3. Flume Sink
A Flume Sink is present on Data repositories like HDFS, HBase. Flume sink consumes events from Channel and stores them to Destination stores like HDFS. There is no rule such that the sink should deliver events to Store, instead, we can configure it in such a way that a sink can deliver events to another agent. Flume supports various sinks like HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
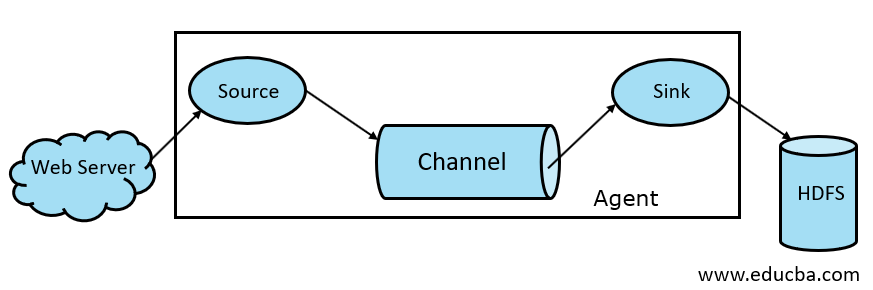
Fig 1.1 Basic Flume Architecture
4. Flume Agent
A Flume agent is a long-running Java process that runs on Source – Channel – Sink Combination. Flume can have more than one agent. We can consider Flume as a collection of connected Flume agents that are distributed in nature.
5. Flume Event
An Event is the unit of data transported in Flume. The general representation of the Data Object in Flume is called Event. The event is made up of a payload of a byte array with optional headers.
Working of Flume
A Flume agent is a java process that consists of Source – Channel – Sink in its simplest form. Source collects data from data generator in the form of Events and delivers it to Channel. A Source can deliver to multiple Channels as per requirement. Fan out is the process where a single source will write to multiple channels so that they can deliver to multiple sinks.
An Event is the basic unit of data being transmitted in Flume. Channel buffers the data until it is ingested by Sink. Sink collects the data from Channel and delivers it to Centralized data storage like HDFS or Sink can forward that events to another Flume agent as per requirement.
Flume supports Transactions. In order to achieve Reliability, Flume uses Separate Transactions from Source to Channel and from Channel to Sink. If events are not delivered, then the transaction is rolled back and later redelivered.
In order to understand the working of Flume, let us take an example of Flume configuration where the source is spooling directory and sink is Hdfs. In this example, the Flume agent is in the simplest form i.e. single source – channel – sink topology which is configured using a java properties file.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
In the above configuration example, the agent is the base with which we define other properties. source1 and sink1 and channel1 are the names of source, sink and channel respectively and their types and locations are also mentioned accordingly.
Advantages of Apache Flume
- Flume is scalable, reliable, and fault-tolerant in nature. These properties are discussed in detail below
- Scalable – Flume is scalable horizontally, i.e. we can add new nodes as per our requirement
- Reliable – Apache Flume has support for transactions and ensures that no data is lost in the process of data transmission. It has different transactions from source to channel and from channel to Source.
- Flume is customizable and provides support for various sources and sinks like Kafka, Avro, spooling directory, Thrift, etc.
- In Flume, a single source can transmit data to multiple channels and those channels in turn will transmit the data to multiple sinks, thus a single source can transmit data to multiple sinks. This mechanism is called Fan out. Flume also supports Fan out.
- Flume provides the steady flow of data transmission i.e. if data reading speed increases and then data writing speed also increases.
- Although Flume generally writes data to centralized storage like HDFS or Hbase, we can configure Flume as per our requirement such that Sink can write data to another agent. This shows the flexibility of Flume
- Apache Flume is open source in nature.
Conclusion
In this Flume article, components of Flume and working of Flume is discussed in detail. Flume is a Flexible, reliable, and scalable platform to transmit data to a centralized store like HDFS. Its ability to integrate with various applications like Kafka, Hdfs, Thrift make it a viable option for data ingestion.
Recommended Articles
This has been a guide to Apache Flume. Here we discuss architecture, working, and advantages of Apache Flume. You may also have a look at the following articles to learn more –

